 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN-MoE: Context-Aware Patch Routing using GNNs for Parameter-Efficient Domain Generalization
Nov 06, 2025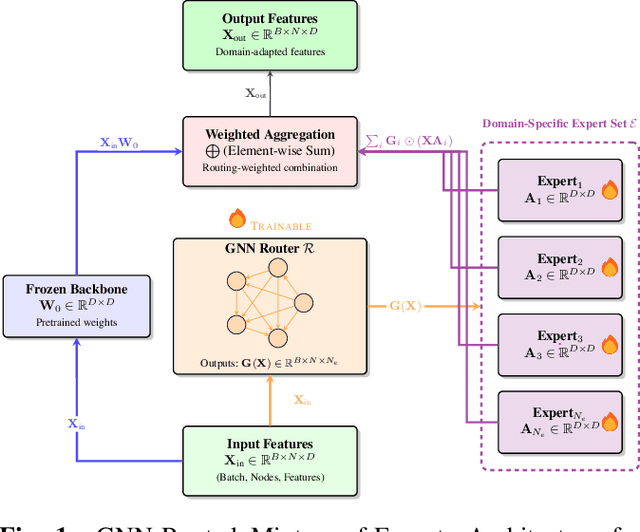
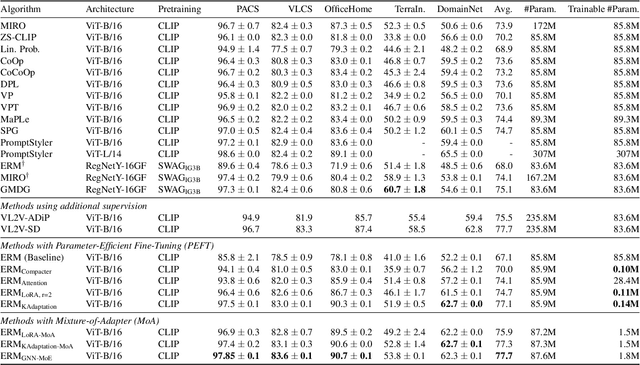

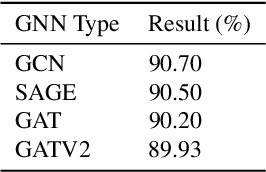
Domain generalization (DG) seeks robust Vision Transformer (ViT) performance on unseen domains. Efficiently adapting pretrained ViTs for DG is challenging; standard fine-tuning is costly and can impair generalization. We propose GNN-MoE, enhancing Parameter-Efficient Fine-Tuning (PEFT) for DG with a Mixture-of-Experts (MoE) framework using efficient Kronecker adapters. Instead of token-based routing, a novel Graph Neural Network (GNN) router (GCN, GAT, SAGE) operates on inter-patch graphs to dynamically assign patches to specialized experts. This context-aware GNN routing leverages inter-patch relationships for better adaptation to domain shifts. GNN-MoE achieves state-of-the-art or competitive DG benchmark performance with high parameter efficiency, highlighting the utility of graph-based contextual routing for robust, lightweight DG.
Beyond Traditional Single Object Tracking: A Survey
May 16, 2024



Single object tracking is a vital task of many applications in critical fields. However, it is still considered one of the most challenging vision tasks. In recent years, computer vision, especially object tracking, witnessed the introduction or adoption of many novel techniques, setting new fronts for performance. In this survey, we visit some of the cutting-edge techniques in vision, such as Sequence Models, Generative Models, Self-supervised Learning, Unsupervised Learning, Reinforcement Learning, Meta-Learning, Continual Learning, and Domain Adaptation, focusing on their application in single object tracking. We propose a novel categorization of single object tracking methods based on novel techniques and trends. Also, we conduct a comparative analysis of the performance reported by the methods presented on popular tracking benchmarks. Moreover, we analyze the pros and cons of the presented approaches and present a guide for non-traditional techniques in single object tracking. Finally, we suggest potential avenues for future research in single-object tracking.
