 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniLayout: Enabling Coarse-to-Fine Learning with LLMs for Universal Document Layout Generation
Oct 30, 2025Document AI has advanced rapidly and is attracting increasing attention. Yet, while most efforts have focused on document layout analysis (DLA), its generative counterpart, document layout generation, remains underexplored. A major obstacle lies in the scarcity of diverse layouts: academic papers with Manhattan-style structures dominate existing studies, while open-world genres such as newspapers and magazines remain severely underrepresented. To address this gap, we curate OmniLayout-1M, the first million-scale dataset of diverse document layouts, covering six common document types and comprising contemporary layouts collected from multiple sources. Moreover, since existing methods struggle in complex domains and often fail to arrange long sequences coherently, we introduce OmniLayout-LLM, a 0.5B model with designed two-stage Coarse-to-Fine learning paradigm: 1) learning universal layout principles from OmniLayout-1M with coarse category definitions, and 2) transferring the knowledge to a specific domain with fine-grained annotations. Extensive experiments demonstrate that our approach achieves strong performance on multiple domains in M$^{6}$Doc dataset, substantially surpassing both existing layout generation experts and several latest general-purpose LLMs. Our code, models, and dataset will be publicly released.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025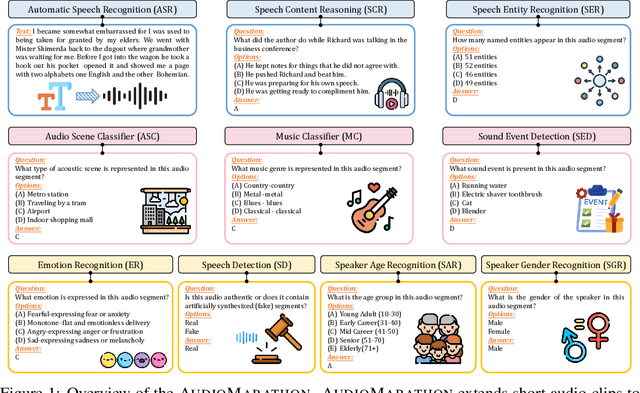
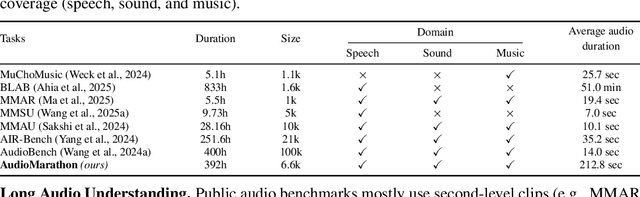
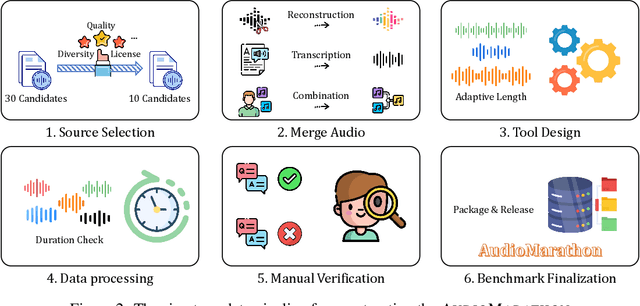

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
CDM: A Reliable Metric for Fair and Accurate Formula Recognition Evaluation
Sep 05, 2024
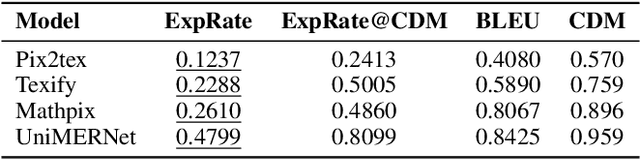


Formula recognition presents significant challenges due to the complicated structure and varied notation of mathematical expressions. Despite continuous advancements in formula recognition models, the evaluation metrics employed by these models, such as BLEU and Edit Distance, still exhibit notable limitations. They overlook the fact that the same formula has diverse representations and is highly sensitive to the distribution of training data, thereby causing the unfairness in formula recognition evaluation. To this end, we propose a Character Detection Matching (CDM) metric, ensuring the evaluation objectivity by designing a image-level rather than LaTex-level metric score. Specifically, CDM renders both the model-predicted LaTeX and the ground-truth LaTeX formulas into image-formatted formulas, then employs visual feature extraction and localization techniques for precise character-level matching, incorporating spatial position information. Such a spatially-aware and character-matching method offers a more accurate and equitable evaluation compared with previous BLEU and Edit Distance metrics that rely solely on text-based character matching. Experimentally, we evaluated various formula recognition models using CDM, BLEU, and ExpRate metrics. Their results demonstrate that the CDM aligns more closely with human evaluation standards and provides a fairer comparison across different models by eliminating discrepancies caused by diverse formula representations.
UniMERNet: A Universal Network for Real-World Mathematical Expression Recognition
Apr 23, 2024This paper presents the UniMER dataset to provide the first study on Mathematical Expression Recognition (MER) towards complex real-world scenarios. The UniMER dataset consists of a large-scale training set UniMER-1M offering an unprecedented scale and diversity with one million training instances and a meticulously designed test set UniMER-Test that reflects a diverse range of formula distributions prevalent in real-world scenarios. Therefore, the UniMER dataset enables the training of a robust and high-accuracy MER model and comprehensive evaluation of model performance. Moreover, we introduce the Universal Mathematical Expression Recognition Network (UniMERNet), an innovative framework designed to enhance MER in practical scenarios. UniMERNet incorporates a Length-Aware Module to process formulas of varied lengths efficiently, thereby enabling the model to handle complex mathematical expressions with greater accuracy. In addition, UniMERNet employs our UniMER-1M data and image augmentation techniques to improve the model's robustness under different noise conditions. Our extensive experiments demonstrate that UniMERNet outperforms existing MER models, setting a new benchmark in various scenarios and ensuring superior recognition quality in real-world applications. The dataset and model are available at https://github.com/opendatalab/UniMERNet.