 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioEnvSense: A Human-Centred Security Framework for Preventing Behaviour-Driven Cyber Incidents
Feb 23, 2026Modern organizations increasingly face cybersecurity incidents driven by human behaviour rather than technical failures. To address this, we propose a conceptual security framework that integrates a hybrid Convolutional Neural Network-Long Short-Term Memory (CNN-LSTM) model to analyze biometric and environmental data for context-aware security decisions. The CNN extracts spatial patterns from sensor data, while the LSTM captures temporal dynamics associated with human error susceptibility. The model achieves 84% accuracy, demonstrating its ability to reliably detect conditions that lead to elevated human-centred cyber risk. By enabling continuous monitoring and adaptive safeguards, the framework supports proactive interventions that reduce the likelihood of human-driven cyber incidents
Ensemble Learning based Anomaly Detection for IoT Cybersecurity via Bayesian Hyperparameters Sensitivity Analysis
Jul 20, 2023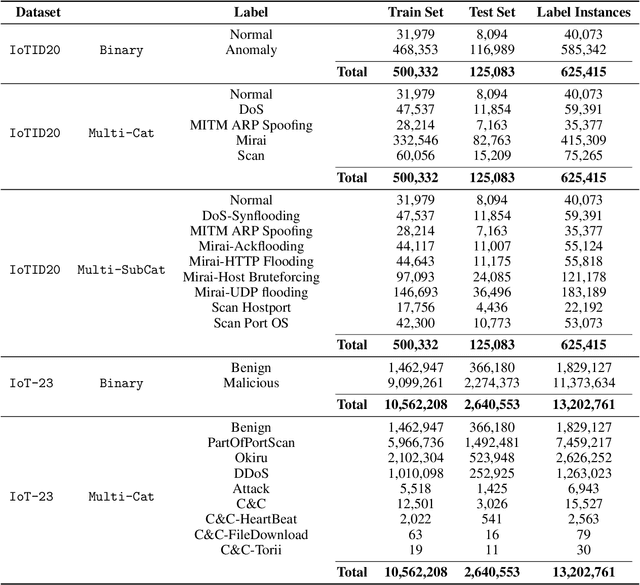
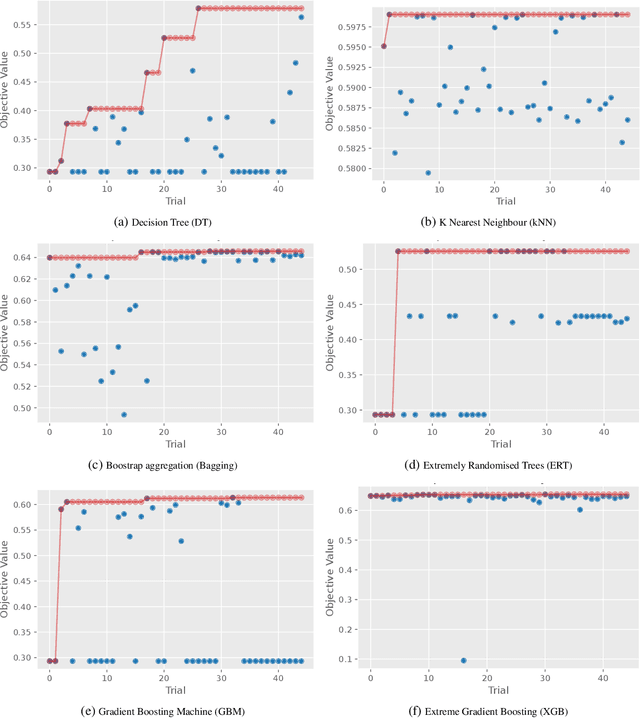
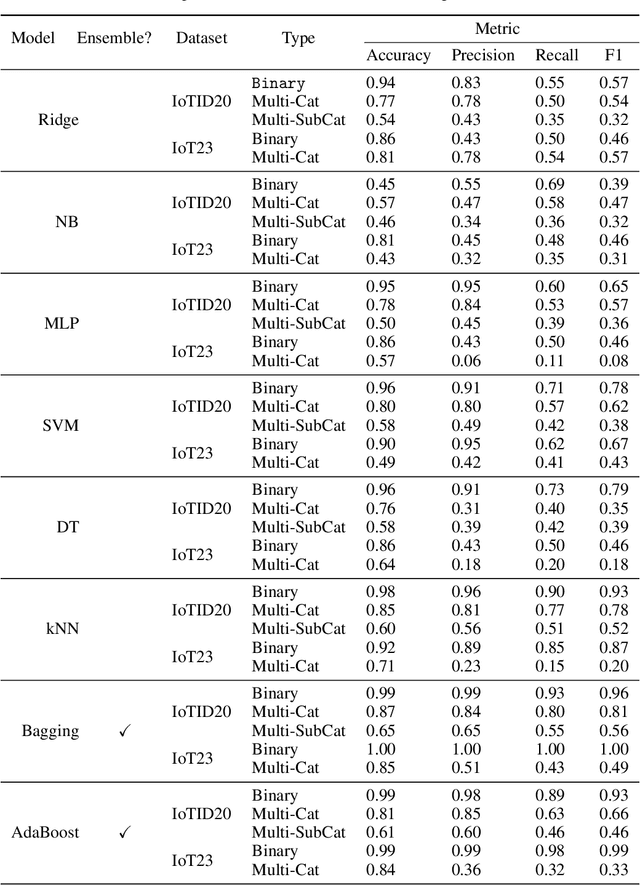
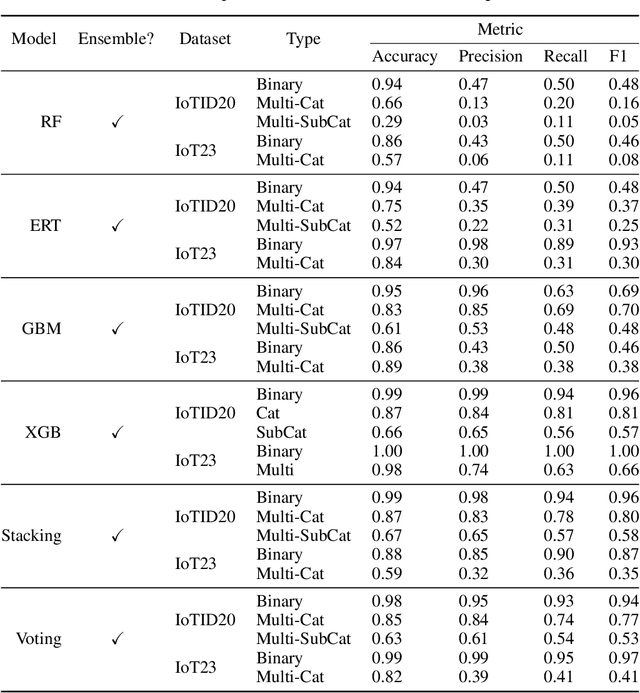
The Internet of Things (IoT) integrates more than billions of intelligent devices over the globe with the capability of communicating with other connected devices with little to no human intervention. IoT enables data aggregation and analysis on a large scale to improve life quality in many domains. In particular, data collected by IoT contain a tremendous amount of information for anomaly detection. The heterogeneous nature of IoT is both a challenge and an opportunity for cybersecurity. Traditional approaches in cybersecurity monitoring often require different kinds of data pre-processing and handling for various data types, which might be problematic for datasets that contain heterogeneous features. However, heterogeneous types of network devices can often capture a more