 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Fairness in Recruitment AI via Information Flow
Nov 16, 2025

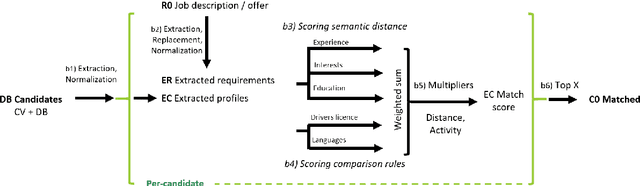

Avoiding bias and understanding the real-world consequences of AI-supported decision-making are critical to address fairness and assign accountability. Existing approaches often focus either on technical aspects, such as datasets and models, or on high-level socio-ethical considerations - rarely capturing how these elements interact in practice. In this paper, we apply an information flow-based modeling framework to a real-world recruitment process that integrates automated candidate matching with human decision-making. Through semi-structured stakeholder interviews and iterative modeling, we construct a multi-level representation of the recruitment pipeline, capturing how information is transformed, filtered, and interpreted across both algorithmic and human components. We identify where biases may emerge, how they can propagate through the system, and what downstream impacts they may have on candidates. This case study illustrates how information flow modeling can support structured analysis of fairness risks, providing transparency across complex socio-technical systems.
Towards Practical Defect-Focused Automated Code Review
May 23, 2025
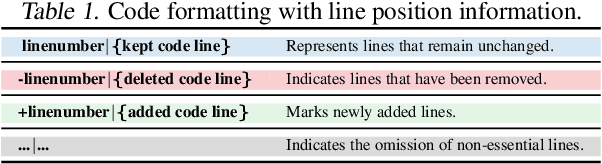
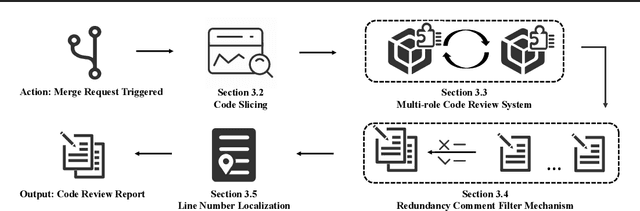
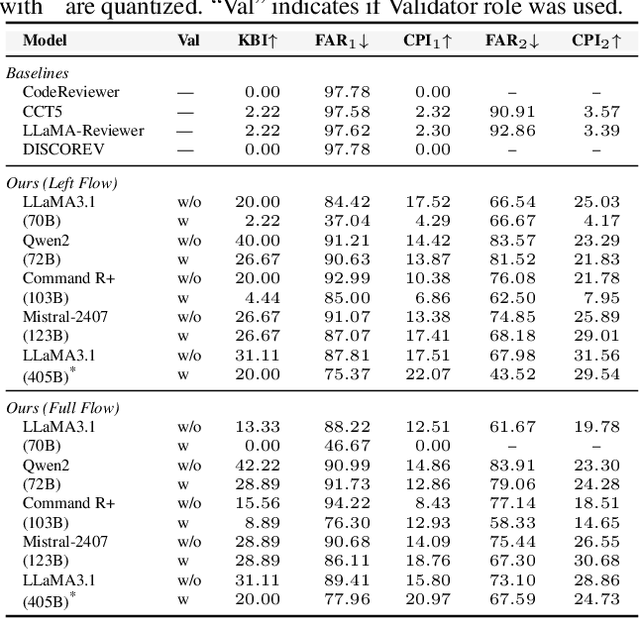
The complexity of code reviews has driven efforts to automate review comments, but prior approaches oversimplify this task by treating it as snippet-level code-to-text generation and relying on text similarity metrics like BLEU for evaluation. These methods overlook repository context, real-world merge request evaluation, and defect detection, limiting their practicality. To address these issues, we explore the full automation pipeline within the online recommendation service of a company with nearly 400 million daily active users, analyzing industry-grade C++ codebases comprising hundreds of thousands of lines of code. We identify four key challenges: 1) capturing relevant context, 2) improving key bug inclusion (KBI), 3) reducing false alarm rates (FAR), and 4) integrating human workflows. To tackle these, we propose 1) code slicing algorithms for context extraction, 2) a multi-role LLM framework for KBI, 3) a filtering mechanism for FAR reduction, and 4) a novel prompt design for better human interaction. Our approach, validated on real-world merge requests from historical fault reports, achieves a 2x improvement over standard LLMs and a 10x gain over previous baselines. While the presented results focus on C++, the underlying framework design leverages language-agnostic principles (e.g., AST-based analysis), suggesting potential for broader applicability.
Multimodal Graph Learning for Modeling Emerging Pandemics with Big Data
Oct 23, 2023Accurate forecasting and analysis of emerging pandemics play a crucial role in effective public health management and decision-making. Traditional approaches primarily rely on epidemiological data, overlooking other valuable sources of information that could act as sensors or indicators of pandemic patterns. In this paper, we propose a novel framework called MGL4MEP that integrates temporal graph neural networks and multi-modal data for learning and forecasting. We incorporate big data sources, including social media content, by utilizing specific pre-trained language models and discovering the underlying graph structure among users. This integration provides rich indicators of pandemic dynamics through learning with temporal graph neural networks. Extensive experiments demonstrate the effectiveness of our framework in pandemic forecasting and analysis, outperforming baseline methods across different areas, pandemic situations, and prediction horizons. The fusion of temporal graph learning and multi-modal data enables a comprehensive understanding of the pandemic landscape with less time lag, cheap cost, and more potential information indicators.
Few-Shot Nested Named Entity Recognition
Dec 02, 2022



