 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaScale: Dynamic Context-aware DNN Scaling via Automated Adaptation Loop on Mobile Devices
Dec 01, 2024Deep learning is reshaping mobile applications, with a growing trend of deploying deep neural networks (DNNs) directly to mobile and embedded devices to address real-time performance and privacy. To accommodate local resource limitations, techniques like weight compression, convolution decomposition, and specialized layer architectures have been developed. However, the \textit{dynamic} and \textit{diverse} deployment contexts of mobile devices pose significant challenges. Adapting deep models to meet varied device-specific requirements for latency, accuracy, memory, and energy is labor-intensive. Additionally, changing processor states, fluctuating memory availability, and competing processes frequently necessitate model re-compression to preserve user experience. To address these issues, we introduce AdaScale, an elastic inference framework that automates the adaptation of deep models to dynamic contexts. AdaScale leverages a self-evolutionary model to streamline network creation, employs diverse compression operator combinations to reduce the search space and improve outcomes, and integrates a resource availability awareness block and performance profilers to establish an automated adaptation loop. Our experiments demonstrate that AdaScale significantly enhances accuracy by 5.09%, reduces training overhead by 66.89%, speeds up inference latency by 1.51 to 6.2 times, and lowers energy costs by 4.69 times.
UbiHR: Resource-efficient Long-range Heart Rate Sensing on Ubiquitous Devices
Oct 25, 2024



Ubiquitous on-device heart rate sensing is vital for high-stress individuals and chronic patients. Non-contact sensing, compared to contact-based tools, allows for natural user monitoring, potentially enabling more accurate and holistic data collection. However, in open and uncontrolled mobile environments, user movement and lighting introduce. Existing methods, such as curve-based or short-range deep learning recognition based on adjacent frames, strike the optimal balance between real-time performance and accuracy, especially under limited device resources. In this paper, we present UbiHR, a ubiquitous device-based heart rate sensing system. Key to UbiHR is a real-time long-range spatio-temporal model enabling noise-independent heart rate recognition and display on commodity mobile devices, along with a set of mechanisms for prompt and energy-efficient sampling and preprocessing. Diverse experiments and user studies involving four devices, four tasks, and 80 participants demonstrate UbiHR's superior performance, enhancing accuracy by up to 74.2\% and reducing latency by 51.2\%.
CrowdTransfer: Enabling Crowd Knowledge Transfer in AIoT Community
Jul 09, 2024Artificial Intelligence of Things (AIoT) is an emerging frontier based on the deep fusion of Internet of Things (IoT) and Artificial Intelligence (AI) technologies. Although advanced deep learning techniques enhance the efficient data processing and intelligent analysis of complex IoT data, they still suffer from notable challenges when deployed to practical AIoT applications, such as constrained resources, and diverse task requirements. Knowledge transfer is an effective method to enhance learning performance by avoiding the exorbitant costs associated with data recollection and model retraining. Notably, although there are already some valuable and impressive surveys on transfer learning, these surveys introduce approaches in a relatively isolated way and lack the recent advances of various knowledge transfer techniques for AIoT field. This survey endeavors to introduce a new concept of knowledge transfer, referred to as Crowd Knowledge Transfer (CrowdTransfer), which aims to transfer prior knowledge learned from a crowd of agents to reduce the training cost and as well as improve the performance of the model in real-world complicated scenarios. Particularly, we present four transfer modes from the perspective of crowd intelligence, including derivation, sharing, evolution and fusion modes. Building upon conventional transfer learning methods, we further delve into advanced crowd knowledge transfer models from three perspectives for various AIoT applications. Furthermore, we explore some applications of AIoT areas, such as human activity recognition, urban computing, multi-robot system, and smart factory. Finally, we discuss the open issues and outline future research directions of knowledge transfer in AIoT community.
