 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIS-DPO: Token-level Importance Sampling for Direct Preference Optimization With Estimated Weights
Oct 06, 2024

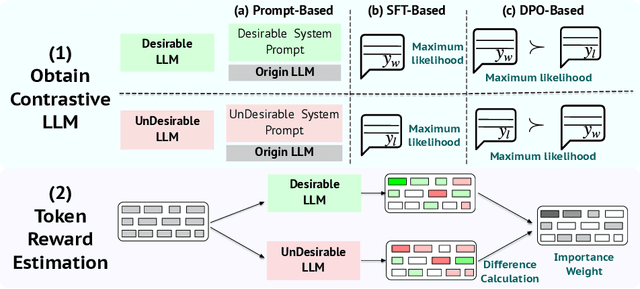
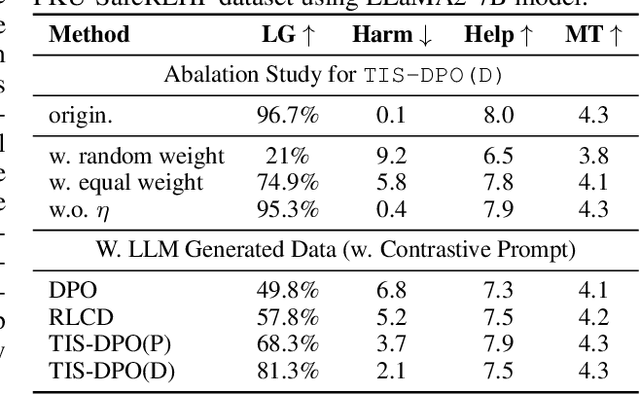
Direct Preference Optimization (DPO) has been widely adopted for preference alignment of Large Language Models (LLMs) due to its simplicity and effectiveness. However, DPO is derived as a bandit problem in which the whole response is treated as a single arm, ignoring the importance differences between tokens, which may affect optimization efficiency and make it difficult to achieve optimal results. In this work, we propose that the optimal data for DPO has equal expected rewards for each token in winning and losing responses, as there is no difference in token importance. However, since the optimal dataset is unavailable in practice, we propose using the original dataset for importance sampling to achieve unbiased optimization. Accordingly, we propose a token-level importance sampling DPO objective named TIS-DPO that assigns importance weights to each token based on its reward. Inspired by previous works, we estimate the token importance weights using the difference in prediction probabilities from a pair of contrastive LLMs. We explore three methods to construct these contrastive LLMs: (1) guiding the original LLM with contrastive prompts, (2) training two separate LLMs using winning and losing responses, and (3) performing forward and reverse DPO training with winning and losing responses. Experiments show that TIS-DPO significantly outperforms various baseline methods on harmlessness and helpfulness alignment and summarization tasks. We also visualize the estimated weights, demonstrating their ability to identify key token positions.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Data Filtering Networks
Oct 02, 2023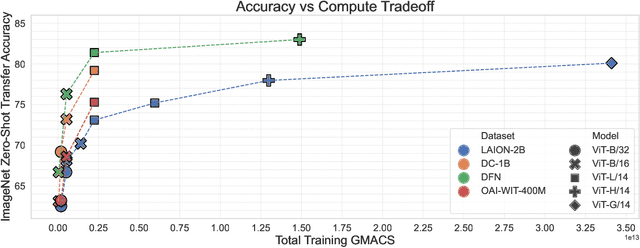
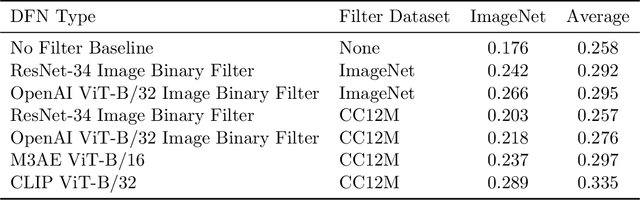
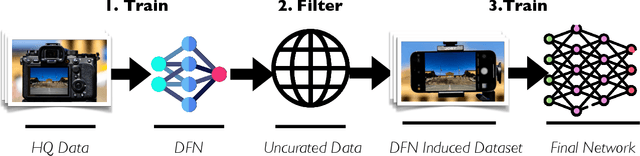
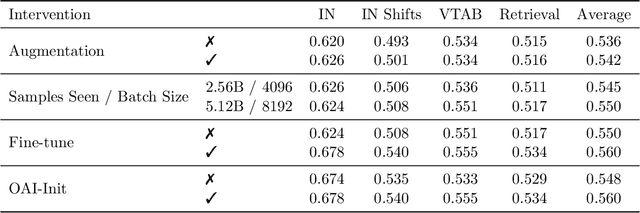
Large training sets have become a cornerstone of machine learning and are the foundation for recent advances in language modeling and multimodal learning. While data curation for pre-training is often still ad-hoc, one common paradigm is to first collect a massive pool of data from the Web and then filter this candidate pool down to an actual training set via various heuristics. In this work, we study the problem of learning a data filtering network (DFN) for this second step of filtering a large uncurated dataset. Our key finding is that the quality of a network for filtering is distinct from its performance on downstream tasks: for instance, a model that performs well on ImageNet can yield worse training sets than a model with low ImageNet accuracy that is trained on a small amount of high-quality data. Based on our insights, we construct new data filtering networks that induce state-of-the-art image-text datasets. Specifically, our best performing dataset DFN-5B enables us to train state-of-the-art models for their compute budgets: among other improvements on a variety of tasks, a ViT-H trained on our dataset achieves 83.0% zero-shot transfer accuracy on ImageNet, out-performing models trained on other datasets such as LAION-2B, DataComp-1B, or OpenAI's WIT. In order to facilitate further research in dataset design, we also release a new 2 billion example dataset DFN-2B and show that high performance data filtering networks can be trained from scratch using only publicly available data.
STAIR: Learning Sparse Text and Image Representation in Grounded Tokens
Feb 08, 2023Image and text retrieval is one of the foundational tasks in the vision and language domain with multiple real-world applications. State-of-the-art approaches, e.g. CLIP, ALIGN, represent images and texts as dense embeddings and calculate the similarity in the dense embedding space as the matching score. On the other hand, sparse semantic features like bag-of-words models are more interpretable, but believed to suffer from inferior accuracy than dense representations. In this work, we show that it is possible to build a sparse semantic representation that is as powerful as, or even better than, dense presentations. We extend the CLIP model and build a sparse text and image representation (STAIR), where the image and text are mapped to a sparse token space. Each token in the space is a (sub-)word in the vocabulary, which is not only interpretable but also easy to integrate with existing information retrieval systems. STAIR model significantly outperforms a CLIP model with +$4.9\%$ and +$4.3\%$ absolute Recall@1 improvement on COCO-5k text$\rightarrow$image and image$\rightarrow$text retrieval respectively. It also achieved better performance on both of ImageNet zero-shot and linear probing compared to CLIP.