Deep Machine Learning Based Egyptian Vehicle License Plate Recognition Systems
Jul 24, 2021

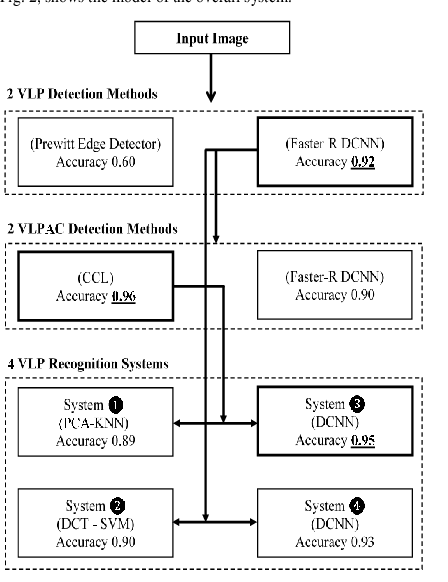
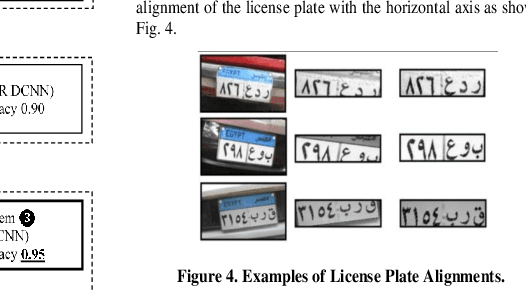
Automated Vehicle License Plate (VLP) detection and recognition have ended up being a significant research issue as of late. VLP localization and recognition are some of the most essential techniques for managing traffic using digital techniques. In this paper, four smart systems are developed to recognize Egyptian vehicles license plates. Two systems are based on character recognition, which are (System1, Characters Recognition with Classical Machine Learning) and (System2, Characters Recognition with Deep Machine Learning). The other two systems are based on the whole plate recognition which are (System3, Whole License Plate Recognition with Classical Machine Learning) and (System4, Whole License Plate Recognition with Deep Machine Learning). We use object detection algorithms, and machine learning based object recognition algorithms. The performance of the developed systems has been tested on real images, and the experimental results demonstrate that the best detection accuracy rate for VLP is provided by using the deep learning method. Where the VLP detection accuracy rate is better than the classical system by 32%. However, the best detection accuracy rate for Vehicle License Plate Arabic Character (VLPAC) is provided by using the classical method. Where VLPAC detection accuracy rate is better than the deep learning-based system by 6%. Also, the results show that deep learning is