 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRQUGE: Reference-Free Metric for Evaluating Question Generation by Answering the Question
Nov 09, 2022Existing metrics for evaluating the quality of automatically generated questions such as BLEU, ROUGE, BERTScore, and BLEURT compare the reference and predicted questions, providing a high score when there is a considerable lexical overlap or semantic similarity between the candidate and the reference questions. This approach has two major shortcomings. First, we need expensive human-provided reference questions. Second, it penalises valid questions that may not have high lexical or semantic similarity to the reference questions. In this paper, we propose a new metric, RQUGE, based on the answerability of the candidate question given the context. The metric consists of a question-answering and a span scorer module, in which we use pre-trained models from the existing literature, and therefore, our metric can be used without further training. We show that RQUGE has a higher correlation with human judgment without relying on the reference question. RQUGE is shown to be significantly more robust to several adversarial corruptions. Additionally, we illustrate that we can significantly improve the performance of QA models on out-of-domain datasets by fine-tuning on the synthetic data generated by a question generation model and re-ranked by RQUGE.
Open Vocabulary Extreme Classification Using Generative Models
May 12, 2022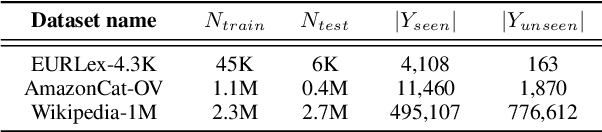
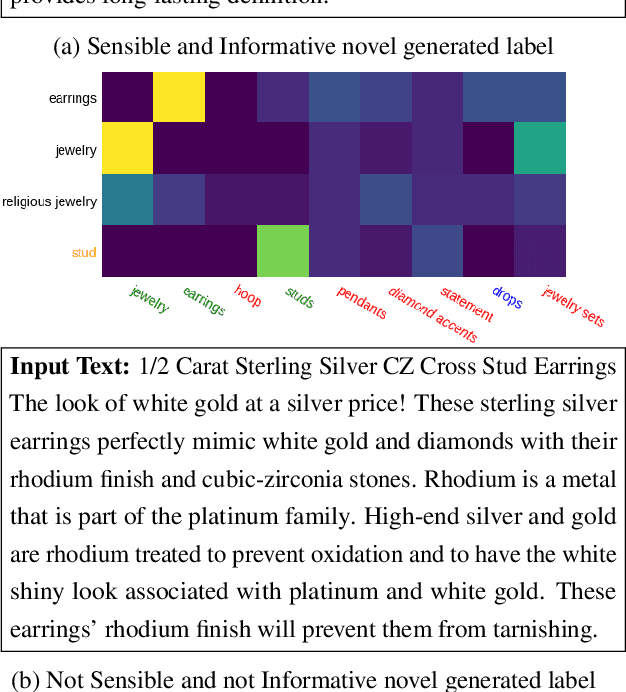
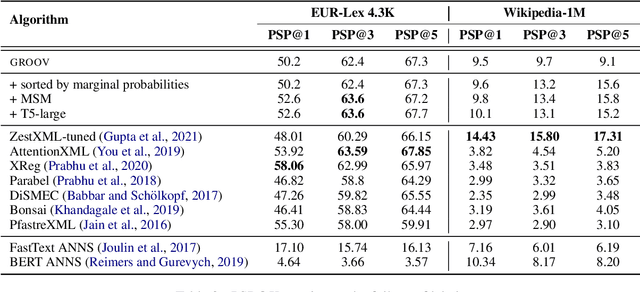

The extreme multi-label classification (XMC) task aims at tagging content with a subset of labels from an extremely large label set. The label vocabulary is typically defined in advance by domain experts and assumed to capture all necessary tags. However in real world scenarios this label set, although large, is often incomplete and experts frequently need to refine it. To develop systems that simplify this process, we introduce the task of open vocabulary XMC (OXMC): given a piece of content, predict a set of labels, some of which may be outside of the known tag set. Hence, in addition to not having training data for some labels - as is the case in zero-shot classification - models need to invent some labels on-the-fly. We propose GROOV, a fine-tuned seq2seq model for OXMC that generates the set of labels as a flat sequence and is trained using a novel loss independent of predicted label order. We show the efficacy of the approach, experimenting with popular XMC datasets for which GROOV is able to predict meaningful labels outside the given vocabulary while performing on par with state-of-the-art solutions for known labels.