While Named Entity Recognition (NER) is a widely studied task, making inferences of entities with only a few labeled data has been challenging, especially for entities with nested structures. Unlike flat entities, entities and their nested entities are more likely to have similar semantic feature representations, drastically increasing difficulties in classifying different entity categories in the few-shot setting. Although prior work has briefly discussed nested structures in the context of few-shot learning, to our best knowledge, this paper is the first one specifically dedicated to studying the few-shot nested NER task. Leveraging contextual dependency to distinguish nested entities, we propose a Biaffine-based Contrastive Learning (BCL) framework. We first design a Biaffine span representation module for learning the contextual span dependency representation for each entity span rather than only learning its semantic representation. We then merge these two representations by the residual connection to distinguish nested entities. Finally, we build a contrastive learning framework to adjust the representation distribution for larger margin boundaries and more generalized domain transfer learning ability. We conducted experimental studies on three English, German, and Russian nested NER datasets. The results show that the BCL outperformed three baseline models on the 1-shot and 5-shot tasks in terms of F1 score.
Generic Multilayer Network Data Analysis with the Fusion of Content and Structure
May 21, 2019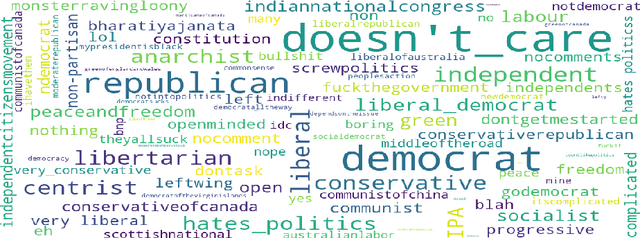

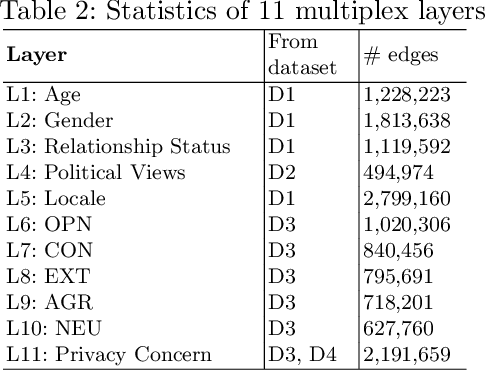
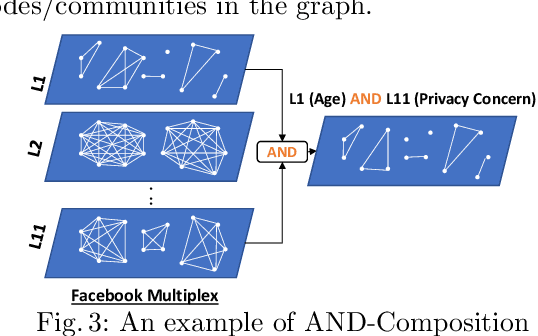
Multi-feature data analysis (e.g., on Facebook, LinkedIn) is challenging especially if one wants to do it efficiently and retain the flexibility by choosing features of interest for analysis. Features (e.g., age, gender, relationship, political view etc.) can be explicitly given from datasets, but also can be derived from content (e.g., political view based on Facebook posts). Analysis from multiple perspectives is needed to understand the datasets (or subsets of it) and to infer meaningful knowledge. For example, the influence of age, location, and marital status on political views may need to be inferred separately (or in combination). In this paper, we adapt multilayer network (MLN) analysis, a nontraditional approach, to model the Facebook datasets, integrate content analysis, and conduct analysis, which is driven by a list of desired application based queries. Our experimental analysis shows the flexibility and efficiency of the proposed approach when modeling and analyzing datasets with multiple features.
* 18 pages
dpUGC: Learn Differentially Private Representation for User Generated Contents
Mar 25, 2019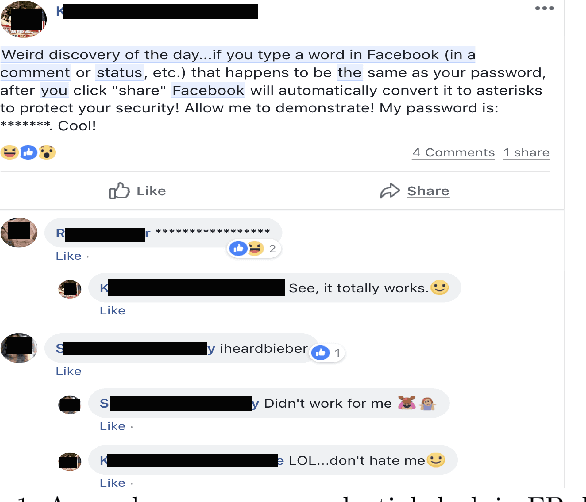
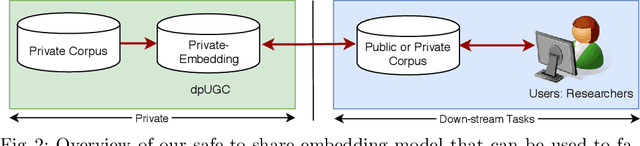

