 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Wavelet Transformers for Operator Learning of Dynamical Systems
Feb 01, 2026Recent years have seen a surge in data-driven surrogates for dynamical systems that can be orders of magnitude faster than numerical solvers. However, many machine learning-based models such as neural operators exhibit spectral bias, attenuating high-frequency components that often encode small-scale structure. This limitation is particularly damaging in applications such as weather forecasting, where misrepresented high frequencies can induce long-horizon instability. To address this issue, we propose multi-scale wavelet transformers (MSWTs), which learn system dynamics in a tokenized wavelet domain. The wavelet transform explicitly separates low- and high-frequency content across scales. MSWTs leverage a wavelet-preserving downsampling scheme that retains high-frequency features and employ wavelet-based attention to capture dependencies across scales and frequency bands. Experiments on chaotic dynamical systems show substantial error reductions and improved long horizon spectral fidelity. On the ERA5 climate reanalysis, MSWTs further reduce climatological bias, demonstrating their effectiveness in a real-world forecasting setting.
Amortized variational transdimensional inference
Jun 05, 2025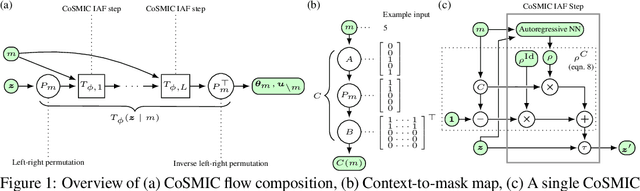
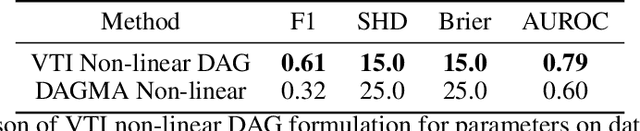
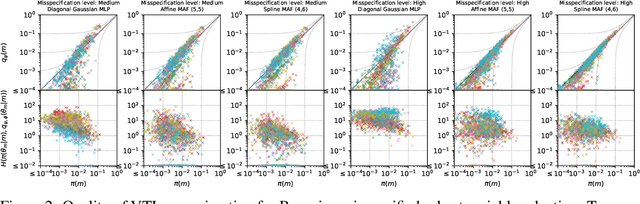
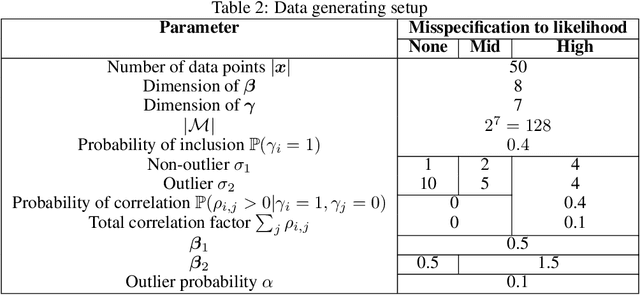
The expressiveness of flow-based models combined with stochastic variational inference (SVI) has, in recent years, expanded the application of optimization-based Bayesian inference to include problems with complex data relationships. However, until now, SVI using flow-based models has been limited to problems of fixed dimension. We introduce CoSMIC, normalizing flows (COntextually-Specified Masking for Identity-mapped Components), an extension to neural autoregressive conditional normalizing flow architectures that enables using a single amortized variational density for inference over a transdimensional target distribution. We propose a combined stochastic variational transdimensional inference (VTI) approach to training CoSMIC flows using techniques from Bayesian optimization and Monte Carlo gradient estimation. Numerical experiments demonstrate the performance of VTI on challenging problems that scale to high-cardinality model spaces.
Variational Search Distributions
Sep 10, 2024



We develop variational search distributions (VSD), a method for finding discrete, combinatorial designs of a rare desired class in a batch sequential manner with a fixed experimental budget. We formalize the requirements and desiderata for this problem and formulate a solution via variational inference that fulfill these. In particular, VSD uses off-the-shelf gradient based optimization routines, and can take advantage of scalable predictive models. We show that VSD can outperform existing baseline methods on a set of real sequence-design problems in various biological systems.
Stein Random Feature Regression
Jun 04, 2024



In large-scale regression problems, random Fourier features (RFFs) have significantly enhanced the computational scalability and flexibility of Gaussian processes (GPs) by defining kernels through their spectral density, from which a finite set of Monte Carlo samples can be used to form an approximate low-rank GP. However, the efficacy of RFFs in kernel approximation and Bayesian kernel learning depends on the ability to tractably sample the kernel spectral measure and the quality of the generated samples. We introduce Stein random features (SRF), leveraging Stein variational gradient descent, which can be used to both generate high-quality RFF samples of known spectral densities as well as flexibly and efficiently approximate traditionally non-analytical spectral measure posteriors. SRFs require only the evaluation of log-probability gradients to perform both kernel approximation and Bayesian kernel learning that results in superior performance over traditional approaches. We empirically validate the effectiveness of SRFs by comparing them to baselines on kernel approximation and well-known GP regression problems.
Bayesian Adaptive Calibration and Optimal Design
May 23, 2024



