 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deeper Emotional Reflection: Crafting Affective Image Filters with Generative Priors
Dec 19, 2025

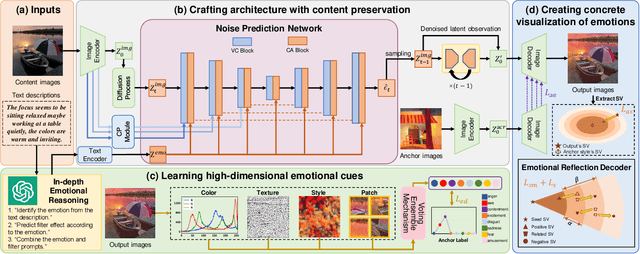

Social media platforms enable users to express emotions by posting text with accompanying images. In this paper, we propose the Affective Image Filter (AIF) task, which aims to reflect visually-abstract emotions from text into visually-concrete images, thereby creating emotionally compelling results. We first introduce the AIF dataset and the formulation of the AIF models. Then, we present AIF-B as an initial attempt based on a multi-modal transformer architecture. After that, we propose AIF-D as an extension of AIF-B towards deeper emotional reflection, effectively leveraging generative priors from pre-trained large-scale diffusion models. Quantitative and qualitative experiments demonstrate that AIF models achieve superior performance for both content consistency and emotional fidelity compared to state-of-the-art methods. Extensive user study experiments demonstrate that AIF models are significantly more effective at evoking specific emotions. Based on the presented results, we comprehensively discuss the value and potential of AIF models.
STAGE: Storyboard-Anchored Generation for Cinematic Multi-shot Narrative
Dec 13, 2025



While recent advancements in generative models have achieved remarkable visual fidelity in video synthesis, creating coherent multi-shot narratives remains a significant challenge. To address this, keyframe-based approaches have emerged as a promising alternative to computationally intensive end-to-end methods, offering the advantages of fine-grained control and greater efficiency. However, these methods often fail to maintain cross-shot consistency and capture cinematic language. In this paper, we introduce STAGE, a SToryboard-Anchored GEneration workflow to reformulate the keyframe-based multi-shot video generation task. Instead of using sparse keyframes, we propose STEP2 to predict a structural storyboard composed of start-end frame pairs for each shot. We introduce the multi-shot memory pack to ensure long-range entity consistency, the dual-encoding strategy for intra-shot coherence, and the two-stage training scheme to learn cinematic inter-shot transition. We also contribute the large-scale ConStoryBoard dataset, including high-quality movie clips with fine-grained annotations for story progression, cinematic attributes, and human preferences. Extensive experiments demonstrate that STAGE achieves superior performance in structured narrative control and cross-shot coherence.
Audio-sync Video Instance Editing with Granularity-Aware Mask Refiner
Dec 11, 2025



Recent advancements in video generation highlight that realistic audio-visual synchronization is crucial for engaging content creation. However, existing video editing methods largely overlook audio-visual synchronization and lack the fine-grained spatial and temporal controllability required for precise instance-level edits. In this paper, we propose AVI-Edit, a framework for audio-sync video instance editing. We propose a granularity-aware mask refiner that iteratively refines coarse user-provided masks into precise instance-level regions. We further design a self-feedback audio agent to curate high-quality audio guidance, providing fine-grained temporal control. To facilitate this task, we additionally construct a large-scale dataset with instance-centric correspondence and comprehensive annotations. Extensive experiments demonstrate that AVI-Edit outperforms state-of-the-art methods in visual quality, condition following, and audio-visual synchronization. Project page: https://hjzheng.net/projects/AVI-Edit/.
Audio-Sync Video Generation with Multi-Stream Temporal Control
Jun 09, 2025



