 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Matching for Low-Resource Classification
Jun 01, 2020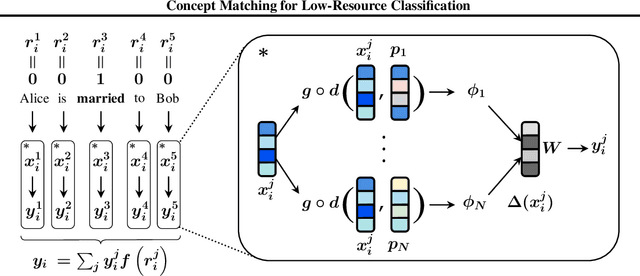


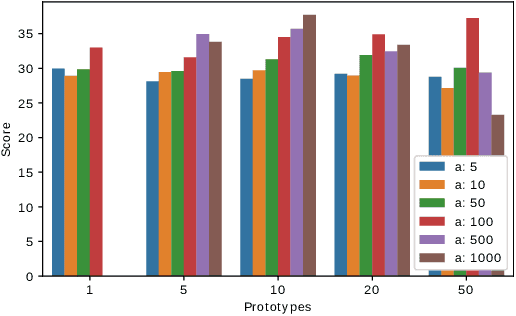
We propose a model to tackle classification tasks in the presence of very little training data. To this aim, we approximate the notion of exact match with a theoretically sound mechanism that computes a probability of matching in the input space. Importantly, the model learns to focus on elements of the input that are relevant for the task at hand; by leveraging highlighted portions of the training data, an error boosting technique guides the learning process. In practice, it increases the error associated with relevant parts of the input by a given factor. Remarkable results on text classification tasks confirm the benefits of the proposed approach in both balanced and unbalanced cases, thus being of practical use when labeling new examples is expensive. In addition, by inspecting its weights, it is often possible to gather insights on what the model has learned.
Misspelling Oblivious Word Embeddings
May 23, 2019
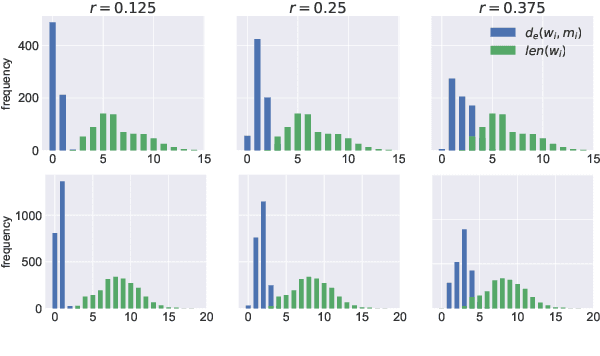

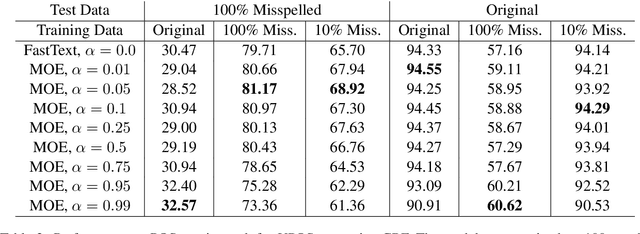
In this paper we present a method to learn word embeddings that are resilient to misspellings. Existing word embeddings have limited applicability to malformed texts, which contain a non-negligible amount of out-of-vocabulary words. We propose a method combining FastText with subwords and a supervised task of learning misspelling patterns. In our method, misspellings of each word are embedded close to their correct variants. We train these embeddings on a new dataset we are releasing publicly. Finally, we experimentally show the advantages of this approach on both intrinsic and extrinsic NLP tasks using public test sets.
Deep Character-Level Click-Through Rate Prediction for Sponsored Search
Jul 07, 2017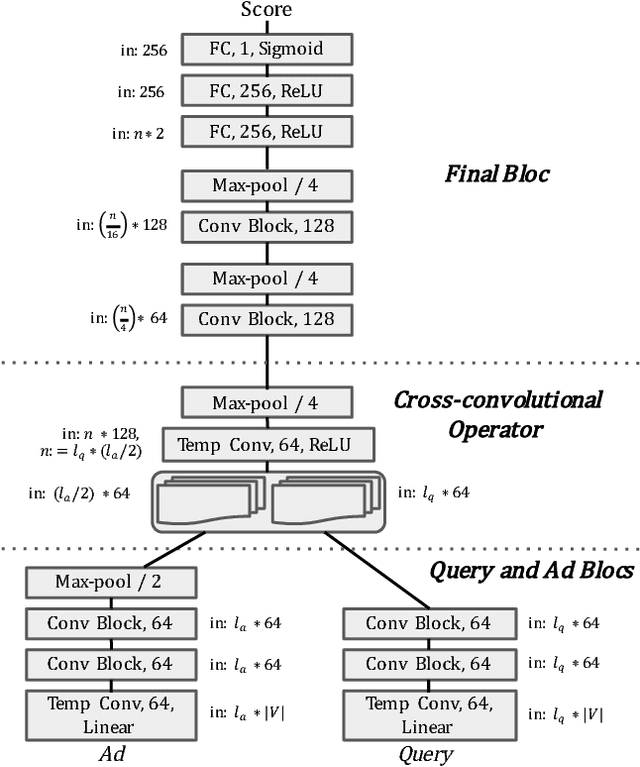
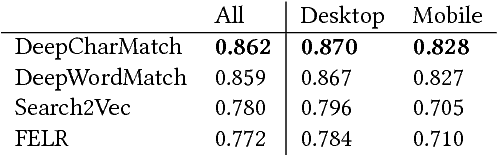


Predicting the click-through rate of an advertisement is a critical component of online advertising platforms. In sponsored search, the click-through rate estimates the probability that a displayed advertisement is clicked by a user after she submits a query to the search engine. Commercial search engines typically rely on machine learning models trained with a large number of features to make such predictions. This is inevitably requires a lot of engineering efforts to define, compute, and select the appropriate features. In this paper, we propose two novel approaches (one working at character level and the other working at word level) that use deep convolutional neural networks to predict the click-through rate of a query-advertisement pair. Specially, the proposed architectures only consider the textual content appearing in a query-advertisement pair as input, and produce as output a click-through rate prediction. By comparing the character-level model with the word-level model, we show that language representation can be learnt from scratch at character level when trained on enough data. Through extensive experiments using billions of query-advertisement pairs of a popular commercial search engine, we demonstrate that both approaches significantly outperform a baseline model built on well-selected text features and a state-of-the-art word2vec-based approach. Finally, by combining the predictions of the deep models introduced in this study with the prediction of the model in production of the same commercial search engine, we significantly improve the accuracy and the calibration of the click-through rate prediction of the production system.