 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-sync Video Instance Editing with Granularity-Aware Mask Refiner
Dec 11, 2025



Recent advancements in video generation highlight that realistic audio-visual synchronization is crucial for engaging content creation. However, existing video editing methods largely overlook audio-visual synchronization and lack the fine-grained spatial and temporal controllability required for precise instance-level edits. In this paper, we propose AVI-Edit, a framework for audio-sync video instance editing. We propose a granularity-aware mask refiner that iteratively refines coarse user-provided masks into precise instance-level regions. We further design a self-feedback audio agent to curate high-quality audio guidance, providing fine-grained temporal control. To facilitate this task, we additionally construct a large-scale dataset with instance-centric correspondence and comprehensive annotations. Extensive experiments demonstrate that AVI-Edit outperforms state-of-the-art methods in visual quality, condition following, and audio-visual synchronization. Project page: https://hjzheng.net/projects/AVI-Edit/.
PanoWan: Lifting Diffusion Video Generation Models to 360° with Latitude/Longitude-aware Mechanisms
May 28, 2025Panoramic video generation enables immersive 360{\deg} content creation, valuable in applications that demand scene-consistent world exploration. However, existing panoramic video generation models struggle to leverage pre-trained generative priors from conventional text-to-video models for high-quality and diverse panoramic videos generation, due to limited dataset scale and the gap in spatial feature representations. In this paper, we introduce PanoWan to effectively lift pre-trained text-to-video models to the panoramic domain, equipped with minimal modules. PanoWan employs latitude-aware sampling to avoid latitudinal distortion, while its rotated semantic denoising and padded pixel-wise decoding ensure seamless transitions at longitude boundaries. To provide sufficient panoramic videos for learning these lifted representations, we contribute PanoVid, a high-quality panoramic video dataset with captions and diverse scenarios. Consequently, PanoWan achieves state-of-the-art performance in panoramic video generation and demonstrates robustness for zero-shot downstream tasks.
The Future of Cognitive Strategy-enhanced Persuasive Dialogue Agents: New Perspectives and Trends
Feb 07, 2024
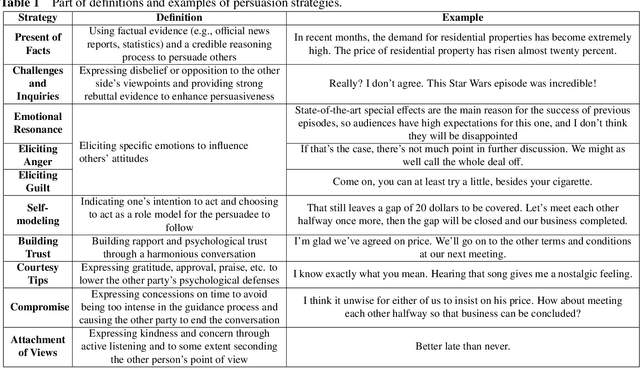

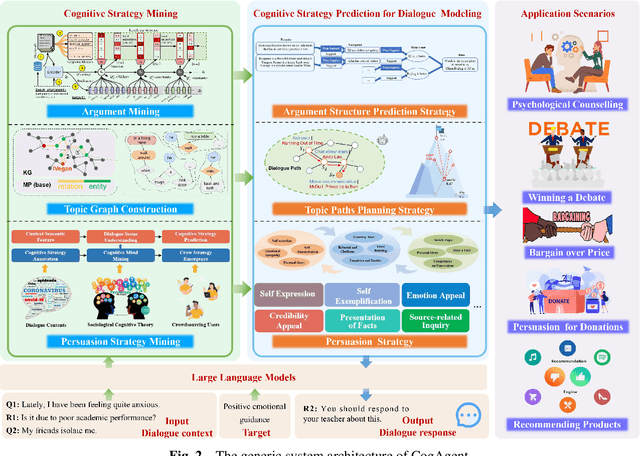
Persuasion, as one of the crucial abilities in human communication, has garnered extensive attention from researchers within the field of intelligent dialogue systems. We humans tend to persuade others to change their viewpoints, attitudes or behaviors through conversations in various scenarios (e.g., persuasion for social good, arguing in online platforms). Developing dialogue agents that can persuade others to accept certain standpoints is essential to achieving truly intelligent and anthropomorphic dialogue system. Benefiting from the substantial progress of Large Language Models (LLMs), dialogue agents have acquired an exceptional capability in context understanding and response generation. However, as a typical and complicated cognitive psychological system, persuasive dialogue agents also require knowledge from the domain of cognitive psychology to attain a level of human-like persuasion. Consequently, the cognitive strategy-enhanced persuasive dialogue agent (defined as CogAgent), which incorporates cognitive strategies to achieve persuasive targets through conversation, has become a predominant research paradigm. To depict the research trends of CogAgent, in this paper, we first present several fundamental cognitive psychology theories and give the formalized definition of three typical cognitive strategies, including the persuasion strategy, the topic path planning strategy, and the argument structure prediction strategy. Then we propose a new system architecture by incorporating the formalized definition to lay the foundation of CogAgent. Representative works are detailed and investigated according to the combined cognitive strategy, followed by the summary of authoritative benchmarks and evaluation metrics. Finally, we summarize our insights on open issues and future directions of CogAgent for upcoming researchers.