Audio is inherently temporal and closely synchronized with the visual world, making it a naturally aligned and expressive control signal for controllable video generation (e.g., movies). Beyond control, directly translating audio into video is essential for understanding and visualizing rich audio narratives (e.g., Podcasts or historical recordings). However, existing approaches fall short in generating high-quality videos with precise audio-visual synchronization, especially across diverse and complex audio types. In this work, we introduce MTV, a versatile framework for audio-sync video generation. MTV explicitly separates audios into speech, effects, and music tracks, enabling disentangled control over lip motion, event timing, and visual mood, respectively -- resulting in fine-grained and semantically aligned video generation. To support the framework, we additionally present DEMIX, a dataset comprising high-quality cinematic videos and demixed audio tracks. DEMIX is structured into five overlapped subsets, enabling scalable multi-stage training for diverse generation scenarios. Extensive experiments demonstrate that MTV achieves state-of-the-art performance across six standard metrics spanning video quality, text-video consistency, and audio-video alignment. Project page: https://hjzheng.net/projects/MTV/.
PanoWan: Lifting Diffusion Video Generation Models to 360° with Latitude/Longitude-aware Mechanisms
May 28, 2025Panoramic video generation enables immersive 360{\deg} content creation, valuable in applications that demand scene-consistent world exploration. However, existing panoramic video generation models struggle to leverage pre-trained generative priors from conventional text-to-video models for high-quality and diverse panoramic videos generation, due to limited dataset scale and the gap in spatial feature representations. In this paper, we introduce PanoWan to effectively lift pre-trained text-to-video models to the panoramic domain, equipped with minimal modules. PanoWan employs latitude-aware sampling to avoid latitudinal distortion, while its rotated semantic denoising and padded pixel-wise decoding ensure seamless transitions at longitude boundaries. To provide sufficient panoramic videos for learning these lifted representations, we contribute PanoVid, a high-quality panoramic video dataset with captions and diverse scenarios. Consequently, PanoWan achieves state-of-the-art performance in panoramic video generation and demonstrates robustness for zero-shot downstream tasks.
Affective Image Editing: Shaping Emotional Factors via Text Descriptions
May 24, 2025In daily life, images as common affective stimuli have widespread applications. Despite significant progress in text-driven image editing, there is limited work focusing on understanding users' emotional requests. In this paper, we introduce AIEdiT for Affective Image Editing using Text descriptions, which evokes specific emotions by adaptively shaping multiple emotional factors across the entire images. To represent universal emotional priors, we build the continuous emotional spectrum and extract nuanced emotional requests. To manipulate emotional factors, we design the emotional mapper to translate visually-abstract emotional requests to visually-concrete semantic representations. To ensure that editing results evoke specific emotions, we introduce an MLLM to supervise the model training. During inference, we strategically distort visual elements and subsequently shape corresponding emotional factors to edit images according to users' instructions. Additionally, we introduce a large-scale dataset that includes the emotion-aligned text and image pair set for training and evaluation. Extensive experiments demonstrate that AIEdiT achieves superior performance, effectively reflecting users' emotional requests.
VIRES: Video Instance Repainting with Sketch and Text Guidance
Nov 26, 2024



We introduce VIRES, a video instance repainting method with sketch and text guidance, enabling video instance repainting, replacement, generation, and removal. Existing approaches struggle with temporal consistency and accurate alignment with the provided sketch sequence. VIRES leverages the generative priors of text-to-video models to maintain temporal consistency and produce visually pleasing results. We propose the Sequential ControlNet with the standardized self-scaling, which effectively extracts structure layouts and adaptively captures high-contrast sketch details. We further augment the diffusion transformer backbone with the sketch attention to interpret and inject fine-grained sketch semantics. A sketch-aware encoder ensures that repainted results are aligned with the provided sketch sequence. Additionally, we contribute the VireSet, a dataset with detailed annotations tailored for training and evaluating video instance editing methods. Experimental results demonstrate the effectiveness of VIRES, which outperforms state-of-the-art methods in visual quality, temporal consistency, condition alignment, and human ratings. Project page:https://suimuc.github.io/suimu.github.io/projects/VIRES/
L-C4: Language-Based Video Colorization for Creative and Consistent Color
Oct 07, 2024



Automatic video colorization is inherently an ill-posed problem because each monochrome frame has multiple optional color candidates. Previous exemplar-based video colorization methods restrict the user's imagination due to the elaborate retrieval process. Alternatively, conditional image colorization methods combined with post-processing algorithms still struggle to maintain temporal consistency. To address these issues, we present Language-based video Colorization for Creative and Consistent Colors (L-C4) to guide the colorization process using user-provided language descriptions. Our model is built upon a pre-trained cross-modality generative model, leveraging its comprehensive language understanding and robust color representation abilities. We introduce the cross-modality pre-fusion module to generate instance-aware text embeddings, enabling the application of creative colors. Additionally, we propose temporally deformable attention to prevent flickering or color shifts, and cross-clip fusion to maintain long-term color consistency. Extensive experimental results demonstrate that L-C4 outperforms relevant methods, achieving semantically accurate colors, unrestricted creative correspondence, and temporally robust consistency.
Language-guided Image Reflection Separation
Feb 19, 2024This paper studies the problem of language-guided reflection separation, which aims at addressing the ill-posed reflection separation problem by introducing language descriptions to provide layer content. We propose a unified framework to solve this problem, which leverages the cross-attention mechanism with contrastive learning strategies to construct the correspondence between language descriptions and image layers. A gated network design and a randomized training strategy are employed to tackle the recognizable layer ambiguity. The effectiveness of the proposed method is validated by the significant performance advantage over existing reflection separation methods on both quantitative and qualitative comparisons.
Colorizing Monochromatic Radiance Fields
Feb 19, 2024



Though Neural Radiance Fields (NeRF) can produce colorful 3D representations of the world by using a set of 2D images, such ability becomes non-existent when only monochromatic images are provided. Since color is necessary in representing the world, reproducing color from monochromatic radiance fields becomes crucial. To achieve this goal, instead of manipulating the monochromatic radiance fields directly, we consider it as a representation-prediction task in the Lab color space. By first constructing the luminance and density representation using monochromatic images, our prediction stage can recreate color representation on the basis of an image colorization module. We then reproduce a colorful implicit model through the representation of luminance, density, and color. Extensive experiments have been conducted to validate the effectiveness of our approaches. Our project page: https://liquidammonia.github.io/color-nerf.