 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTT4SG-350: A Speech Corpus for All Swiss German Dialect Regions
May 30, 2023



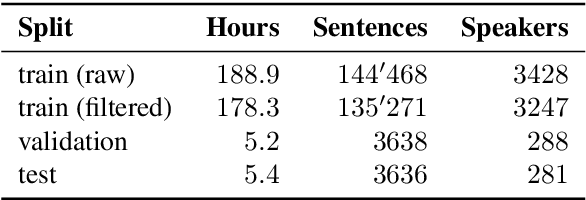
We present STT4SG-350 (Speech-to-Text for Swiss German), a corpus of Swiss German speech, annotated with Standard German text at the sentence level. The data is collected using a web app in which the speakers are shown Standard German sentences, which they translate to Swiss German and record. We make the corpus publicly available. It contains 343 hours of speech from all dialect regions and is the largest public speech corpus for Swiss German to date. Application areas include automatic speech recognition (ASR), text-to-speech, dialect identification, and speaker recognition. Dialect information, age group, and gender of the 316 speakers are provided. Genders are equally represented and the corpus includes speakers of all ages. Roughly the same amount of speech is provided per dialect region, which makes the corpus ideally suited for experiments with speech technology for different dialects. We provide training, validation, and test splits of the data. The test set consists of the same spoken sentences for each dialect region and allows a fair evaluation of the quality of speech technologies in different dialects. We train an ASR model on the training set and achieve an average BLEU score of 74.7 on the test set. The model beats the best published BLEU scores on 2 other Swiss German ASR test sets, demonstrating the quality of the corpus.
2nd Swiss German Speech to Standard German Text Shared Task at SwissText 2022
Jan 17, 2023
We present the results and findings of the 2nd Swiss German speech to Standard German text shared task at SwissText 2022. Participants were asked to build a sentence-level Swiss German speech to Standard German text system specialized on the Grisons dialect. The objective was to maximize the BLEU score on a test set of Grisons speech. 3 teams participated, with the best-performing system achieving a BLEU score of 70.1.
Swiss German Speech to Text system evaluation
Jul 01, 2022We present an in-depth evaluation of four commercially available Speech-to-Text (STT) systems for Swiss German. The systems are anonymized and referred to as system a-d in this report. We compare the four systems to our STT model, referred to as FHNW from hereon after, and provide details on how we trained our model. To evaluate the models, we use two STT datasets from different domains. The Swiss Parliament Corpus (SPC) test set and a private dataset in the news domain with an even distribution across seven dialect regions. We provide a detailed error analysis to detect the three systems' strengths and weaknesses. This analysis is limited by the characteristics of the two test sets. Our model scored the highest bilingual evaluation understudy (BLEU) on both datasets. On the SPC test set, we obtain a BLEU score of 0.607, whereas the best commercial system reaches a BLEU score of 0.509. On our private test set, we obtain a BLEU score of 0.722 and the best commercial system a BLEU score of 0.568.
SDS-200: A Swiss German Speech to Standard German Text Corpus
May 19, 2022
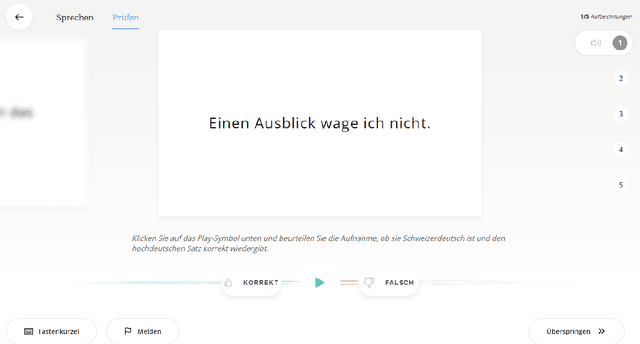
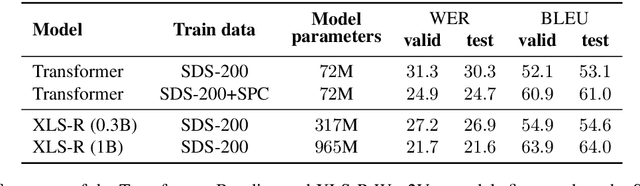
We present SDS-200, a corpus of Swiss German dialectal speech with Standard German text translations, annotated with dialect, age, and gender information of the speakers. The dataset allows for training speech translation, dialect recognition, and speech synthesis systems, among others. The data was collected using a web recording tool that is open to the public. Each participant was given a text in Standard German and asked to translate it to their Swiss German dialect before recording it. To increase the corpus quality, recordings were validated by other participants. The data consists of 200 hours of speech by around 4000 different speakers and covers a large part of the Swiss-German dialect landscape. We release SDS-200 alongside a baseline speech translation model, which achieves a word error rate (WER) of 30.3 and a BLEU score of 53.1 on the SDS-200 test set. Furthermore, we use SDS-200 to fine-tune a pre-trained XLS-R model, achieving 21.6 WER and 64.0 BLEU.
Swiss Parliaments Corpus, an Automatically Aligned Swiss German Speech to Standard German Text Corpus
Oct 06, 2020

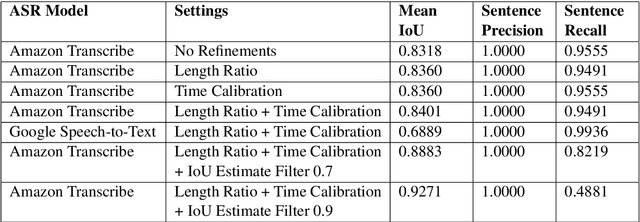
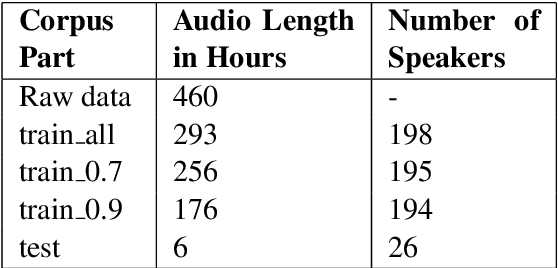
We present a forced sentence alignment procedure for Swiss German speech and Standard German text. It is able to create a speech-to-text corpus in a fully automatic fashion, given an audio recording and the corresponding unaligned transcript. Compared to a manual alignment, it achieves a mean IoU of 0.8401 with a sentence recall of 0.9491. When applying our IoU estimate filter, the mean IoU can be further improved to 0.9271 at the cost of a lower sentence recall of 0.4881. Using this procedure, we created the Swiss Parliaments Corpus, an automatically aligned Swiss German speech to Standard German text corpus. 65 % of the raw data could be transformed to sentence-level audio-text-pairs, resulting in 293 hours of training data. We have made the corpus freely available for download.