 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-Based Risk Feature Discovery in Document Structure Spaces under a Constrained Budget
Jan 29, 2026Enterprise-grade Intelligent Document Processing (IDP) systems support high-stakes workflows across finance, insurance, and healthcare. Early-phase system validation under limited budgets mandates uncovering diverse failure mechanisms, rather than identifying a single worst-case document. We formalize this challenge as a Search-Based Software Testing (SBST) problem, aiming to identify complex interactions between document variables, with the objective to maximize the number of distinct failure types discovered within a fixed evaluation budget. Our methodology operates on a combinatorial space of document configurations, rendering instances of structural \emph{risk features} to induce realistic failure conditions. We benchmark a diverse portfolio of search strategies spanning evolutionary, swarm-based, quality-diversity, learning-based, and quantum under identical budget constraints. Through configuration-level exclusivity, win-rate, and cross-temporal overlap analyses, we show that different solvers consistently uncover failure modes that remain undiscovered by specific alternatives at comparable budgets. Crucially, cross-temporal analysis reveals persistent solver-specific discoveries across all evaluated budgets, with no single strategy exhibiting absolute dominance. While the union of all solvers eventually recovers the observed failure space, reliance on any individual method systematically delays the discovery of important risks. These results demonstrate intrinsic solver complementarity and motivate portfolio-based SBST strategies for robust industrial IDP validation.
Intelligent Human-Machine Partnership for Manufacturing: Enhancing Warehouse Planning through Simulation-Driven Knowledge Graphs and LLM Collaboration
Dec 20, 2025Manufacturing planners face complex operational challenges that require seamless collaboration between human expertise and intelligent systems to achieve optimal performance in modern production environments. Traditional approaches to analyzing simulation-based manufacturing data often create barriers between human decision-makers and critical operational insights, limiting effective partnership in manufacturing planning. Our framework establishes a collaborative intelligence system integrating Knowledge Graphs and Large Language Model-based agents to bridge this gap, empowering manufacturing professionals through natural language interfaces for complex operational analysis. The system transforms simulation data into semantically rich representations, enabling planners to interact naturally with operational insights without specialized expertise. A collaborative LLM agent works alongside human decision-makers, employing iterative reasoning that mirrors human analytical thinking while generating precise queries for knowledge extraction and providing transparent validation. This partnership approach to manufacturing bottleneck identification, validated through operational scenarios, demonstrates enhanced performance while maintaining human oversight and decision authority. For operational inquiries, the system achieves near-perfect accuracy through natural language interaction. For investigative scenarios requiring collaborative analysis, we demonstrate the framework's effectiveness in supporting human experts to uncover interconnected operational issues that enhance understanding and decision-making. This work advances collaborative manufacturing by creating intuitive methods for actionable insights, reducing cognitive load while amplifying human analytical capabilities in evolving manufacturing ecosystems.
Thinking in Many Modes: How Composite Reasoning Elevates Large Language Model Performance with Limited Data
Sep 26, 2025
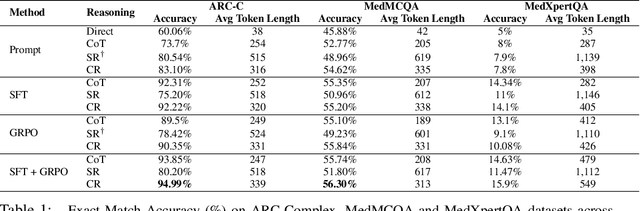
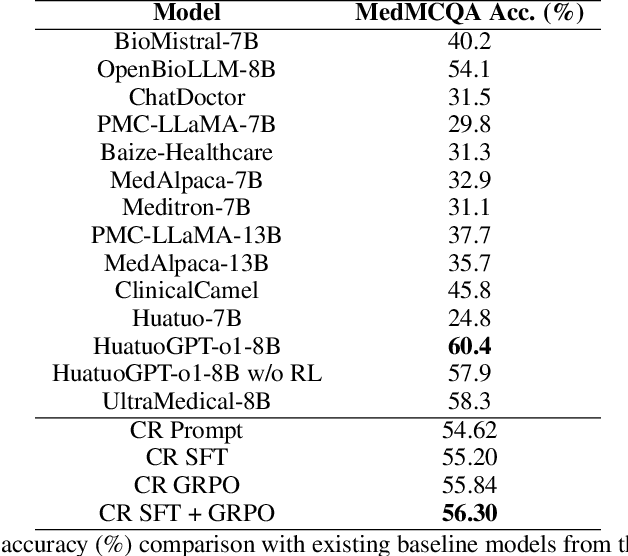
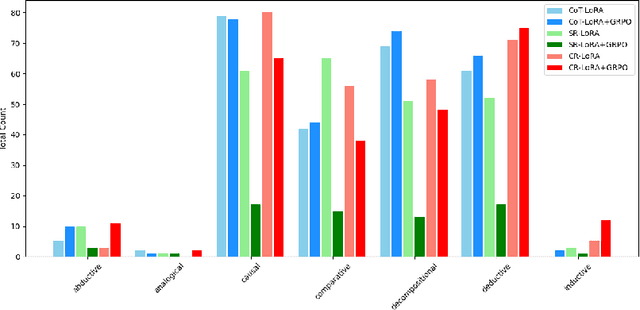
Large Language Models (LLMs), despite their remarkable capabilities, rely on singular, pre-dominant reasoning paradigms, hindering their performance on intricate problems that demand diverse cognitive strategies. To address this, we introduce Composite Reasoning (CR), a novel reasoning approach empowering LLMs to dynamically explore and combine multiple reasoning styles like deductive, inductive, and abductive for more nuanced problem-solving. Evaluated on scientific and medical question-answering benchmarks, our approach outperforms existing baselines like Chain-of-Thought (CoT) and also surpasses the accuracy of DeepSeek-R1 style reasoning (SR) capabilities, while demonstrating superior sample efficiency and adequate token usage. Notably, CR adaptively emphasizes domain-appropriate reasoning styles. It prioritizes abductive and deductive reasoning for medical question answering, but shifts to causal, deductive, and inductive methods for scientific reasoning. Our findings highlight that by cultivating internal reasoning style diversity, LLMs acquire more robust, adaptive, and efficient problem-solving abilities.