The process of calibrating computer models of natural phenomena is essential for applications in the physical sciences, where plenty of domain knowledge can be embedded into simulations and then calibrated against real observations. Current machine learning approaches, however, mostly rely on rerunning simulations over a fixed set of designs available in the observed data, potentially neglecting informative correlations across the design space and requiring a large amount of simulations. Instead, we consider the calibration process from the perspective of Bayesian adaptive experimental design and propose a data-efficient algorithm to run maximally informative simulations within a batch-sequential process. At each round, the algorithm jointly estimates the parameters of the posterior distribution and optimal designs by maximising a variational lower bound of the expected information gain. The simulator is modelled as a sample from a Gaussian process, which allows us to correlate simulations and observed data with the unknown calibration parameters. We show the benefits of our method when compared to related approaches across synthetic and real-data problems.
Path Signatures for Diversity in Probabilistic Trajectory Optimisation
Aug 08, 2023



Motion planning can be cast as a trajectory optimisation problem where a cost is minimised as a function of the trajectory being generated. In complex environments with several obstacles and complicated geometry, this optimisation problem is usually difficult to solve and prone to local minima. However, recent advancements in computing hardware allow for parallel trajectory optimisation where multiple solutions are obtained simultaneously, each initialised from a different starting point. Unfortunately, without a strategy preventing two solutions to collapse on each other, naive parallel optimisation can suffer from mode collapse diminishing the efficiency of the approach and the likelihood of finding a global solution. In this paper we leverage on recent advances in the theory of rough paths to devise an algorithm for parallel trajectory optimisation that promotes diversity over the range of solutions, therefore avoiding mode collapses and achieving better global properties. Our approach builds on path signatures and Hilbert space representations of trajectories, and connects parallel variational inference for trajectory estimation with diversity promoting kernels. We empirically demonstrate that this strategy achieves lower average costs than competing alternatives on a range of problems, from 2D navigation to robotic manipulators operating in cluttered environments.
Batch Bayesian optimisation via density-ratio estimation with guarantees
Sep 22, 2022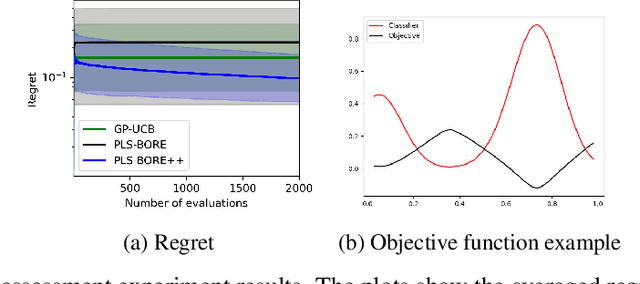
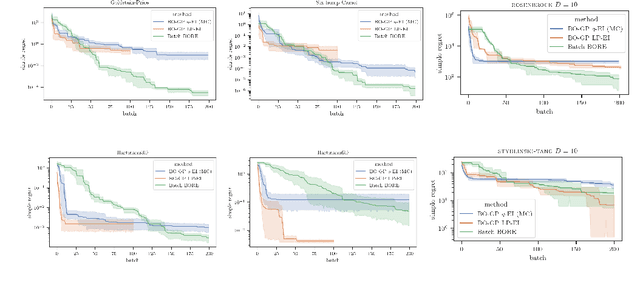
Bayesian optimisation (BO) algorithms have shown remarkable success in applications involving expensive black-box functions. Traditionally BO has been set as a sequential decision-making process which estimates the utility of query points via an acquisition function and a prior over functions, such as a Gaussian process. Recently, however, a reformulation of BO via density-ratio estimation (BORE) allowed reinterpreting the acquisition function as a probabilistic binary classifier, removing the need for an explicit prior over functions and increasing scalability. In this paper, we present a theoretical analysis of BORE's regret and an extension of the algorithm with improved uncertainty estimates. We also show that BORE can be naturally extended to a batch optimisation setting by recasting the problem as approximate Bayesian inference. The resulting algorithm comes equipped with theoretical performance guarantees and is assessed against other batch BO baselines in a series of experiments.
Adaptive Model Predictive Control by Learning Classifiers
Apr 05, 2022



Stochastic model predictive control has been a successful and robust control framework for many robotics tasks where the system dynamics model is slightly inaccurate or in the presence of environment disturbances. Despite the successes, it is still unclear how to best adjust control parameters to the current task in the presence of model parameter uncertainty and heteroscedastic noise. In this paper, we propose an adaptive MPC variant that automatically estimates control and model parameters by leveraging ideas from Bayesian optimisation (BO) and the classical expected improvement acquisition function. We leverage recent results showing that BO can be reformulated via density ratio estimation, which can be efficiently approximated by simply learning a classifier. This is then integrated into a model predictive path integral control framework yielding robust controllers for a variety of challenging robotics tasks. We demonstrate the approach on classical control problems under model uncertainty and robotics manipulation tasks.
Bayesian Optimisation for Robust Model Predictive Control under Model Parameter Uncertainty
Mar 02, 2022

