 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeq vs Seq: An Open Suite of Paired Encoders and Decoders
Jul 15, 2025The large language model (LLM) community focuses almost exclusively on decoder-only language models, since they are easier to use for text generation. However, a large subset of the community still uses encoder-only models for tasks such as classification or retrieval. Previous work has attempted to compare these architectures, but is forced to make comparisons with models that have different numbers of parameters, training techniques, and datasets. We introduce the SOTA open-data Ettin suite of models: paired encoder-only and decoder-only models ranging from 17 million parameters to 1 billion, trained on up to 2 trillion tokens. Using the same recipe for both encoder-only and decoder-only models produces SOTA recipes in both categories for their respective sizes, beating ModernBERT as an encoder and Llama 3.2 and SmolLM2 as decoders. Like previous work, we find that encoder-only models excel at classification and retrieval tasks while decoders excel at generative tasks. However, we show that adapting a decoder model to encoder tasks (and vice versa) through continued training is subpar compared to using only the reverse objective (i.e. a 400M encoder outperforms a 1B decoder on MNLI, and vice versa for generative tasks). We open-source all artifacts of this study including training data, training order segmented by checkpoint, and 200+ checkpoints to allow future work to analyze or extend all aspects of training.
How Grounded is Wikipedia? A Study on Structured Evidential Support
Jun 14, 2025Wikipedia is a critical resource for modern NLP, serving as a rich repository of up-to-date and citation-backed information on a wide variety of subjects. The reliability of Wikipedia -- its groundedness in its cited sources -- is vital to this purpose. This work provides a quantitative analysis of the extent to which Wikipedia *is* so grounded and of how readily grounding evidence may be retrieved. To this end, we introduce PeopleProfiles -- a large-scale, multi-level dataset of claim support annotations on Wikipedia articles of notable people. We show that roughly 20% of claims in Wikipedia *lead* sections are unsupported by the article body; roughly 27% of annotated claims in the article *body* are unsupported by their (publicly accessible) cited sources; and >80% of lead claims cannot be traced to these sources via annotated body evidence. Further, we show that recovery of complex grounding evidence for claims that *are* supported remains a challenge for standard retrieval methods.
Rank-K: Test-Time Reasoning for Listwise Reranking
May 20, 2025



Retrieve-and-rerank is a popular retrieval pipeline because of its ability to make slow but effective rerankers efficient enough at query time by reducing the number of comparisons. Recent works in neural rerankers take advantage of large language models for their capability in reasoning between queries and passages and have achieved state-of-the-art retrieval effectiveness. However, such rerankers are resource-intensive, even after heavy optimization. In this work, we introduce Rank-K, a listwise passage reranking model that leverages the reasoning capability of the reasoning language model at query time that provides test time scalability to serve hard queries. We show that Rank-K improves retrieval effectiveness by 23\% over the RankZephyr, the state-of-the-art listwise reranker, when reranking a BM25 initial ranked list and 19\% when reranking strong retrieval results by SPLADE-v3. Since Rank-K is inherently a multilingual model, we found that it ranks passages based on queries in different languages as effectively as it does in monolingual retrieval.
Rank1: Test-Time Compute for Reranking in Information Retrieval
Feb 25, 2025



