 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Latent Reasoning via Looped Language Models
Oct 29, 2025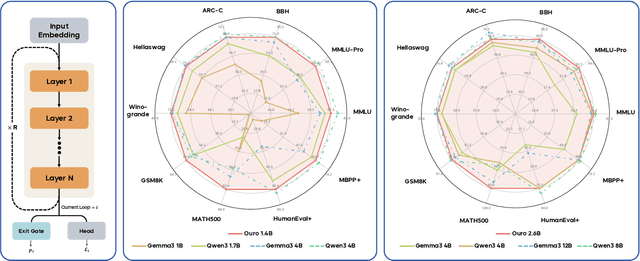
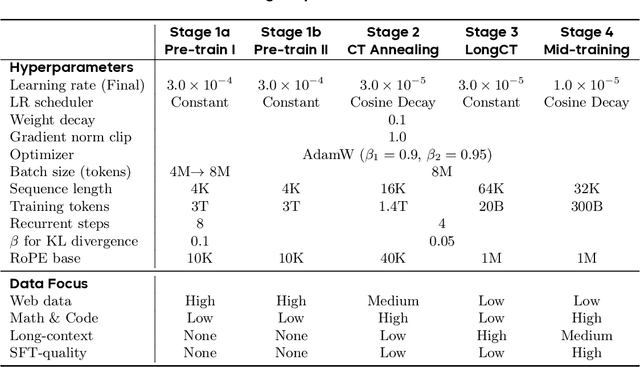
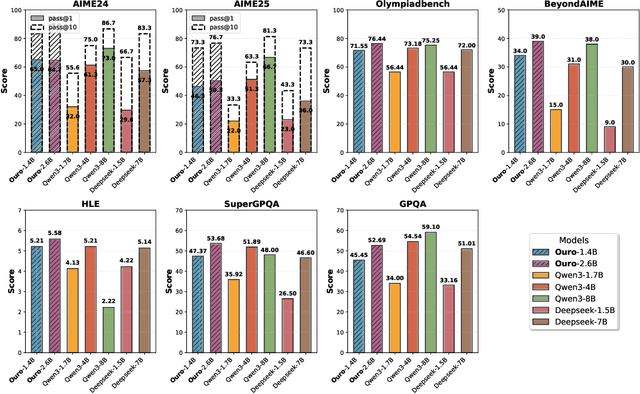

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
Large Language Models as 'Hidden Persuaders': Fake Product Reviews are Indistinguishable to Humans and Machines
Jun 16, 2025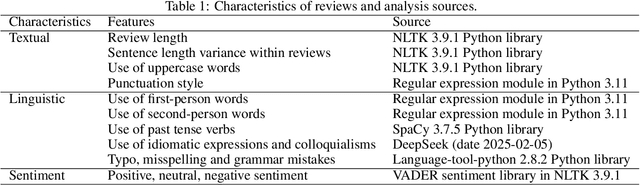
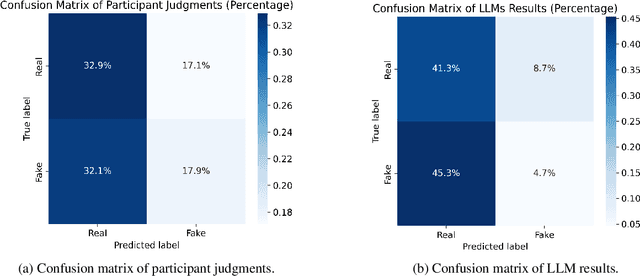
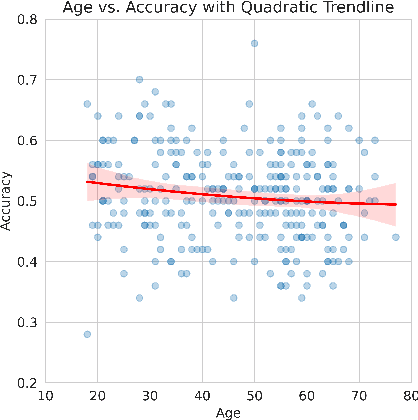
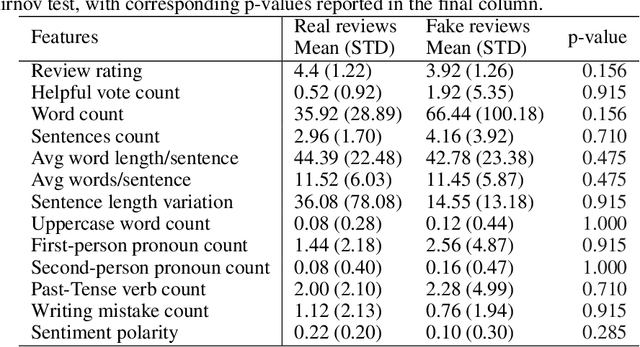
Reading and evaluating product reviews is central to how most people decide what to buy and consume online. However, the recent emergence of Large Language Models and Generative Artificial Intelligence now means writing fraudulent or fake reviews is potentially easier than ever. Through three studies we demonstrate that (1) humans are no longer able to distinguish between real and fake product reviews generated by machines, averaging only 50.8% accuracy overall - essentially the same that would be expected by chance alone; (2) that LLMs are likewise unable to distinguish between fake and real reviews and perform equivalently bad or even worse than humans; and (3) that humans and LLMs pursue different strategies for evaluating authenticity which lead to equivalently bad accuracy, but different precision, recall and F1 scores - indicating they perform worse at different aspects of judgment. The results reveal that review systems everywhere are now susceptible to mechanised fraud if they do not depend on trustworthy purchase verification to guarantee the authenticity of reviewers. Furthermore, the results provide insight into the consumer psychology of how humans judge authenticity, demonstrating there is an inherent 'scepticism bias' towards positive reviews and a special vulnerability to misjudge the authenticity of fake negative reviews. Additionally, results provide a first insight into the 'machine psychology' of judging fake reviews, revealing that the strategies LLMs take to evaluate authenticity radically differ from humans, in ways that are equally wrong in terms of accuracy, but different in their misjudgments.
Monitoring morphometric drift in lifelong learning segmentation of the spinal cord