better than the classical technique used in VLP recognition processes. Where the recognition accuracy rate is better than the classical system by 8%. Finally, the paper output recommends a robust VLP recognition system based on both statistical and deep machine learning.
* 8 Pages, 20 Figures, 5 Tables, Published with Al-Azhar Engineering Fifteenth International Conference (AEIC 2021)
Vehicles Detection Based on Background Modeling
Jan 13, 2019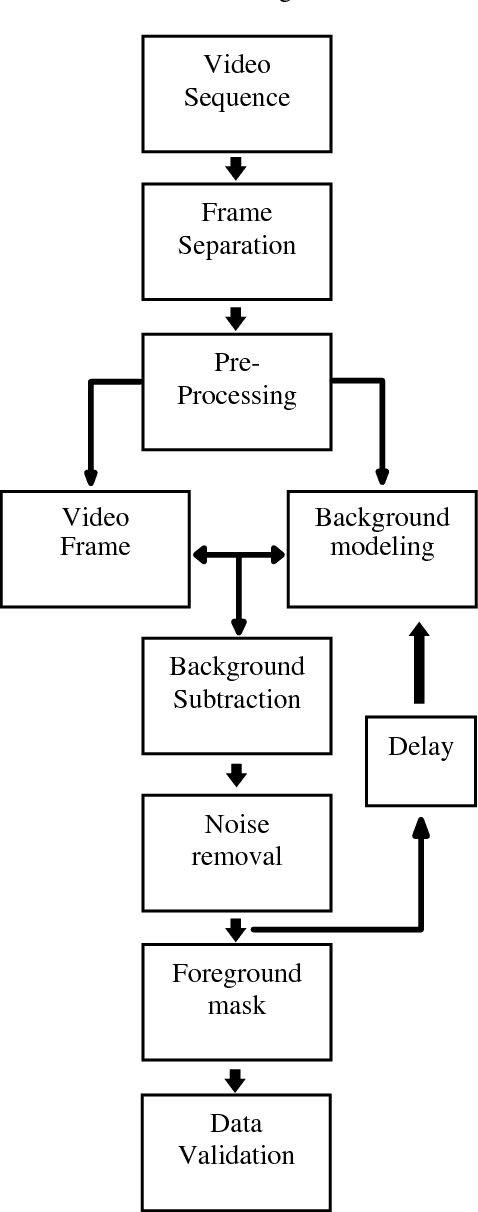
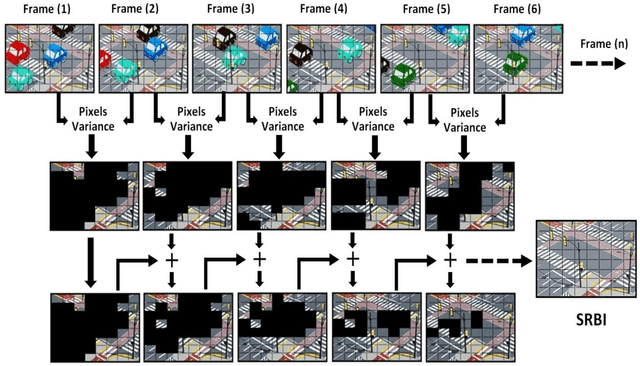


Background image subtraction algorithm is a common approach which detects moving objects in a video sequence by finding the significant difference between the video frames and the static background model. This paper presents a developed system which achieves vehicle detection by using background image subtraction algorithm based on blocks followed by deep learning data validation algorithm. The main idea is to segment the image into equal size blocks, to model the static reference background image (SRBI), by calculating the variance between each block pixels and each counterpart block pixels in the adjacent frame, the system implemented into four different methods: Absolute Difference, Image Entropy, Exclusive OR (XOR) and Discrete Cosine Transform (DCT). The experimental results showed that the DCT method has the highest vehicle detection accuracy.
* 4 pages, 4 figures
Estimation and Tracking of AP-diameter of the Inferior Vena Cava in Ultrasound Images Using a Novel Active Circle Algorithm
Aug 08, 2018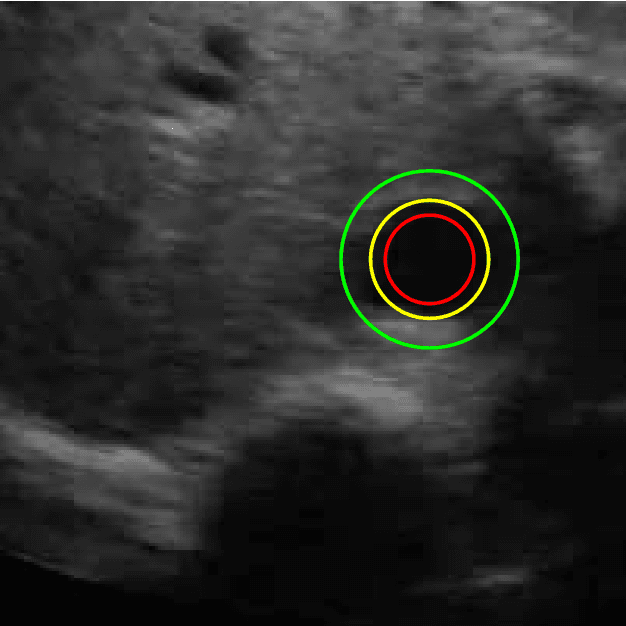
