 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera-LiDAR Fusion with Latent Contact for Place Recognition in Challenging Cross-Scenes
Oct 16, 2023



Although significant progress has been made, achieving place recognition in environments with perspective changes, seasonal variations, and scene transformations remains challenging. Relying solely on perception information from a single sensor is insufficient to address these issues. Recognizing the complementarity between cameras and LiDAR, multi-modal fusion methods have attracted attention. To address the information waste in existing multi-modal fusion works, this paper introduces a novel three-channel place descriptor, which consists of a cascade of image, point cloud, and fusion branches. Specifically, the fusion-based branch employs a dual-stage pipeline, leveraging the correlation between the two modalities with latent contacts, thereby facilitating information interaction and fusion. Extensive experiments on the KITTI, NCLT, USVInland, and the campus dataset demonstrate that the proposed place descriptor stands as the state-of-the-art approach, confirming its robustness and generality in challenging scenarios.
MotionBEV: Attention-Aware Online LiDAR Moving Object Segmentation with Bird's Eye View based Appearance and Motion Features
May 12, 2023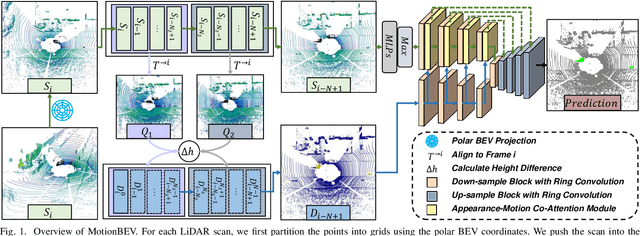

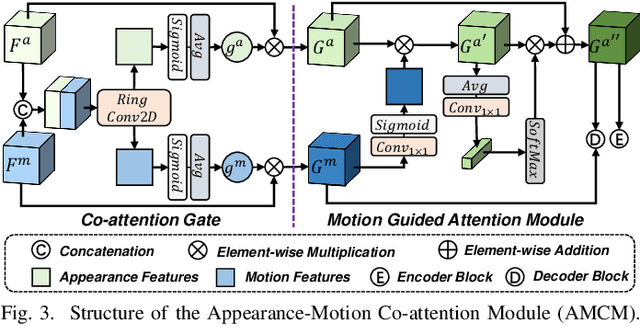
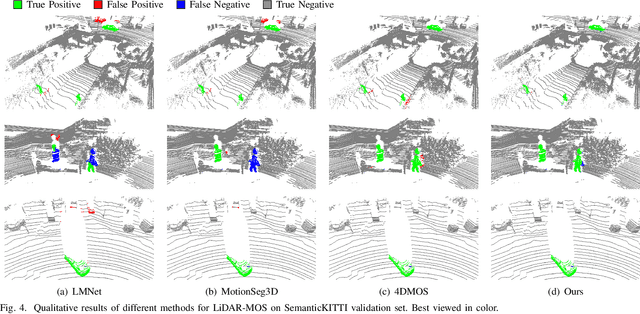
Identifying moving objects is an essential capability for autonomous systems, as it provides critical information for pose estimation, navigation, collision avoidance and static map construction. In this paper, we present MotionBEV, a fast and accurate framework for LiDAR moving object segmentation, which segments moving objects with appearance and motion features in bird's eye view (BEV) domain. Our approach converts 3D LiDAR scans into 2D polar BEV representation to achieve real-time performance. Specifically, we learn appearance features with a simplified PointNet, and compute motion features through the height differences of consecutive frames of point clouds projected onto vertical columns in the polar BEV coordinate system. We employ a dual-branch network bridged by the Appearance-Motion Co-attention Module (AMCM) to adaptively fuse the spatio-temporal information from appearance and motion features. Our approach achieves state-of-the-art performance on the SemanticKITTI-MOS benchmark, with an average inference time of 23ms on an RTX 3090 GPU. Furthermore, to demonstrate the practical effectiveness of our method, we provide a LiDAR-MOS dataset recorded by a solid-state LiDAR, which features non-repetitive scanning patterns and small field of view.