 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECAP: Regression Evaluation for Continual Adaptation of Prompts
Jun 04, 2026Production agentic systems routinely face evolving constraints and must comply from the very next interaction. Scenarios like a tool-call notification changing a compliance threshold or a policy update adding disclosure requirements fit this criteria, having close to no room for errors in production. This proactive adaptation setting is common in deployment, but absent from current benchmarks, which assume either static constraint sets or reactive protocols with evaluation feedback. We introduce RECAP, a benchmark that measures continual-learning phenomena (forgetting, regression, forward transfer) at the constraint level under a strictly proactive adapt-then-test protocol: prompt optimization methods receive only the constraint specification and must generalize before seeing any test data. Evaluating six methods across four LLMs and three schedules with evolving constraints, we find that these methods show no significant improvement in performance, even after incurring a higher latency. These methods, designed for offline or reactive settings, are inadequate for the proactive paradigm. Our work emphasizes the growing need for designing proactive prompt adaptation methods, where the models must remain robust to evolving needs in deployment.
Contextual Bandits Evolving Over Finite Time
Nov 14, 2019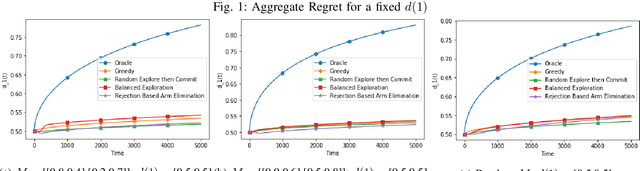

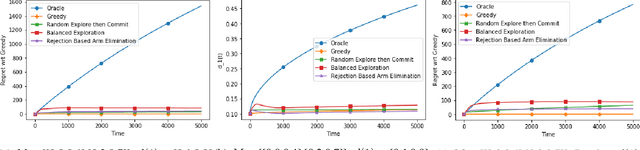
Contextual bandits have the same exploration-exploitation trade-off as standard multi-armed bandits. On adding positive externalities that decay with time, this problem becomes much more difficult as wrong decisions at the start are hard to recover from. We explore existing policies in this setting and highlight their biases towards the inherent reward matrix. We propose a rejection based policy that achieves a low regret irrespective of the structure of the reward probability matrix.
Stem-driven Language Models for Morphologically Rich Languages
Oct 25, 2019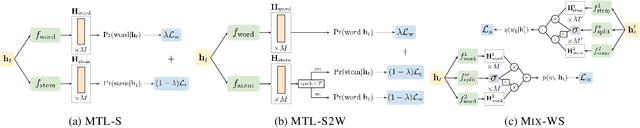
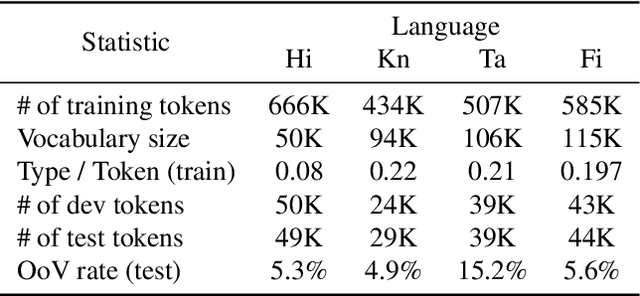
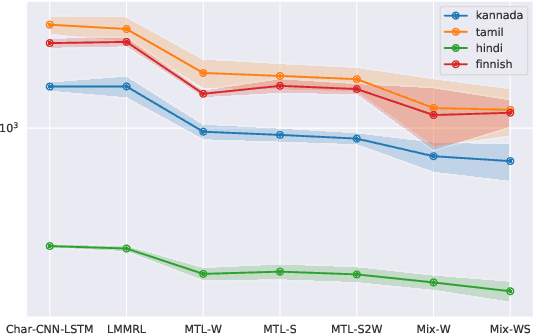
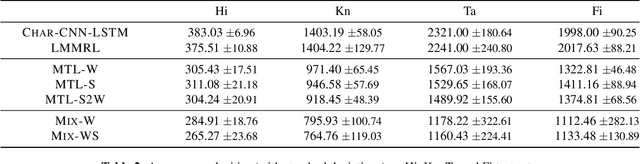
Neural language models (LMs) have shown to benefit significantly from enhancing word vectors with subword-level information, especially for morphologically rich languages. This has been mainly tackled by providing subword-level information as an input; using subword units in the output layer has been far less explored. In this work, we propose LMs that are cognizant of the underlying stems in each word. We derive stems for words using a simple unsupervised technique for stem identification. We experiment with different architectures involving multi-task learning and mixture models over words and stems. We focus on four morphologically complex languages -- Hindi, Tamil, Kannada and Finnish -- and observe significant perplexity gains with using our stem-driven LMs when compared with other competitive baseline models.