May 02, 2025Morphometric measures derived from spinal cord segmentations can serve as diagnostic and prognostic biomarkers in neurological diseases and injuries affecting the spinal cord. While robust, automatic segmentation methods to a wide variety of contrasts and pathologies have been developed over the past few years, whether their predictions are stable as the model is updated using new datasets has not been assessed. This is particularly important for deriving normative values from healthy participants. In this study, we present a spinal cord segmentation model trained on a multisite $(n=75)$ dataset, including 9 different MRI contrasts and several spinal cord pathologies. We also introduce a lifelong learning framework to automatically monitor the morphometric drift as the model is updated using additional datasets. The framework is triggered by an automatic GitHub Actions workflow every time a new model is created, recording the morphometric values derived from the model's predictions over time. As a real-world application of the proposed framework, we employed the spinal cord segmentation model to update a recently-introduced normative database of healthy participants containing commonly used measures of spinal cord morphometry. Results showed that: (i) our model outperforms previous versions and pathology-specific models on challenging lumbar spinal cord cases, achieving an average Dice score of $0.95 \pm 0.03$; (ii) the automatic workflow for monitoring morphometric drift provides a quick feedback loop for developing future segmentation models; and (iii) the scaling factor required to update the database of morphometric measures is nearly constant among slices across the given vertebral levels, showing minimum drift between the current and previous versions of the model monitored by the framework. The model is freely available in Spinal Cord Toolbox v7.0.
Ultra-Resolution Cascaded Diffusion Model for Gigapixel Image Synthesis in Histopathology
Dec 02, 2023


Diagnoses from histopathology images rely on information from both high and low resolutions of Whole Slide Images. Ultra-Resolution Cascaded Diffusion Models (URCDMs) allow for the synthesis of high-resolution images that are realistic at all magnification levels, focusing not only on fidelity but also on long-distance spatial coherency. Our model beats existing methods, improving the pFID-50k [2] score by 110.63 to 39.52 pFID-50k. Additionally, a human expert evaluation study was performed, reaching a weighted Mean Absolute Error (MAE) of 0.11 for the Lower Resolution Diffusion Models and a weighted MAE of 0.22 for the URCDM.
