 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACT: Bridging the Gap in Code Translation through Synthetic Data Generation & Adaptive Training
Jul 22, 2025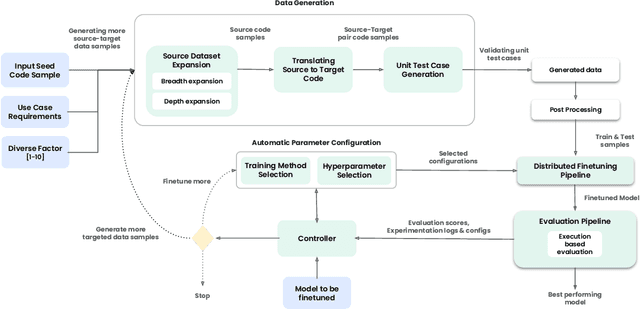



Code translation is a crucial process in software development and migration projects, enabling interoperability between different programming languages and enhancing software adaptability and thus longevity. Traditional automated translation methods rely heavily on handcrafted transformation rules, which often lack flexibility and scalability. Meanwhile, advanced language models present promising alternatives but are often limited by proprietary, API-based implementations that raise concerns over data security and reliance. In this paper, we present Auto-Train for Code Translation (ACT), an innovative framework that aims to improve code translation capabilities by enabling in-house finetuning of open-source Large Language Models (LLMs). ACT's automated pipeline significantly boosts the performance of these models, narrowing the gap between open-source accessibility and the high performance of closed-source solutions. Central to ACT is its synthetic data generation module, which builds extensive, high-quality datasets from initial code samples, incorporating unit tests to ensure functional accuracy and diversity. ACT's evaluation framework incorporates execution-level checks, offering a comprehensive assessment of translation quality. A key feature in ACT is its controller module, which manages the entire pipeline by dynamically adjusting hyperparameters, orchestrating iterative data generation, and finetuning based on real-time evaluations. This enables ACT to intelligently optimize when to continue training, generate additional targeted training data, or stop the process. Our results demonstrate that ACT consistently enhances the effectiveness of open-source models, offering businesses and developers a secure and reliable alternative. Additionally, applying our data generation pipeline to industry-scale migration projects has led to a notable increase in developer acceleration.
Minimizing Factual Inconsistency and Hallucination in Large Language Models
Nov 23, 2023



Large Language Models (LLMs) are widely used in critical fields such as healthcare, education, and finance due to their remarkable proficiency in various language-related tasks. However, LLMs are prone to generating factually incorrect responses or "hallucinations," which can lead to a loss of credibility and trust among users. To address this issue, we propose a multi-stage framework that generates the rationale first, verifies and refines incorrect ones, and uses them as supporting references to generate the answer. The generated rationale enhances the transparency of the answer and our framework provides insights into how the model arrived at this answer, by using this rationale and the references to the context. In this paper, we demonstrate its effectiveness in improving the quality of responses to drug-related inquiries in the life sciences industry. Our framework improves traditional Retrieval Augmented Generation (RAG) by enabling OpenAI GPT-3.5-turbo to be 14-25% more faithful and 16-22% more accurate on two datasets. Furthermore, fine-tuning samples based on our framework improves the accuracy of smaller open-access LLMs by 33-42% and competes with RAG on commercial models.
Large-Scale Knowledge Synthesis and Complex Information Retrieval from Biomedical Documents
Feb 14, 2023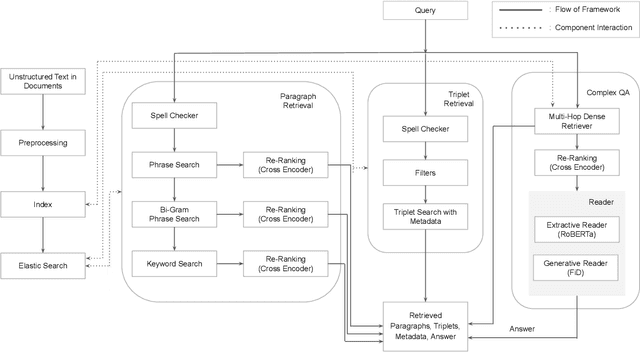