We introduce Rank1, the first reranking model trained to take advantage of test-time compute. Rank1 demonstrates the applicability within retrieval of using a reasoning language model (i.e. OpenAI's o1, Deepseek's R1, etc.) for distillation in order to rapidly improve the performance of a smaller model. We gather and open-source a dataset of more than 600,000 examples of R1 reasoning traces from queries and passages in MS MARCO. Models trained on this dataset show: (1) state-of-the-art performance on advanced reasoning and instruction following datasets; (2) work remarkably well out of distribution due to the ability to respond to user-input prompts; and (3) have explainable reasoning chains that can be given to users or RAG-based systems. Further, we demonstrate that quantized versions of these models retain strong performance while using less compute/memory. Overall, Rank1 shows that test-time compute allows for a fundamentally new type of explainable and performant reranker model for search.
Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling
Oct 10, 2022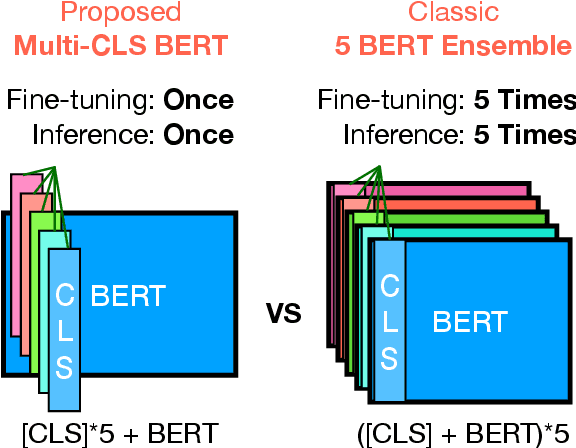
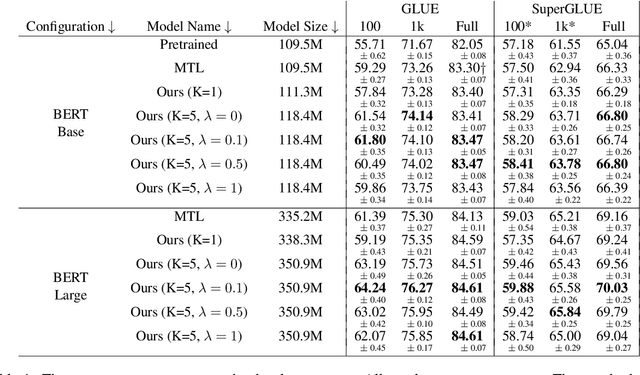

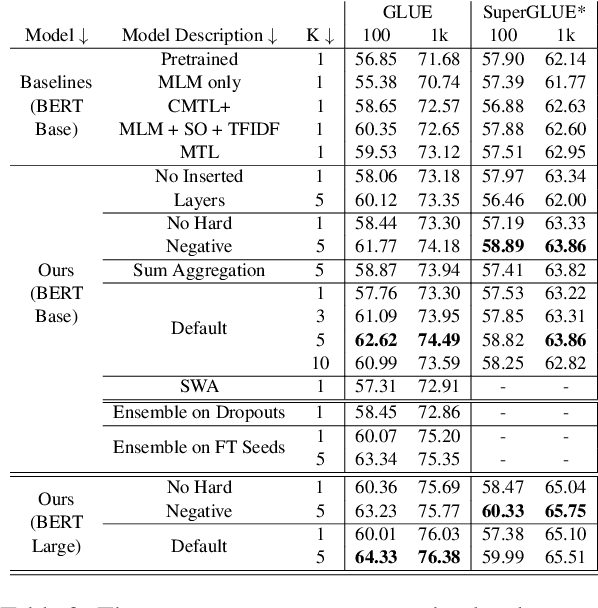
Ensembling BERT models often significantly improves accuracy, but at the cost of significantly more computation and memory footprint. In this work, we propose Multi-CLS BERT, a novel ensembling method for CLS-based prediction tasks that is almost as efficient as a single BERT model. Multi-CLS BERT uses multiple CLS tokens with a parameterization and objective that encourages their diversity. Thus instead of fine-tuning each BERT model in an ensemble (and running them all at test time), we need only fine-tune our single Multi-CLS BERT model (and run the one model at test time, ensembling just the multiple final CLS embeddings). To test its effectiveness, we build Multi-CLS BERT on top of a state-of-the-art pretraining method for BERT (Aroca-Ouellette and Rudzicz, 2020). In experiments on GLUE and SuperGLUE we show that our Multi-CLS BERT reliably improves both overall accuracy and confidence estimation. When only 100 training samples are available in GLUE, the Multi-CLS BERT_Base model can even outperform the corresponding BERT_Large model. We analyze the behavior of our Multi-CLS BERT, showing that it has many of the same characteristics and behavior as a typical BERT 5-way ensemble, but with nearly 4-times less computation and memory.