Leveraging Knowledge Graphs and LLM Reasoning to Identify Operational Bottlenecks for Warehouse Planning Assistance
Jul 23, 2025Analyzing large, complex output datasets from Discrete Event Simulations (DES) of warehouse operations to identify bottlenecks and inefficiencies is a critical yet challenging task, often demanding significant manual effort or specialized analytical tools. Our framework integrates Knowledge Graphs (KGs) and Large Language Model (LLM)-based agents to analyze complex Discrete Event Simulation (DES) output data from warehouse operations. It transforms raw DES data into a semantically rich KG, capturing relationships between simulation events and entities. An LLM-based agent uses iterative reasoning, generating interdependent sub-questions. For each sub-question, it creates Cypher queries for KG interaction, extracts information, and self-reflects to correct errors. This adaptive, iterative, and self-correcting process identifies operational issues mimicking human analysis. Our DES approach for warehouse bottleneck identification, tested with equipment breakdowns and process irregularities, outperforms baseline methods. For operational questions, it achieves near-perfect pass rates in pinpointing inefficiencies. For complex investigative questions, we demonstrate its superior diagnostic ability to uncover subtle, interconnected issues. This work bridges simulation modeling and AI (KG+LLM), offering a more intuitive method for actionable insights, reducing time-to-insight, and enabling automated warehouse inefficiency evaluation and diagnosis.
Minimizing Factual Inconsistency and Hallucination in Large Language Models
Nov 23, 2023Large Language Models (LLMs) are widely used in critical fields such as healthcare, education, and finance due to their remarkable proficiency in various language-related tasks. However, LLMs are prone to generating factually incorrect responses or "hallucinations," which can lead to a loss of credibility and trust among users. To address this issue, we propose a multi-stage framework that generates the rationale first, verifies and refines incorrect ones, and uses them as supporting references to generate the answer. The generated rationale enhances the transparency of the answer and our framework provides insights into how the model arrived at this answer, by using this rationale and the references to the context. In this paper, we demonstrate its effectiveness in improving the quality of responses to drug-related inquiries in the life sciences industry. Our framework improves traditional Retrieval Augmented Generation (RAG) by enabling OpenAI GPT-3.5-turbo to be 14-25% more faithful and 16-22% more accurate on two datasets. Furthermore, fine-tuning samples based on our framework improves the accuracy of smaller open-access LLMs by 33-42% and competes with RAG on commercial models.