The Future of Cognitive Strategy-enhanced Persuasive Dialogue Agents: New Perspectives and Trends
Feb 07, 2024
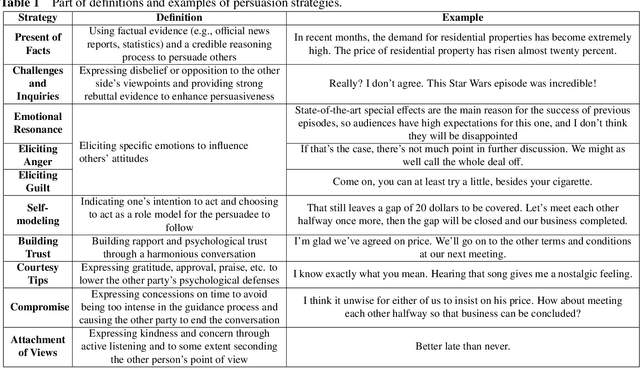

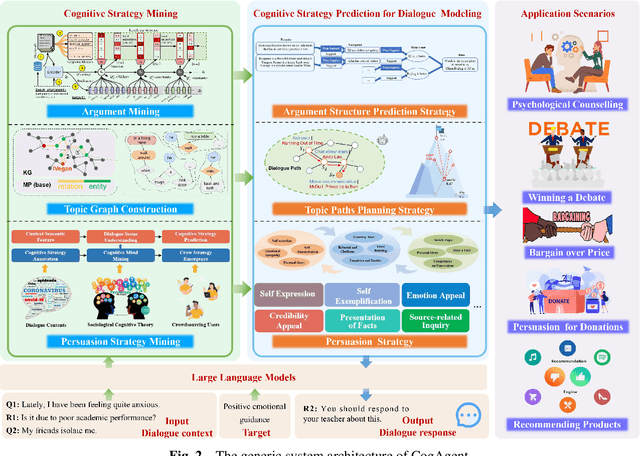
Persuasion, as one of the crucial abilities in human communication, has garnered extensive attention from researchers within the field of intelligent dialogue systems. We humans tend to persuade others to change their viewpoints, attitudes or behaviors through conversations in various scenarios (e.g., persuasion for social good, arguing in online platforms). Developing dialogue agents that can persuade others to accept certain standpoints is essential to achieving truly intelligent and anthropomorphic dialogue system. Benefiting from the substantial progress of Large Language Models (LLMs), dialogue agents have acquired an exceptional capability in context understanding and response generation. However, as a typical and complicated cognitive psychological system, persuasive dialogue agents also require knowledge from the domain of cognitive psychology to attain a level of human-like persuasion. Consequently, the cognitive strategy-enhanced persuasive dialogue agent (defined as CogAgent), which incorporates cognitive strategies to achieve persuasive targets through conversation, has become a predominant research paradigm. To depict the research trends of CogAgent, in this paper, we first present several fundamental cognitive psychology theories and give the formalized definition of three typical cognitive strategies, including the persuasion strategy, the topic path planning strategy, and the argument structure prediction strategy. Then we propose a new system architecture by incorporating the formalized definition to lay the foundation of CogAgent. Representative works are detailed and investigated according to the combined cognitive strategy, followed by the summary of authoritative benchmarks and evaluation metrics. Finally, we summarize our insights on open issues and future directions of CogAgent for upcoming researchers.
Enabling Harmonious Human-Machine Interaction with Visual-Context Augmented Dialogue System: A Review
Jul 02, 2022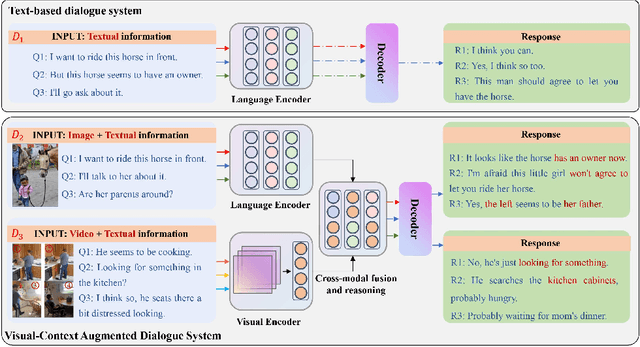
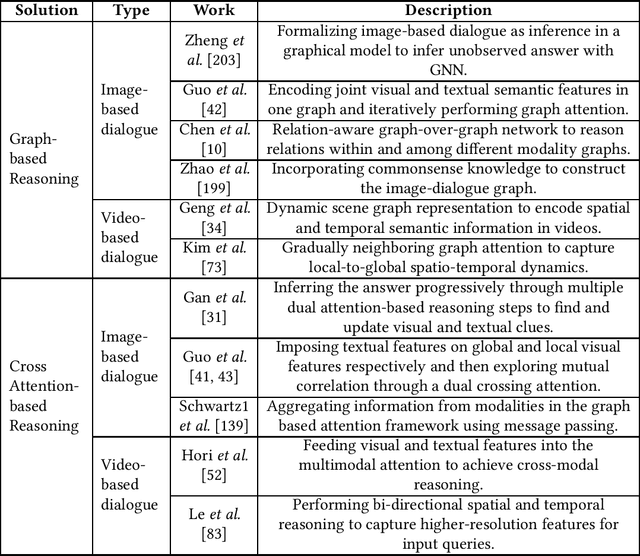
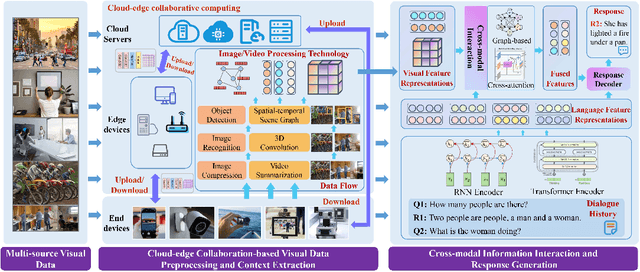

The intelligent dialogue system, aiming at communicating with humans harmoniously with natural language, is brilliant for promoting the advancement of human-machine interaction in the era of artificial intelligence. With the gradually complex human-computer interaction requirements (e.g., multimodal inputs, time sensitivity), it is difficult for traditional text-based dialogue system to meet the demands for more vivid and convenient interaction. Consequently, Visual Context Augmented Dialogue System (VAD), which has the potential to communicate with humans by perceiving and understanding multimodal information (i.e., visual context in images or videos, textual dialogue history), has become a predominant research paradigm. Benefiting from the consistency and complementarity between visual and textual context, VAD possesses the potential to generate engaging and context-aware responses. For depicting the development of VAD, we first characterize the concepts and unique features of VAD, and then present its generic system architecture to illustrate the system workflow. Subsequently, several research challenges and representative works are detailed investigated, followed by the summary of authoritative benchmarks. We conclude this paper by putting forward some open issues and promising research trends for VAD, e.g., the cognitive mechanisms of human-machine dialogue under cross-modal dialogue context, and knowledge-enhanced cross-modal semantic interaction.