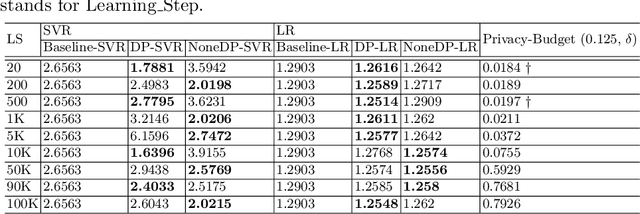
This paper firstly proposes a simple yet efficient generalized approach to apply differential privacy to text representation (i.e., word embedding). Based on it, we propose a user-level approach to learn personalized differentially private word embedding model on user generated contents (UGC). To our best knowledge, this is the first work of learning user-level differentially private word embedding model from text for sharing. The proposed approaches protect the privacy of the individual from re-identification, especially provide better trade-off of privacy and data utility on UGC data for sharing. The experimental results show that the trained embedding models are applicable for the classic text analysis tasks (e.g., regression). Moreover, the proposed approaches of learning differentially private embedding models are both framework- and data- independent, which facilitates the deployment and sharing. The source code is available at https://github.com/sonvx/dpText.
ETNLP: A Toolkit for Extraction, Evaluation and Visualization of Pre-trained Word Embeddings
Mar 11, 2019


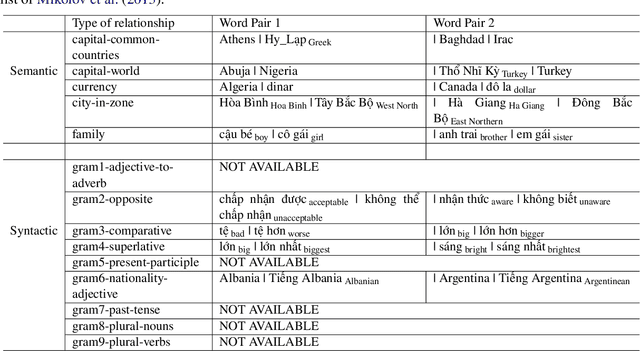
In this paper, we introduce a comprehensive toolkit, ETNLP, which can evaluate, extract, and visualize multiple sets of pre-trained word embeddings. First, for evaluation, ETNLP analyses the quality of pre-trained embeddings based on an input word analogy list. Second, for extraction ETNLP provides a subset of the embeddings to be used in the downstream NLP tasks. Finally, ETNLP has a visualization module which is for exploring the embedded words interactively. We demonstrate the effectiveness of ETNLP on our pre-trained word embeddings in Vietnamese. Specifically, we create a large Vietnamese word analogy list to evaluate the embeddings. We then utilize the pre-trained embeddings for the name entity recognition (NER) task in Vietnamese and achieve the new state-of-the-art results on a benchmark dataset for the NER task. A video demonstration of ETNLP is available at https://vimeo.com/317599106. The source code and data are available at https: //github.com/vietnlp/etnlp.
Self-adaptive Privacy Concern Detection for User-generated Content
Jun 19, 2018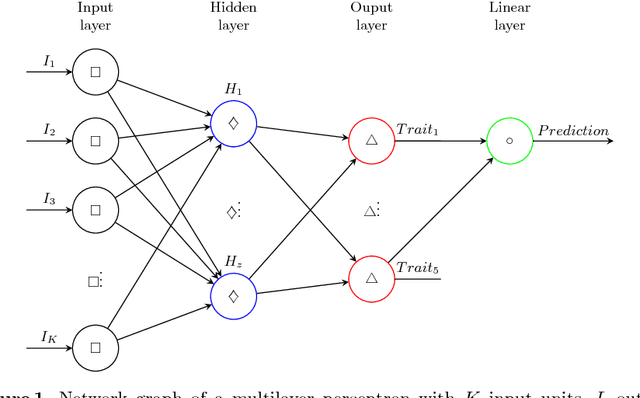