Towards contrast-agnostic soft segmentation of the spinal cord
Oct 23, 2023



Spinal cord segmentation is clinically relevant and is notably used to compute spinal cord cross-sectional area (CSA) for the diagnosis and monitoring of cord compression or neurodegenerative diseases such as multiple sclerosis. While several semi and automatic methods exist, one key limitation remains: the segmentation depends on the MRI contrast, resulting in different CSA across contrasts. This is partly due to the varying appearance of the boundary between the spinal cord and the cerebrospinal fluid that depends on the sequence and acquisition parameters. This contrast-sensitive CSA adds variability in multi-center studies where protocols can vary, reducing the sensitivity to detect subtle atrophies. Moreover, existing methods enhance the CSA variability by training one model per contrast, while also producing binary masks that do not account for partial volume effects. In this work, we present a deep learning-based method that produces soft segmentations of the spinal cord. Using the Spine Generic Public Database of healthy participants ($\text{n}=267$; $\text{contrasts}=6$), we first generated participant-wise soft ground truth (GT) by averaging the binary segmentations across all 6 contrasts. These soft GT, along with a regression-based loss function, were then used to train a UNet model for spinal cord segmentation. We evaluated our model against state-of-the-art methods and performed ablation studies involving different GT mask types, loss functions, and contrast-specific models. Our results show that using the soft average segmentations along with a regression loss function reduces CSA variability ($p < 0.05$, Wilcoxon signed-rank test). The proposed spinal cord segmentation model generalizes better than the state-of-the-art contrast-specific methods amongst unseen datasets, vendors, contrasts, and pathologies (compression, lesions), while accounting for partial volume effects.
Application of Machine Learning to Sleep Stage Classification
Nov 04, 2021
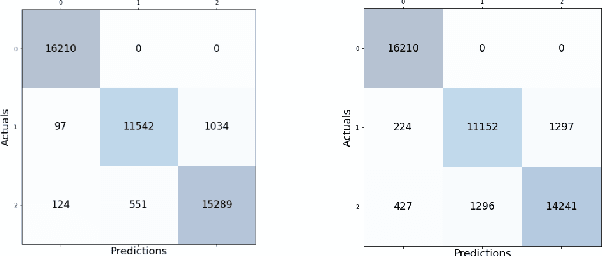
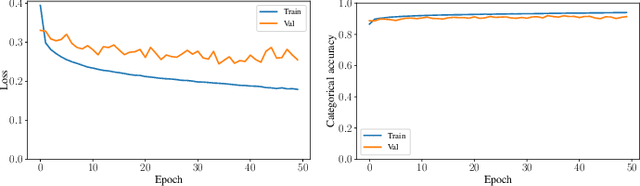
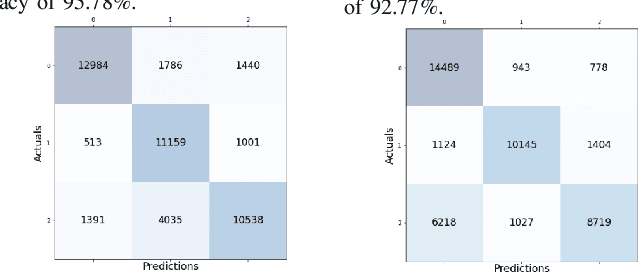
Sleep studies are imperative to recapitulate phenotypes associated with sleep loss and uncover mechanisms contributing to psychopathology. Most often, investigators manually classify the polysomnography into vigilance states, which is time-consuming, requires extensive training, and is prone to inter-scorer variability. While many works have successfully developed automated vigilance state classifiers based on multiple EEG channels, we aim to produce an automated and open-access classifier that can reliably predict vigilance state based on a single cortical electroencephalogram (EEG) from rodents to minimize the disadvantages that accompany tethering small animals via wires to computer programs. Approximately 427 hours of continuously monitored EEG, electromyogram (EMG), and activity were labeled by a domain expert out of 571 hours of total data. Here we evaluate the performance of various machine learning techniques on classifying 10-second epochs into one of three discrete classes: paradoxical, slow-wave, or wake. Our investigations include Decision Trees, Random Forests, Naive Bayes Classifiers, Logistic Regression Classifiers, and Artificial Neural Networks. These methodologies have achieved accuracies ranging from approximately 74% to approximately 96%. Most notably, the Random Forest and the ANN achieved remarkable accuracies of 95.78% and 93.31%, respectively. Here we have shown the potential of various machine learning classifiers to automatically, accurately, and reliably classify vigilance states based on a single EEG reading and a single EMG reading.
