 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Harmonious Human-Machine Interaction with Visual-Context Augmented Dialogue System: A Review
Paper and Code
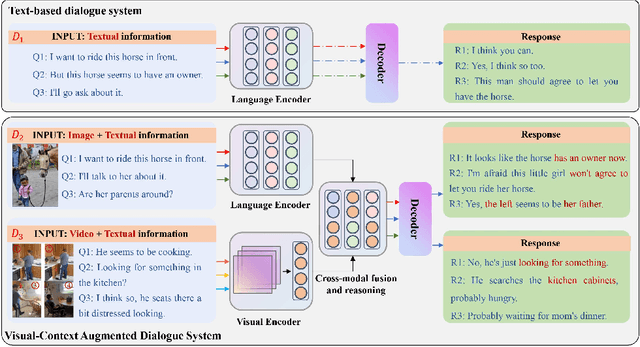
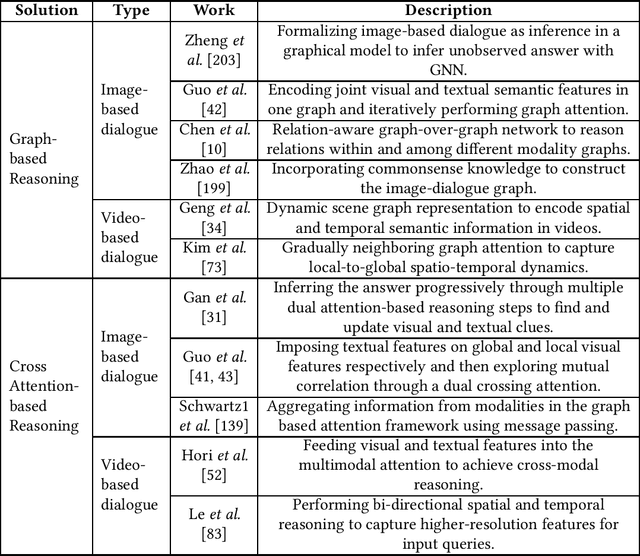
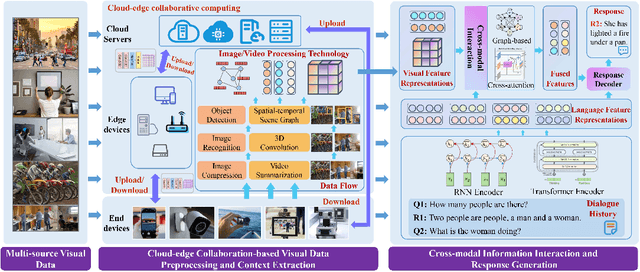

The intelligent dialogue system, aiming at communicating with humans harmoniously with natural language, is brilliant for promoting the advancement of human-machine interaction in the era of artificial intelligence. With the gradually complex human-computer interaction requirements (e.g., multimodal inputs, time sensitivity), it is difficult for traditional text-based dialogue system to meet the demands for more vivid and convenient interaction. Consequently, Visual Context Augmented Dialogue System (VAD), which has the potential to communicate with humans by perceiving and understanding multimodal information (i.e., visual context in images or videos, textual dialogue history), has become a predominant research paradigm. Benefiting from the consistency and complementarity between visual and textual context, VAD possesses the potential to generate engaging and context-aware responses. For depicting the development of VAD, we first characterize the concepts and unique features of VAD, and then present its generic system architecture to illustrate the system workflow. Subsequently, several research challenges and representative works are detailed investigated, followed by the summary of authoritative benchmarks. We conclude this paper by putting forward some open issues and promising research trends for VAD, e.g., the cognitive mechanisms of human-machine dialogue under cross-modal dialogue context, and knowledge-enhanced cross-modal semantic interaction.