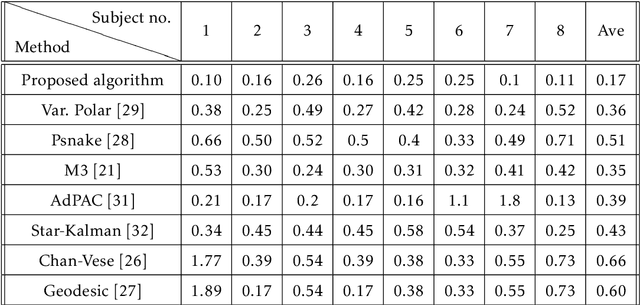
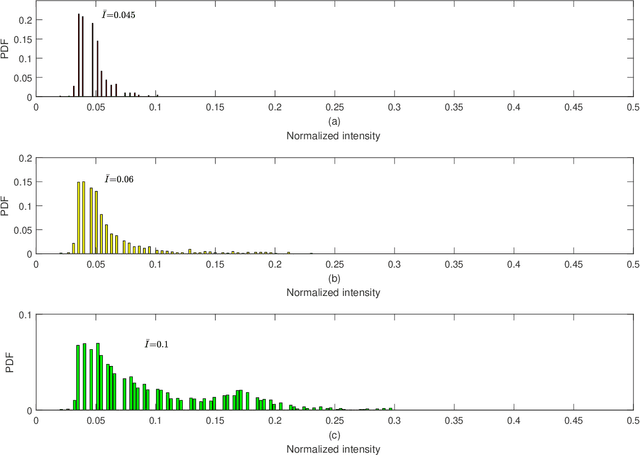
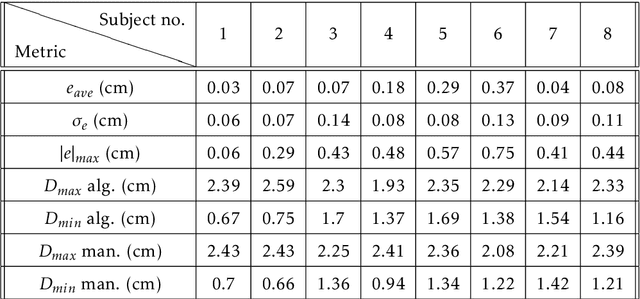
Medical research suggests that the anterior-posterior (AP)-diameter of the inferior vena cava (IVC) and its associated temporal variation as imaged by bedside ultrasound is useful in guiding fluid resuscitation of the critically-ill patient. Unfortunately, indistinct edges and gaps in vessel walls are frequently present which impede accurate estimation of the IVC AP-diameter for both human operators and segmentation algorithms. The majority of research involving use of the IVC to guide fluid resuscitation involves manual measurement of the maximum and minimum AP-diameter as it varies over time. This effort proposes using a time-varying circle fitted inside the typically ellipsoid IVC as an efficient, consistent and novel approach to tracking and approximating the AP-diameter even in the context of poor image quality. In this active-circle algorithm, a novel evolution functional is proposed and shown to be a useful tool for ultrasound image processing. The proposed algorithm is compared with an expert manual measurement, and state-of-the-art relevant algorithms. It is shown that the algorithm outperforms other techniques and performs very close to manual measurement.
* Published in Computers in Biology and Medicine
Adaptive Polar Active Contour for Segmentation and Tracking in Ultrasound Videos
Mar 19, 2018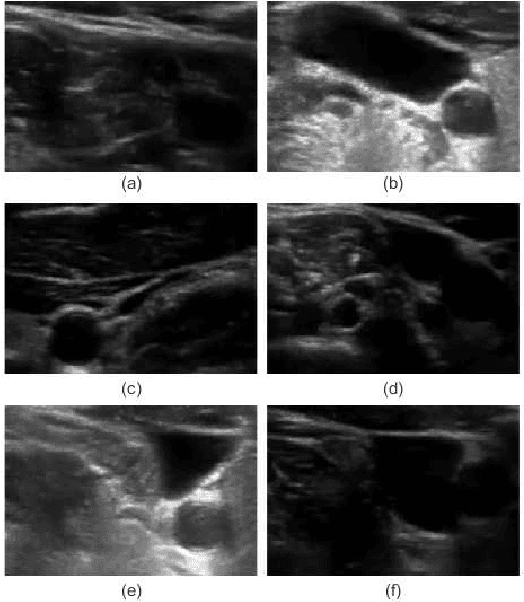
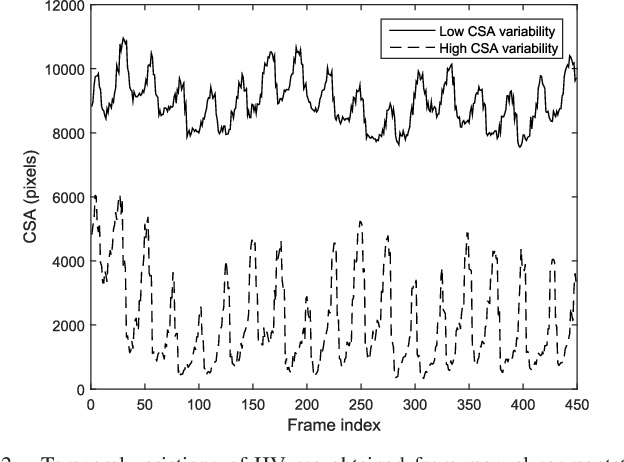
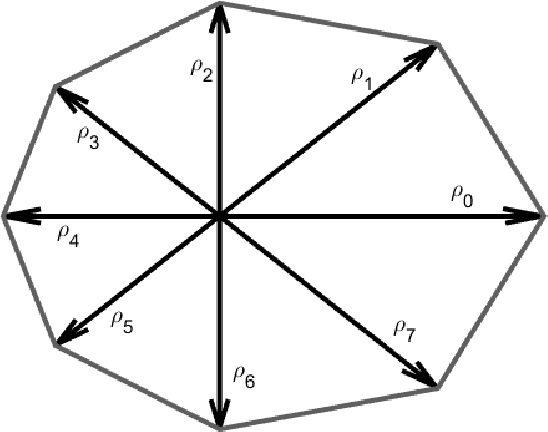