Estimation and Tracking of AP-diameter of the Inferior Vena Cava in Ultrasound Images Using a Novel Active Circle Algorithm
Aug 08, 2018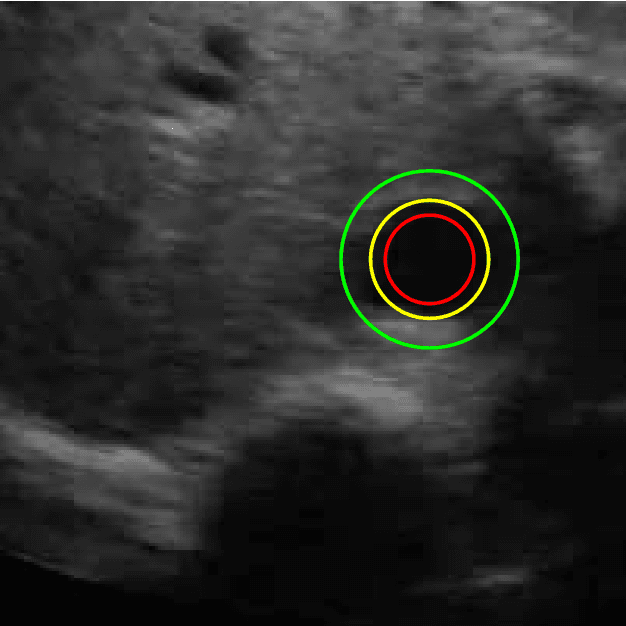
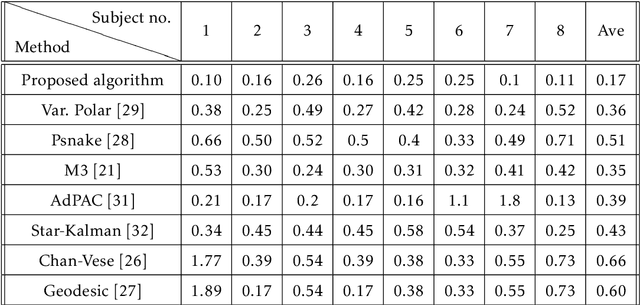
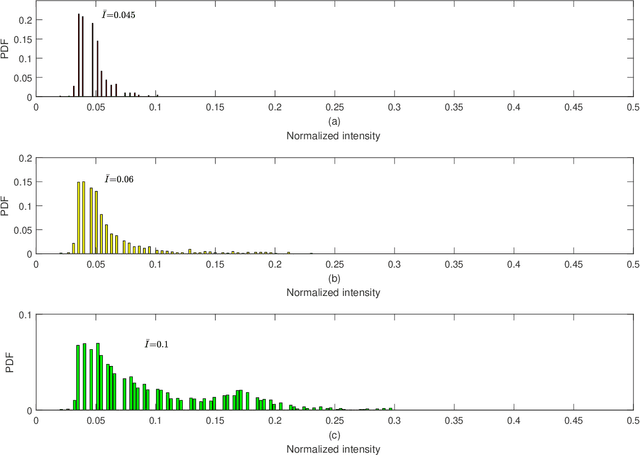
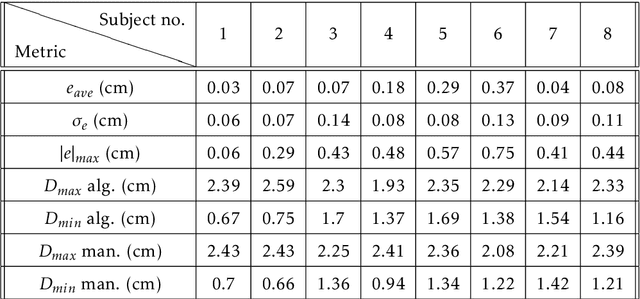
Medical research suggests that the anterior-posterior (AP)-diameter of the inferior vena cava (IVC) and its associated temporal variation as imaged by bedside ultrasound is useful in guiding fluid resuscitation of the critically-ill patient. Unfortunately, indistinct edges and gaps in vessel walls are frequently present which impede accurate estimation of the IVC AP-diameter for both human operators and segmentation algorithms. The majority of research involving use of the IVC to guide fluid resuscitation involves manual measurement of the maximum and minimum AP-diameter as it varies over time. This effort proposes using a time-varying circle fitted inside the typically ellipsoid IVC as an efficient, consistent and novel approach to tracking and approximating the AP-diameter even in the context of poor image quality. In this active-circle algorithm, a novel evolution functional is proposed and shown to be a useful tool for ultrasound image processing. The proposed algorithm is compared with an expert manual measurement, and state-of-the-art relevant algorithms. It is shown that the algorithm outperforms other techniques and performs very close to manual measurement.
