 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Skeleton-based Action Recognition via Mutual Information Estimation and Maximization
Paper and Code
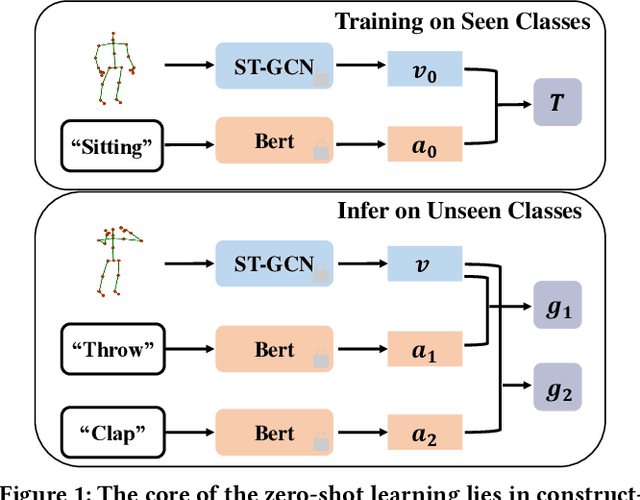
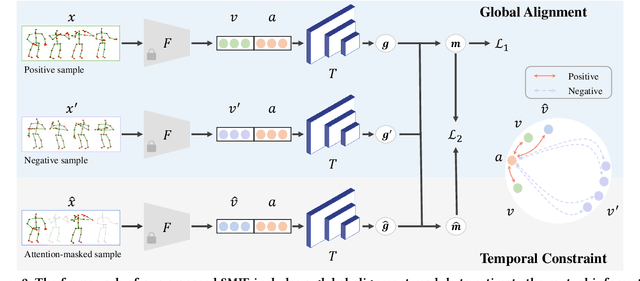
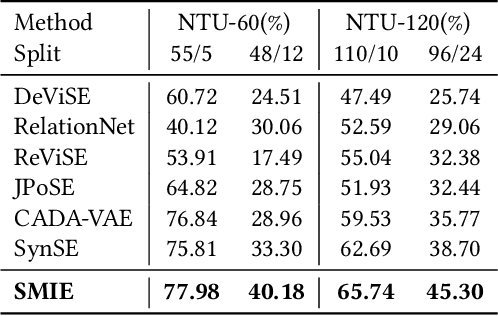
Zero-shot skeleton-based action recognition aims to recognize actions of unseen categories after training on data of seen categories. The key is to build the connection between visual and semantic space from seen to unseen classes. Previous studies have primarily focused on encoding sequences into a singular feature vector, with subsequent mapping the features to an identical anchor point within the embedded space. Their performance is hindered by 1) the ignorance of the global visual/semantic distribution alignment, which results in a limitation to capture the true interdependence between the two spaces. 2) the negligence of temporal information since the frame-wise features with rich action clues are directly pooled into a single feature vector. We propose a new zero-shot skeleton-based action recognition method via mutual information (MI) estimation and maximization. Specifically, 1) we maximize the MI between visual and semantic space for distribution alignment; 2) we leverage the temporal information for estimating the MI by encouraging MI to increase as more frames are observed. Extensive experiments on three large-scale skeleton action datasets confirm the effectiveness of our method. Code: https://github.com/YujieOuO/SMIE.