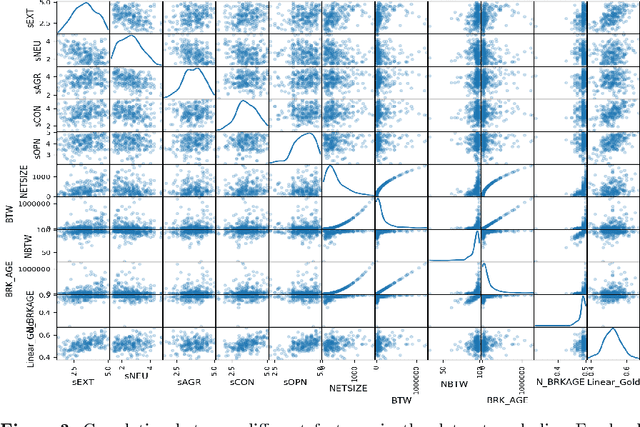
To protect user privacy in data analysis, a state-of-the-art strategy is differential privacy in which scientific noise is injected into the real analysis output. The noise masks individual's sensitive information contained in the dataset. However, determining the amount of noise is a key challenge, since too much noise will destroy data utility while too little noise will increase privacy risk. Though previous research works have designed some mechanisms to protect data privacy in different scenarios, most of the existing studies assume uniform privacy concerns for all individuals. Consequently, putting an equal amount of noise to all individuals leads to insufficient privacy protection for some users, while over-protecting others. To address this issue, we propose a self-adaptive approach for privacy concern detection based on user personality. Our experimental studies demonstrate the effectiveness to address a suitable personalized privacy protection for cold-start users (i.e., without their privacy-concern information in training data).
Lexical-semantic resources: yet powerful resources for automatic personality classification
Nov 27, 2017
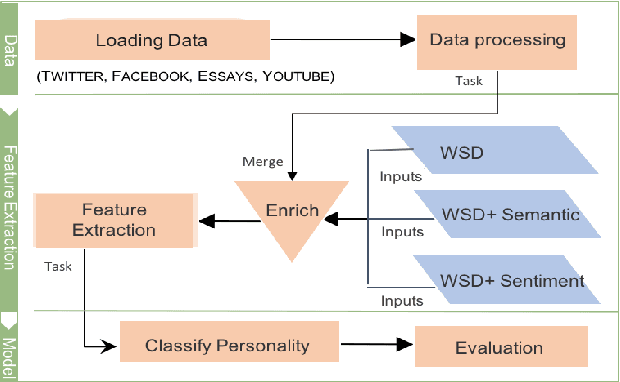

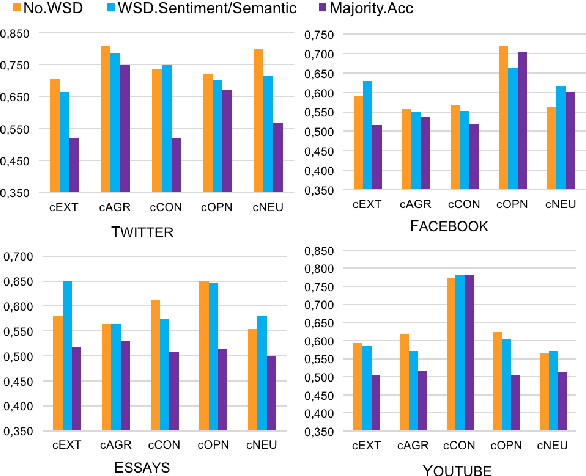
In this paper, we aim to reveal the impact of lexical-semantic resources, used in particular for word sense disambiguation and sense-level semantic categorization, on automatic personality classification task. While stylistic features (e.g., part-of-speech counts) have been shown their power in this task, the impact of semantics beyond targeted word lists is relatively unexplored. We propose and extract three types of lexical-semantic features, which capture high-level concepts and emotions, overcoming the lexical gap of word n-grams. Our experimental results are comparable to state-of-the-art methods, while no personality-specific resources are required.