* Published in Computers in Biology and Medicine
Automated Performance Assessment in Transoesophageal Echocardiography with Convolutional Neural Networks
Jun 13, 2018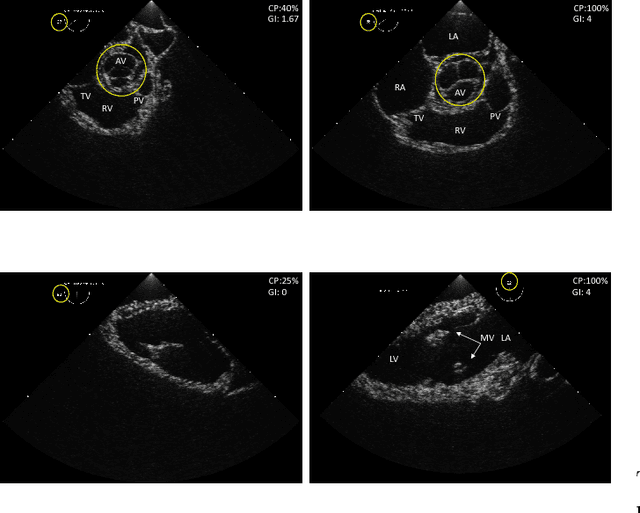
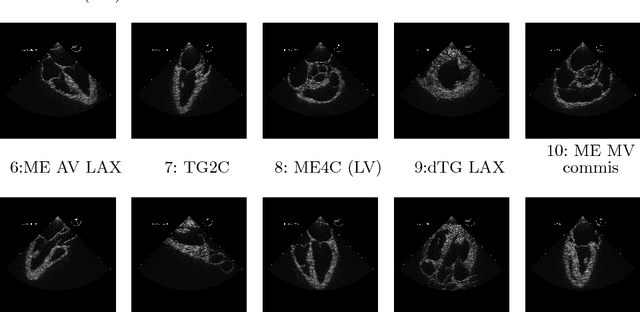
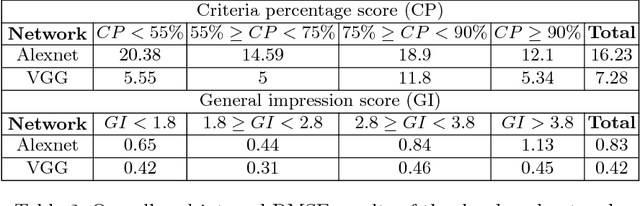
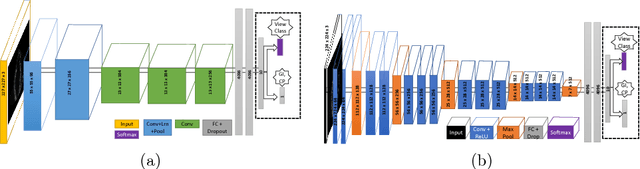
Transoesophageal echocardiography (TEE) is a valuable diagnostic and monitoring imaging modality. Proper image acquisition is essential for diagnosis, yet current assessment techniques are solely based on manual expert review. This paper presents a supervised deep learn ing framework for automatically evaluating and grading the quality of TEE images. To obtain the necessary dataset, 38 participants of varied experience performed TEE exams with a high-fidelity virtual reality (VR) platform. Two Convolutional Neural Network (CNN) architectures, AlexNet and VGG, structured to perform regression, were finetuned and validated on manually graded images from three evaluators. Two different scoring strategies, a criteria-based percentage and an overall general impression, were used. The developed CNN models estimate the average score with a root mean square accuracy ranging between 84%-93%, indicating the ability to replicate expert valuation. Proposed strategies for automated TEE assessment can have a significant impact on the training process of new TEE operators, providing direct feedback and facilitating the development of the necessary dexterous skills.
