 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoWan: Lifting Diffusion Video Generation Models to 360° with Latitude/Longitude-aware Mechanisms
May 28, 2025Panoramic video generation enables immersive 360{\deg} content creation, valuable in applications that demand scene-consistent world exploration. However, existing panoramic video generation models struggle to leverage pre-trained generative priors from conventional text-to-video models for high-quality and diverse panoramic videos generation, due to limited dataset scale and the gap in spatial feature representations. In this paper, we introduce PanoWan to effectively lift pre-trained text-to-video models to the panoramic domain, equipped with minimal modules. PanoWan employs latitude-aware sampling to avoid latitudinal distortion, while its rotated semantic denoising and padded pixel-wise decoding ensure seamless transitions at longitude boundaries. To provide sufficient panoramic videos for learning these lifted representations, we contribute PanoVid, a high-quality panoramic video dataset with captions and diverse scenarios. Consequently, PanoWan achieves state-of-the-art performance in panoramic video generation and demonstrates robustness for zero-shot downstream tasks.
Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
Feb 28, 2025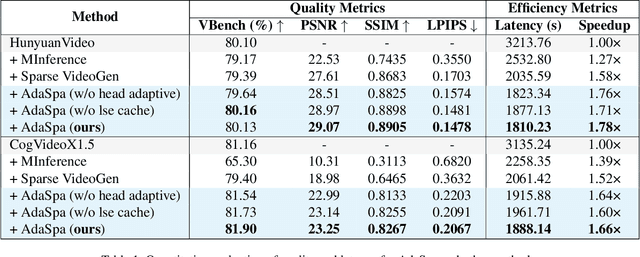
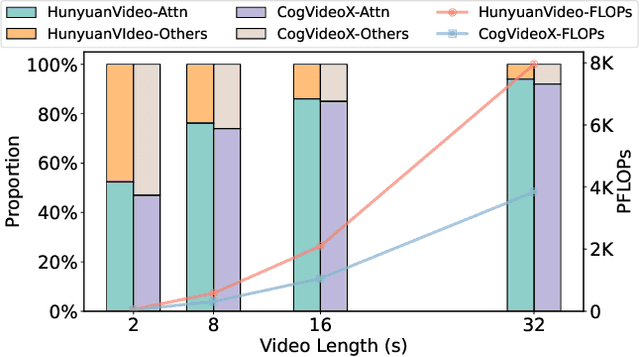
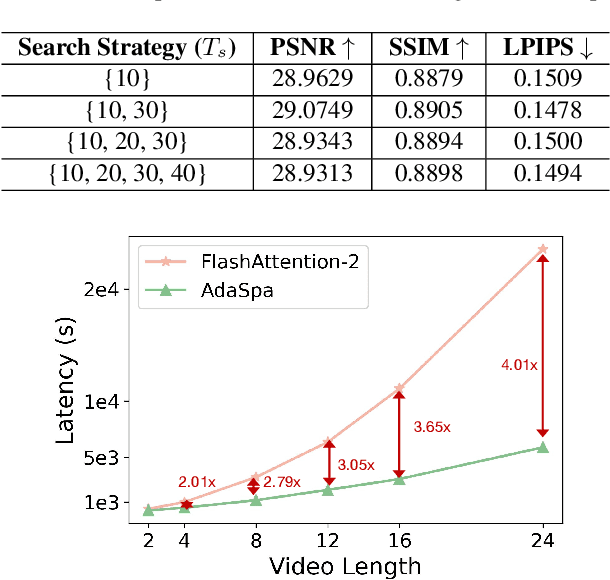
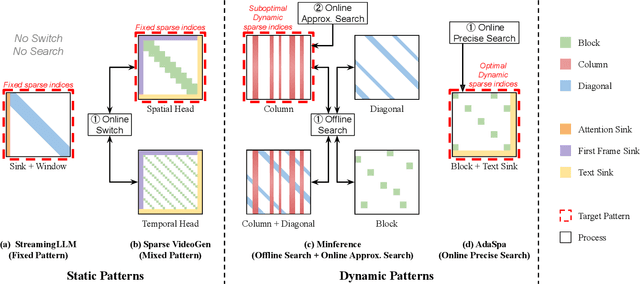
Generating high-fidelity long videos with Diffusion Transformers (DiTs) is often hindered by significant latency, primarily due to the computational demands of attention mechanisms. For instance, generating an 8-second 720p video (110K tokens) with HunyuanVideo takes about 600 PFLOPs, with around 500 PFLOPs consumed by attention computations. To address this issue, we propose AdaSpa, the first Dynamic Pattern and Online Precise Search sparse attention method. Firstly, to realize the Dynamic Pattern, we introduce a blockified pattern to efficiently capture the hierarchical sparsity inherent in DiTs. This is based on our observation that sparse characteristics of DiTs exhibit hierarchical and blockified structures between and within different modalities. This blockified approach significantly reduces the complexity of attention computation while maintaining high fidelity in the generated videos. Secondly, to enable Online Precise Search, we propose the Fused LSE-Cached Search with Head-adaptive Hierarchical Block Sparse Attention. This method is motivated by our finding that DiTs' sparse pattern and LSE vary w.r.t. inputs, layers, and heads, but remain invariant across denoising steps. By leveraging this invariance across denoising steps, it adapts to the dynamic nature of DiTs and allows for precise, real-time identification of sparse indices with minimal overhead. AdaSpa is implemented as an adaptive, plug-and-play solution and can be integrated seamlessly with existing DiTs, requiring neither additional fine-tuning nor a dataset-dependent profiling. Extensive experiments validate that AdaSpa delivers substantial acceleration across various models while preserving video quality, establishing itself as a robust and scalable approach to efficient video generation.