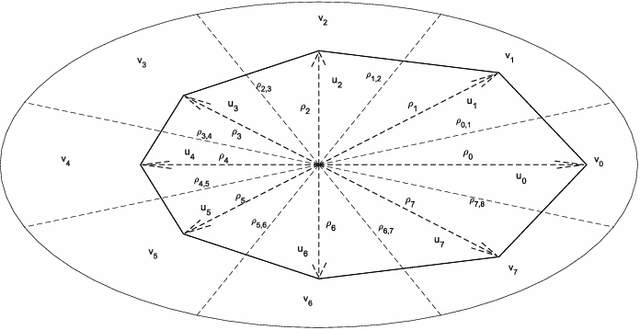
Detection of relative changes in circulating blood volume is important to guide resuscitation and manage a variety of medical conditions including sepsis, trauma, dialysis and congestive heart failure. Recent studies have shown that estimates of circulating blood volume can be obtained from the cross-sectional area (CSA) of the internal jugular vein (IJV) from ultrasound images. However, accurate segmentation and tracking of the IJV in ultrasound imaging is a challenging task and is significantly influenced by a number of parameters such as the image quality, shape, and temporal variation. In this paper, we propose a novel adaptive polar active contour (Ad-PAC) algorithm for the segmentation and tracking of the IJV in ultrasound videos. In the proposed algorithm, the parameters of the Ad-PAC algorithm are adapted based on the results of segmentation in previous frames. The Ad-PAC algorithm is applied to 65 ultrasound videos captured from 13 healthy subjects, with each video containing 450 frames. The results show that spatial and temporal adaptation of the energy function significantly improves segmentation performance when compared to current state-of-the-art active contour algorithms.
Image Identification Using SIFT Algorithm: Performance Analysis against Different Image Deformations
Mar 13, 2018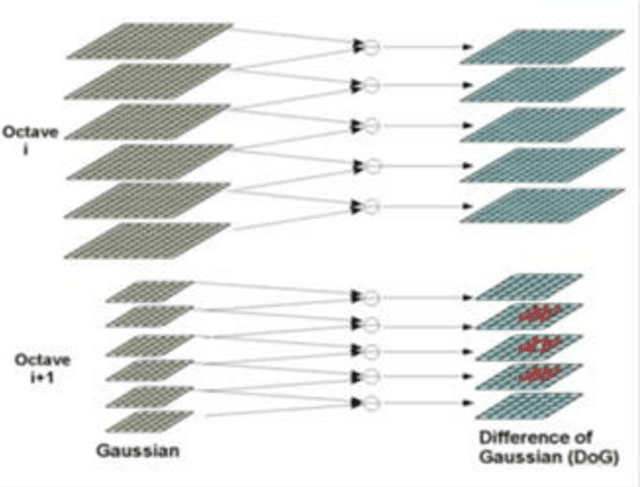
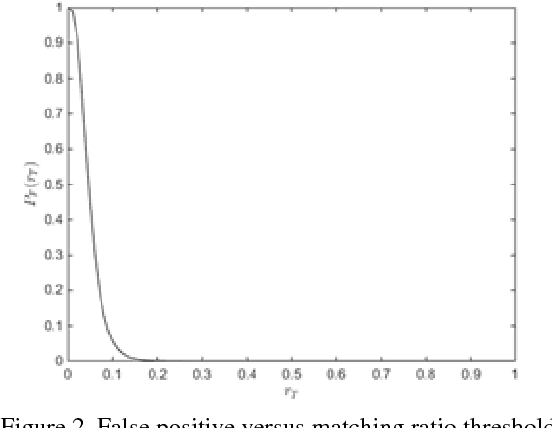
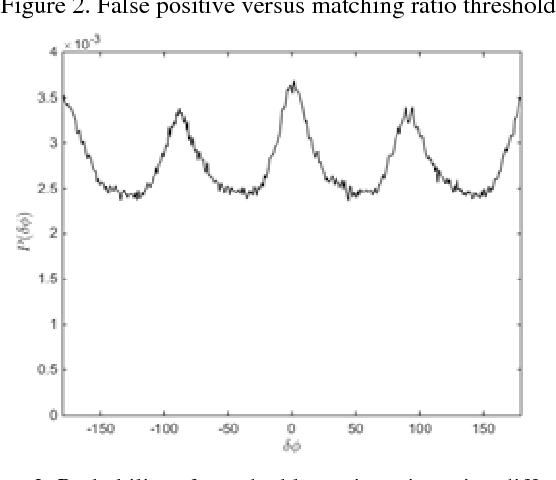
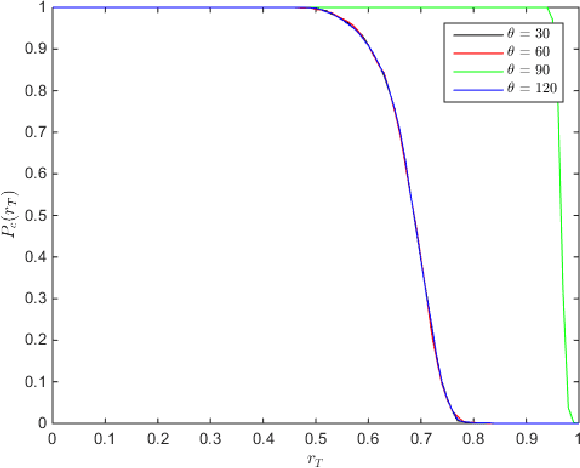