Adaptive Polar Active Contour for Segmentation and Tracking in Ultrasound Videos
Mar 19, 2018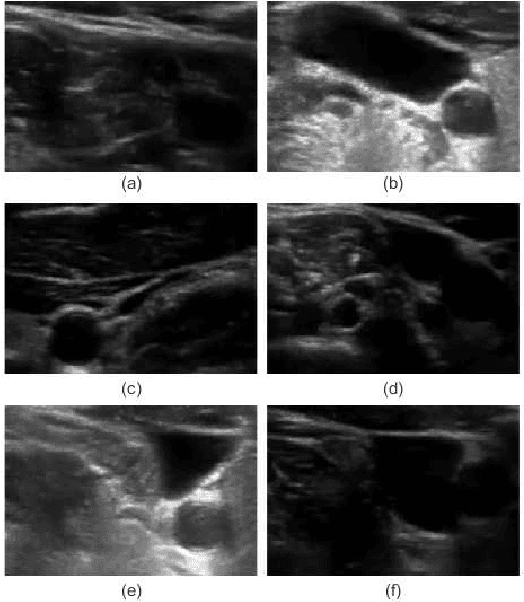
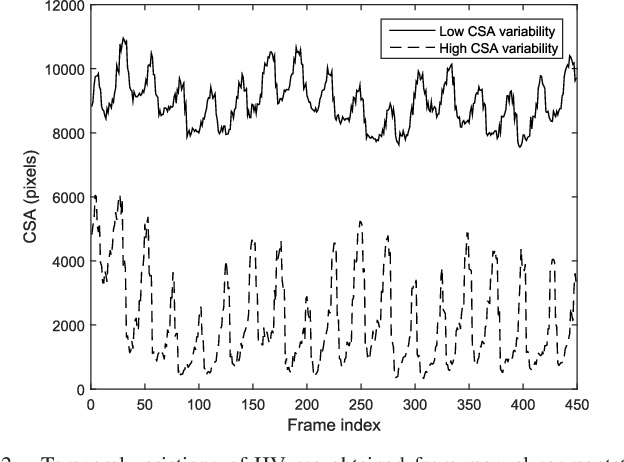
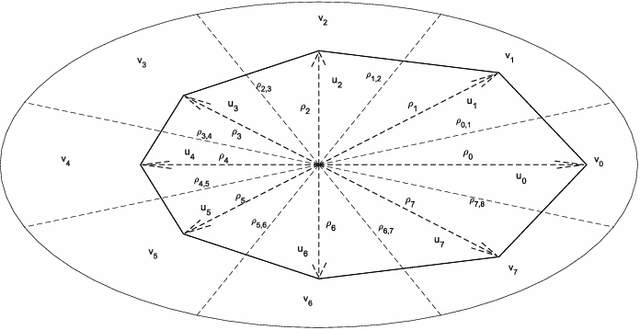
Detection of relative changes in circulating blood volume is important to guide resuscitation and manage a variety of medical conditions including sepsis, trauma, dialysis and congestive heart failure. Recent studies have shown that estimates of circulating blood volume can be obtained from the cross-sectional area (CSA) of the internal jugular vein (IJV) from ultrasound images. However, accurate segmentation and tracking of the IJV in ultrasound imaging is a challenging task and is significantly influenced by a number of parameters such as the image quality, shape, and temporal variation. In this paper, we propose a novel adaptive polar active contour (Ad-PAC) algorithm for the segmentation and tracking of the IJV in ultrasound videos. In the proposed algorithm, the parameters of the Ad-PAC algorithm are adapted based on the results of segmentation in previous frames. The Ad-PAC algorithm is applied to 65 ultrasound videos captured from 13 healthy subjects, with each video containing 450 frames. The results show that spatial and temporal adaptation of the energy function significantly improves segmentation performance when compared to current state-of-the-art active contour algorithms.