Knowledge Capture and Replay for Continual Learning
Dec 12, 2020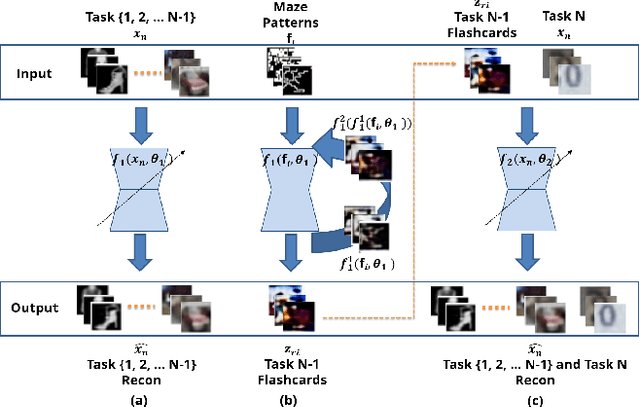
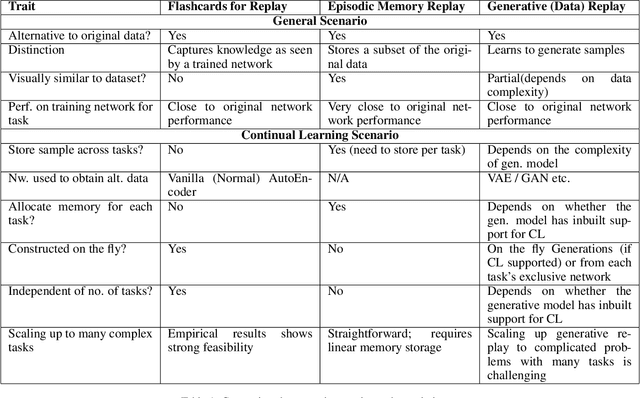
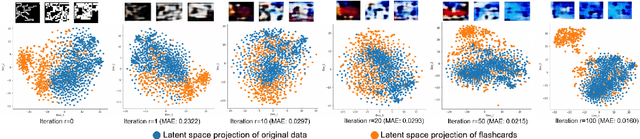
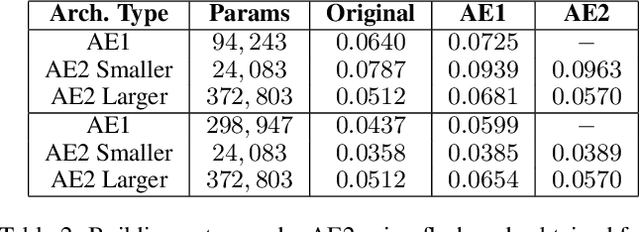
Deep neural networks have shown promise in several domains, and the learned task-specific information is implicitly stored in the network parameters. It will be vital to utilize representations from these networks for downstream tasks such as continual learning. In this paper, we introduce the notion of {\em flashcards} that are visual representations to {\em capture} the encoded knowledge of a network, as a function of random image patterns. We demonstrate the effectiveness of flashcards in capturing representations and show that they are efficient replay methods for general and task agnostic continual learning setting. Thus, while adapting to a new task, a limited number of constructed flashcards, help to prevent catastrophic forgetting of the previously learned tasks. Most interestingly, such flashcards neither require external memory storage nor need to be accumulated over multiple tasks and only need to be constructed just before learning the subsequent new task, irrespective of the number of tasks trained before and are hence task agnostic. We first demonstrate the efficacy of flashcards in capturing knowledge representation from a trained network, and empirically validate the efficacy of flashcards on a variety of continual learning tasks: continual unsupervised reconstruction, continual denoising, and new-instance learning classification, using a number of heterogeneous benchmark datasets. These studies also indicate that continual learning algorithms with flashcards as the replay strategy perform better than other state-of-the-art replay methods, and exhibits on par performance with the best possible baseline using coreset sampling, with the least additional computational complexity and storage.
Classification Representations Can be Reused for Downstream Generations
Apr 16, 2020
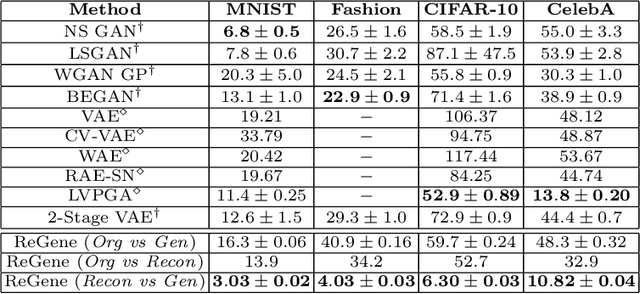
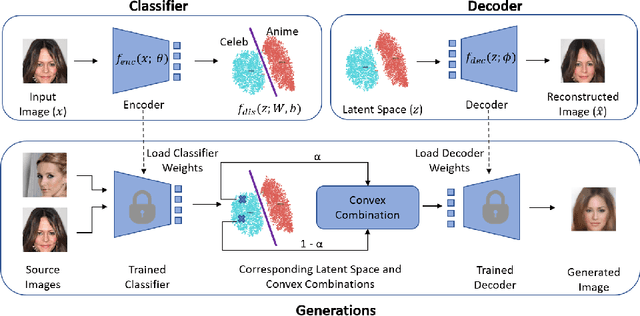

Contrary to the convention of using supervision for class-conditioned $\it{generative}$ $\it{modeling}$, this work explores and demonstrates the feasibility of a learned supervised representation space trained on a discriminative classifier for the $\it{downstream}$ task of sample generation. Unlike generative modeling approaches that aim to $\it{model}$ the manifold distribution, we directly $\it{represent}$ the given data manifold in the classification space and leverage properties of latent space representations to generate new representations that are guaranteed to be in the same class. Interestingly, such representations allow for controlled sample generations for any given class from existing samples and do not require enforcing prior distribution. We show that these latent space representations can be smartly manipulated (using convex combinations of $n$ samples, $n\geq2$) to yield meaningful sample generations. Experiments on image datasets of varying resolutions demonstrate that downstream generations have higher classification accuracy than existing conditional generative models while being competitive in terms of FID.