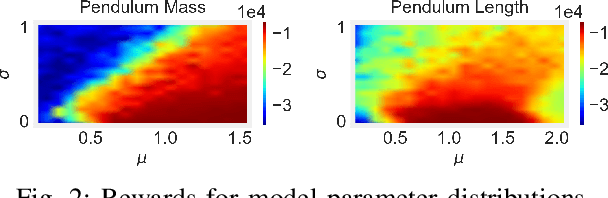

We propose an adaptive optimisation approach for tuning stochastic model predictive control (MPC) hyper-parameters while jointly estimating probability distributions of the transition model parameters based on performance rewards. In particular, we develop a Bayesian optimisation (BO) algorithm with a heteroscedastic noise model to deal with varying noise across the MPC hyper-parameter and dynamics model parameter spaces. Typical homoscedastic noise models are unrealistic for tuning MPC since stochastic controllers are inherently noisy, and the level of noise is affected by their hyper-parameter settings. We evaluate the proposed optimisation algorithm in simulated control and robotics tasks where we jointly infer control and dynamics parameters. Experimental results demonstrate that our approach leads to higher cumulative rewards and more stable controllers.
Near optimal sample complexity for matrix and tensor normal models via geodesic convexity
Oct 14, 2021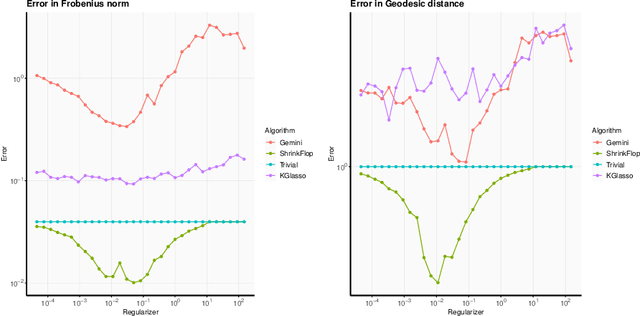
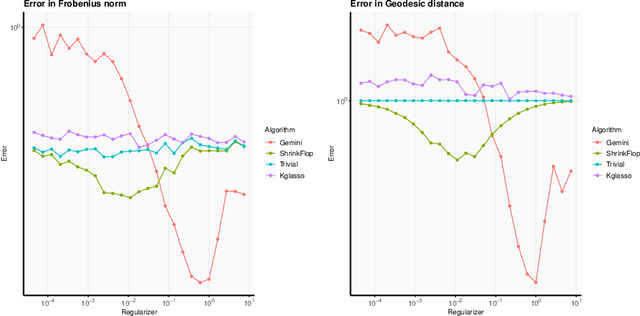
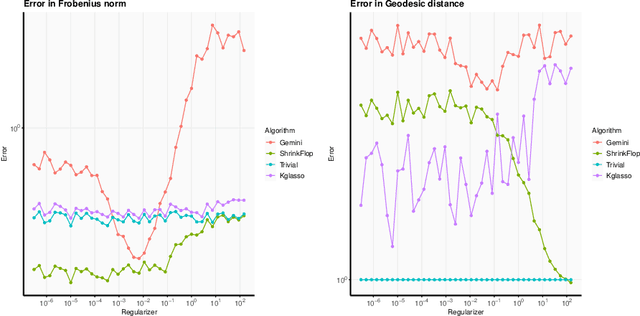
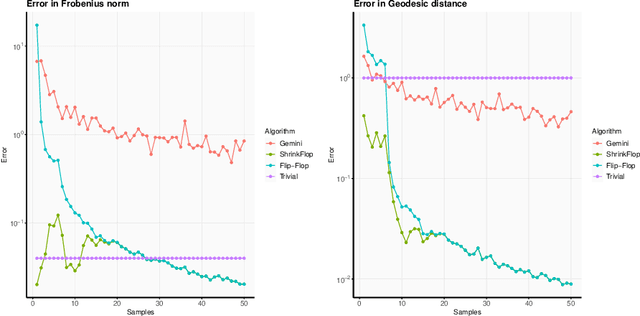
The matrix normal model, the family of Gaussian matrix-variate distributions whose covariance matrix is the Kronecker product of two lower dimensional factors, is frequently used to model matrix-variate data. The tensor normal model generalizes this family to Kronecker products of three or more factors. We study the estimation of the Kronecker factors of the covariance matrix in the matrix and tensor models. We show nonasymptotic bounds for the error achieved by the maximum likelihood estimator (MLE) in several natural metrics. In contrast to existing bounds, our results do not rely on the factors being well-conditioned or sparse. For the matrix normal model, all our bounds are minimax optimal up to logarithmic factors, and for the tensor normal model our bound for the largest factor and overall covariance matrix are minimax optimal up to constant factors provided there are enough samples for any estimator to obtain constant Frobenius error. In the same regimes as our sample complexity bounds, we show that an iterative procedure to compute the MLE known as the flip-flop algorithm converges linearly with high probability. Our main tool is geodesic strong convexity in the geometry on positive-definite matrices induced by the Fisher information metric. This strong convexity is determined by the expansion of certain random quantum channels. We also provide numerical evidence that combining the flip-flop algorithm with a simple shrinkage estimator can improve performance in the undersampled regime.