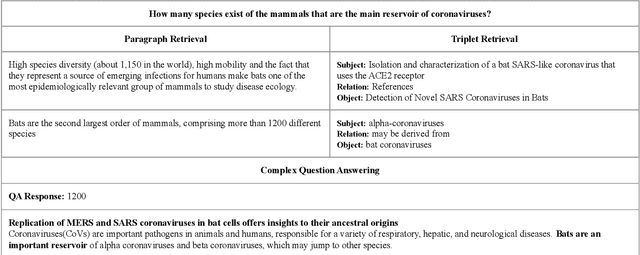
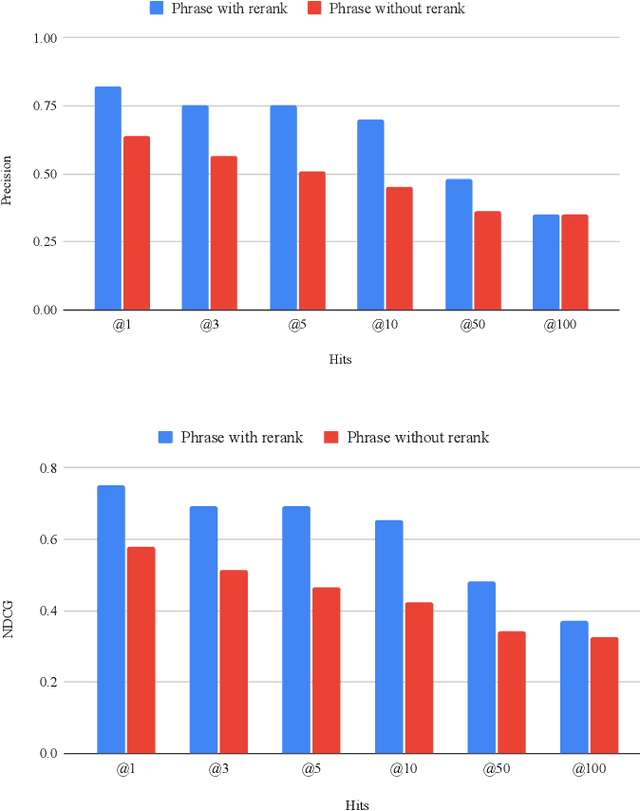
Recent advances in the healthcare industry have led to an abundance of unstructured data, making it challenging to perform tasks such as efficient and accurate information retrieval at scale. Our work offers an all-in-one scalable solution for extracting and exploring complex information from large-scale research documents, which would otherwise be tedious. First, we briefly explain our knowledge synthesis process to extract helpful information from unstructured text data of research documents. Then, on top of the knowledge extracted from the documents, we perform complex information retrieval using three major components- Paragraph Retrieval, Triplet Retrieval from Knowledge Graphs, and Complex Question Answering (QA). These components combine lexical and semantic-based methods to retrieve paragraphs and triplets and perform faceted refinement for filtering these search results. The complexity of biomedical queries and documents necessitates using a QA system capable of handling queries more complex than factoid queries, which we evaluate qualitatively on the COVID-19 Open Research Dataset (CORD-19) to demonstrate the effectiveness and value-add.
Image Matching Using SIFT, SURF, BRIEF and ORB: Performance Comparison for Distorted Images
Oct 07, 2017


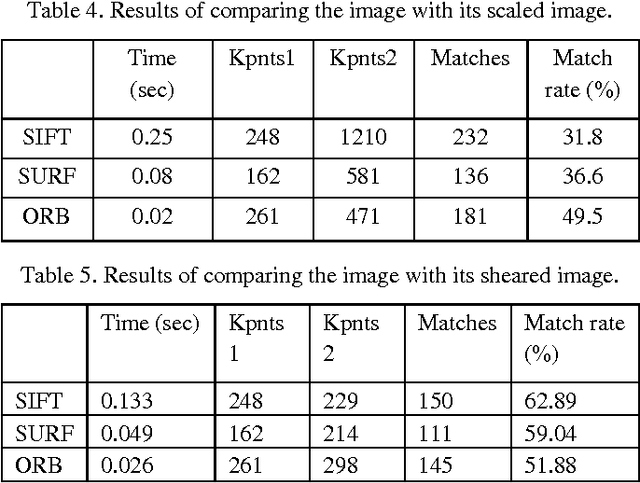
Fast and robust image matching is a very important task with various applications in computer vision and robotics. In this paper, we compare the performance of three different image matching techniques, i.e., SIFT, SURF, and ORB, against different kinds of transformations and deformations such as scaling, rotation, noise, fish eye distortion, and shearing. For this purpose, we manually apply different types of transformations on original images and compute the matching evaluation parameters such as the number of key points in images, the matching rate, and the execution time required for each algorithm and we will show that which algorithm is the best more robust against each kind of distortion. Index Terms-Image matching, scale invariant feature transform (SIFT), speed up robust feature (SURF), robust independent elementary features (BRIEF), oriented FAST, rotated BRIEF (ORB).