Reconstructing Satellites in 3D from Amateur Telescope Images
Apr 29, 2024

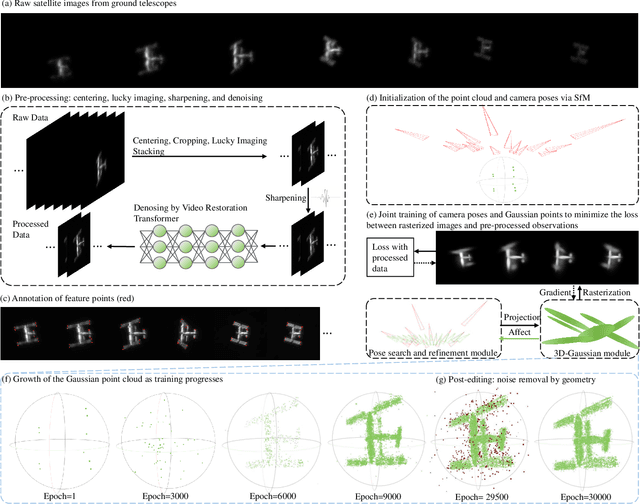
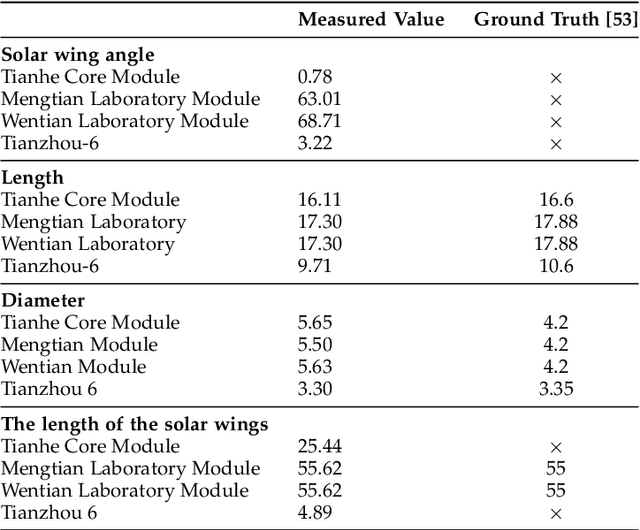
This paper proposes a framework for the 3D reconstruction of satellites in low-Earth orbit, utilizing videos captured by small amateur telescopes. The video data obtained from these telescopes differ significantly from data for standard 3D reconstruction tasks, characterized by intense motion blur, atmospheric turbulence, pervasive background light pollution, extended focal length and constrained observational perspectives. To address these challenges, our approach begins with a comprehensive pre-processing workflow that encompasses deep learning-based image restoration, feature point extraction and camera pose initialization. We proceed with the application of an improved 3D Gaussian splatting algorithm for reconstructing the 3D model. Our technique supports simultaneous 3D Gaussian training and pose estimation, enabling the robust generation of intricate 3D point clouds from sparse, noisy data. The procedure is further bolstered by a post-editing phase designed to eliminate noise points inconsistent with our prior knowledge of a satellite's geometric constraints. We validate our approach using both synthetic datasets and actual observations of China's Space Station, showcasing its significant advantages over existing methods in reconstructing 3D space objects from ground-based observations.