 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinBert: Binary Code Understanding with a Fine-tunable and Execution-aware Transformer
Aug 13, 2022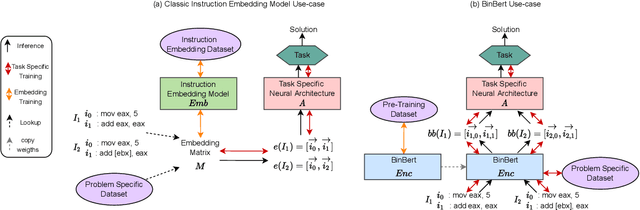

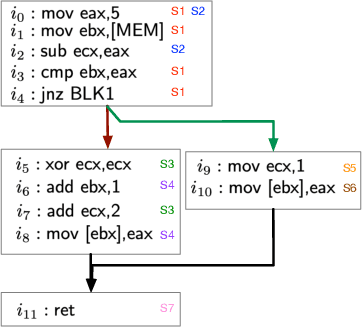
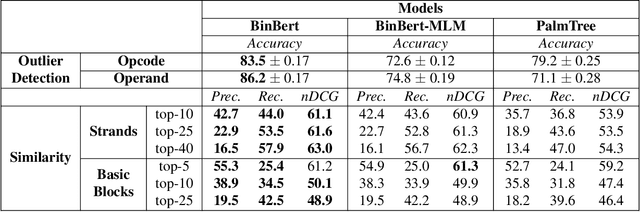
A recent trend in binary code analysis promotes the use of neural solutions based on instruction embedding models. An instruction embedding model is a neural network that transforms sequences of assembly instructions into embedding vectors. If the embedding network is trained such that the translation from code to vectors partially preserves the semantic, the network effectively represents an assembly code model. In this paper we present BinBert, a novel assembly code model. BinBert is built on a transformer pre-trained on a huge dataset of both assembly instruction sequences and symbolic execution information. BinBert can be applied to assembly instructions sequences and it is fine-tunable, i.e. it can be re-trained as part of a neural architecture on task-specific data. Through fine-tuning, BinBert learns how to apply the general knowledge acquired with pre-training to the specific task. We evaluated BinBert on a multi-task benchmark that we specifically designed to test the understanding of assembly code. The benchmark is composed of several tasks, some taken from the literature, and a few novel tasks that we designed, with a mix of intrinsic and downstream tasks. Our results show that BinBert outperforms state-of-the-art models for binary instruction embedding, raising the bar for binary code understanding.
Function Naming in Stripped Binaries Using Neural Networks
Dec 17, 2019
In this paper we investigate the problem of automatically naming pieces of assembly code. Where by naming we mean assigning to portion of code the string of words that would be likely assigned by an human reverse engineer. We precisely define the framework in which our investigation takes place. That is we define problem, we provide reasonable justifications for the choice that we made during our designing of the training and test steps and we performed a statistical analysis of function names in a large real-world corpora of over 4 millions of functions. In such framework we test several baselines coming from the field of NLP.