Image identification is one of the most challenging tasks in different areas of computer vision. Scale-invariant feature transform is an algorithm to detect and describe local features in images to further use them as an image matching criteria. In this paper, the performance of the SIFT matching algorithm against various image distortions such as rotation, scaling, fisheye and motion distortion are evaluated and false and true positive rates for a large number of image pairs are calculated and presented. We also evaluate the distribution of the matched keypoint orientation difference for each image deformation.
Image Matching Using SIFT, SURF, BRIEF and ORB: Performance Comparison for Distorted Images
Oct 07, 2017


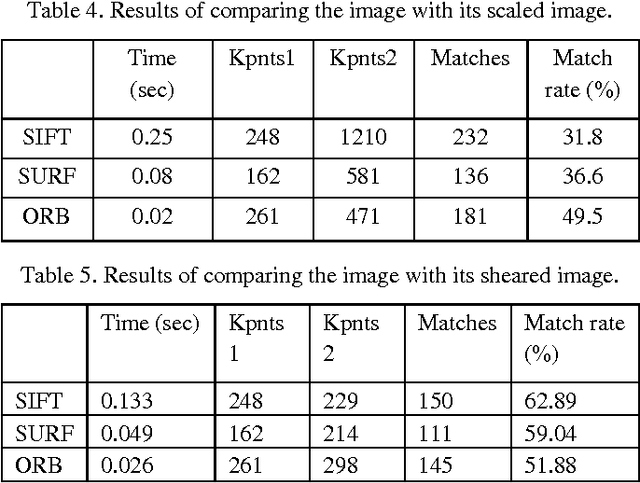
Fast and robust image matching is a very important task with various applications in computer vision and robotics. In this paper, we compare the performance of three different image matching techniques, i.e., SIFT, SURF, and ORB, against different kinds of transformations and deformations such as scaling, rotation, noise, fish eye distortion, and shearing. For this purpose, we manually apply different types of transformations on original images and compute the matching evaluation parameters such as the number of key points in images, the matching rate, and the execution time required for each algorithm and we will show that which algorithm is the best more robust against each kind of distortion. Index Terms-Image matching, scale invariant feature transform (SIFT), speed up robust feature (SURF), robust independent elementary features (BRIEF), oriented FAST, rotated BRIEF (ORB).