c-TextGen: Conditional Text Generation for Harmonious Human-Machine Interaction
Sep 08, 2019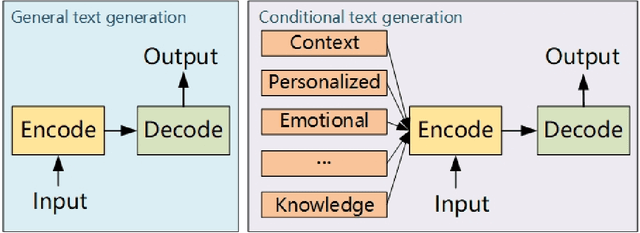
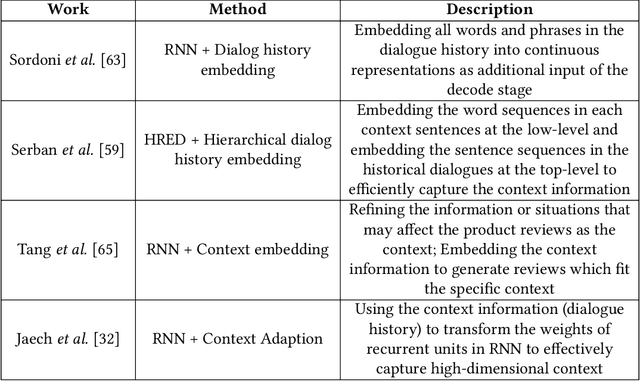
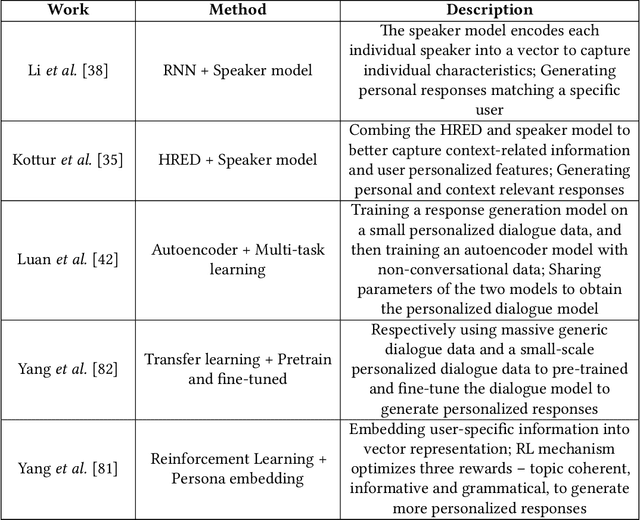
In recent years, with the development of deep learning technology, text generation technology has undergone great changes and provided many kinds of services for human beings, such as restaurant reservation and daily communication. The automatically generated text is becoming more and more fluent so researchers begin to consider more anthropomorphic text generation technology, that is the conditional text generation, including emotional text generation, personalized text generation, and so on. Conditional text generation (c-TextGen) has thus become a research hotspot. As a promising research field, we find that many efforts have been paid to researches of c-TextGen. Therefore, we aim to give a comprehensive review of the new research trends of c-TextGen. We first give a brief literature review of text generation technology, based on which we formalize the concept model of c-TextGen. We further make an investigation of several different c-TextGen techniques, and illustrate the advantages and disadvantages of commonly used neural network models. Finally, we discuss the open issues and promising research directions of c-TextGen.