 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free and Adaptive Sparse Attention for Efficient Long Video Generation
Feb 28, 2025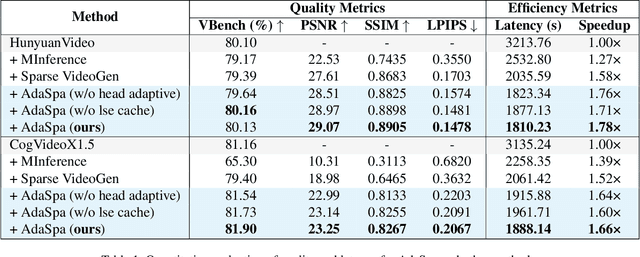
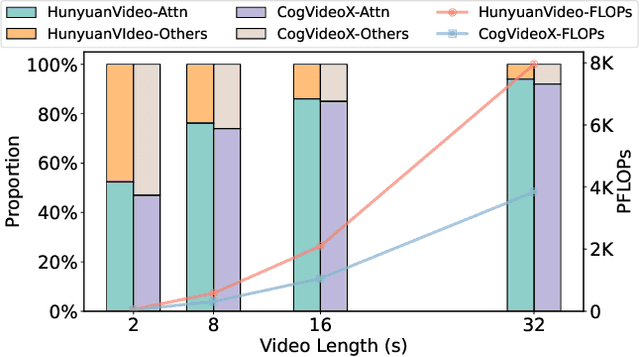
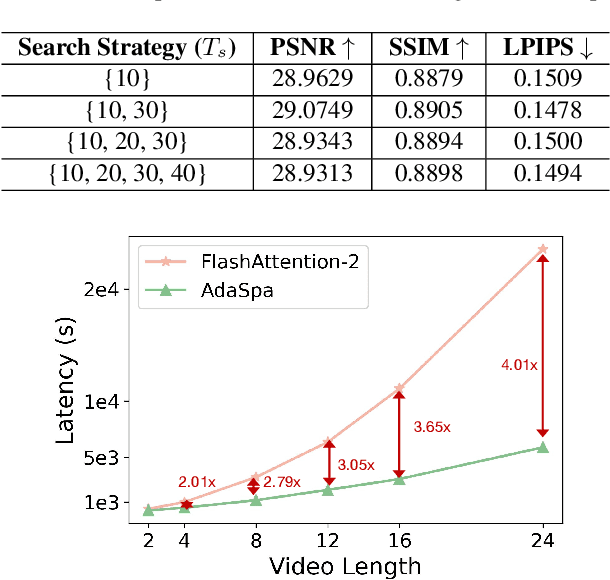
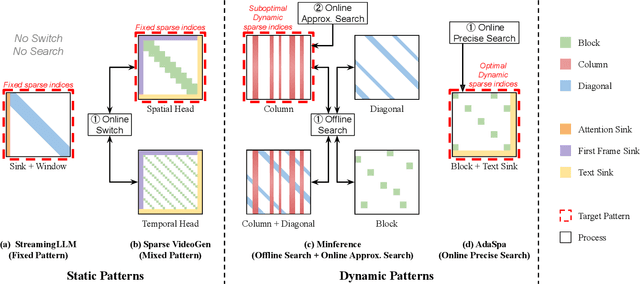
Generating high-fidelity long videos with Diffusion Transformers (DiTs) is often hindered by significant latency, primarily due to the computational demands of attention mechanisms. For instance, generating an 8-second 720p video (110K tokens) with HunyuanVideo takes about 600 PFLOPs, with around 500 PFLOPs consumed by attention computations. To address this issue, we propose AdaSpa, the first Dynamic Pattern and Online Precise Search sparse attention method. Firstly, to realize the Dynamic Pattern, we introduce a blockified pattern to efficiently capture the hierarchical sparsity inherent in DiTs. This is based on our observation that sparse characteristics of DiTs exhibit hierarchical and blockified structures between and within different modalities. This blockified approach significantly reduces the complexity of attention computation while maintaining high fidelity in the generated videos. Secondly, to enable Online Precise Search, we propose the Fused LSE-Cached Search with Head-adaptive Hierarchical Block Sparse Attention. This method is motivated by our finding that DiTs' sparse pattern and LSE vary w.r.t. inputs, layers, and heads, but remain invariant across denoising steps. By leveraging this invariance across denoising steps, it adapts to the dynamic nature of DiTs and allows for precise, real-time identification of sparse indices with minimal overhead. AdaSpa is implemented as an adaptive, plug-and-play solution and can be integrated seamlessly with existing DiTs, requiring neither additional fine-tuning nor a dataset-dependent profiling. Extensive experiments validate that AdaSpa delivers substantial acceleration across various models while preserving video quality, establishing itself as a robust and scalable approach to efficient video generation.
Articulated Object Manipulation with Coarse-to-fine Affordance for Mitigating the Effect of Point Cloud Noise
Mar 07, 20243D articulated objects are inherently challenging for manipulation due to the varied geometries and intricate functionalities associated with articulated objects.Point-level affordance, which predicts the per-point actionable score and thus proposes the best point to interact with, has demonstrated excellent performance and generalization capabilities in articulated object manipulation. However, a significant challenge remains: while previous works use perfect point cloud generated in simulation, the models cannot directly apply to the noisy point cloud in the real-world. To tackle this challenge, we leverage the property of real-world scanned point cloud that, the point cloud becomes less noisy when the camera is closer to the object. Therefore, we propose a novel coarse-to-fine affordance learning pipeline to mitigate the effect of point cloud noise in two stages. In the first stage, we learn the affordance on the noisy far point cloud which includes the whole object to propose the approximated place to manipulate. Then, we move the camera in front of the approximated place, scan a less noisy point cloud containing precise local geometries for manipulation, and learn affordance on such point cloud to propose fine-grained final actions. The proposed method is thoroughly evaluated both using large-scale simulated noisy point clouds mimicking real-world scans, and in the real world scenarios, with superiority over existing methods, demonstrating the effectiveness in tackling the noisy real-world point cloud problem.