diverse set of signals than a single type of device readings, which is particularly useful for anomaly detection. In this paper, we present a comprehensive study on using ensemble machine learning methods for enhancing IoT cybersecurity via anomaly detection. Rather than using one single machine learning model, ensemble learning combines the predictive power from multiple models, enhancing their predictive accuracy in heterogeneous datasets rather than using one single machine learning model. We propose a unified framework with ensemble learning that utilises Bayesian hyperparameter optimisation to adapt to a network environment that contains multiple IoT sensor readings. Experimentally, we illustrate their high predictive power when compared to traditional methods.
Water and Sediment Analyse Using Predictive Models
Mar 04, 2022
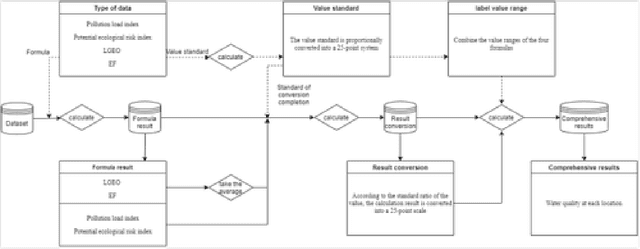

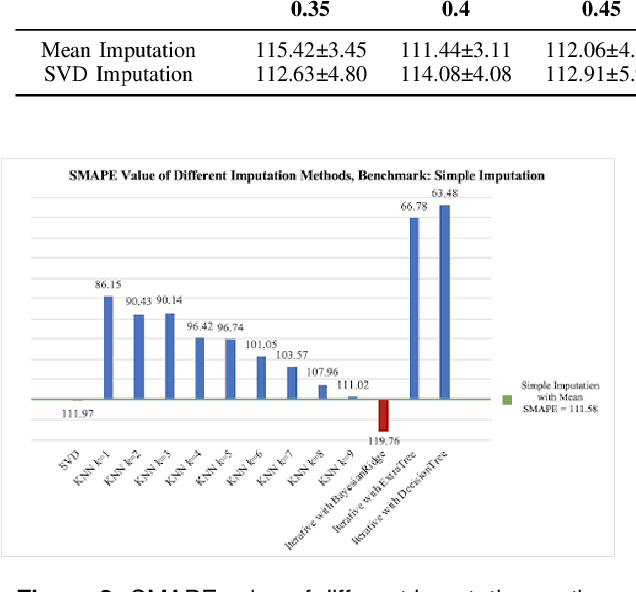
The increasing prevalence of marine pollution during the past few decades motivated recent research to help ease the situation. Typical water quality assessment requires continuous monitoring of water and sediments at remote locations with labour intensive laboratory tests to determine the degree of pollution. We propose an automated framework where we formalise a predictive model using Machine Learning to infer the water quality and level of pollution using collected water and sediments samples. One commonly encountered difficulty performing statistical analysis with water and sediment is the limited amount of data samples and incomplete dataset due to the sparsity of sample collection location. To this end, we performed extensive investigation on various data imputation methods' performance in water and sediment datasets with various data missing rates. Empirically, we show that our best model archives an accuracy of 75% after accounting for 57% of missing data. Experimentally, we show that our model would assist in assessing water quality screening based on possibly incomplete real-world data.