 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Beyond the Support: Adversarial Training on Unsupervised Jailbroken Activation Simulation
May 23, 2026Jailbreak prompts can trigger harmful completions on aligned LLMs, In accordance, safety steering has been proposed: test-time activation interventions that steer jailbreak activations to trigger refusal while preserving benign utility. However, existing steering methods are fundamentally supervised and tied to a static, limited training set, whereas real jailbreaks evolve and are often out-of-distributed from the training set, leading to failures on unseen attacks. In this paper, we tackle the failure on unseen jailbreaks problem, base on unsupervised latent direction discovery. We propose a bi-level adversarial training framework for zero-shot jailbreak defense. In the inner step, we simulate diverse jail-broken activations by extrapolating from refusal-state harmful-request activations via unsupervised latent direction discovery, which expands the coverage of real jailbreak activation subspaces. In the outer step, we train a potential-induced steering field to push these adversarial jailbroken states into refusal regions while keeping benign unchanged. Across three LLMs and six classical jailbreak families, our method achieves strong defense with attack success rates mostly below 5%, and rising subspace coverage throughout training helps explain the improved generalization.
GeoIB: Geometry-Aware Information Bottleneck via Statistical-Manifold Compression
Feb 03, 2026Information Bottleneck (IB) is widely used, but in deep learning, it is usually implemented through tractable surrogates, such as variational bounds or neural mutual information (MI) estimators, rather than directly controlling the MI I(X;Z) itself. The looseness and estimator-dependent bias can make IB "compression" only indirectly controlled and optimization fragile. We revisit the IB problem through the lens of information geometry and propose a \textbf{Geo}metric \textbf{I}nformation \textbf{B}ottleneck (\textbf{GeoIB}) that dispenses with mutual information (MI) estimation. We show that I(X;Z) and I(Z;Y) admit exact projection forms as minimal Kullback-Leibler (KL) distances from the joint distributions to their respective independence manifolds. Guided by this view, GeoIB controls information compression with two complementary terms: (i) a distribution-level Fisher-Rao (FR) discrepancy, which matches KL to second order and is reparameterization-invariant; and (ii) a geometry-level Jacobian-Frobenius (JF) term that provides a local capacity-type upper bound on I(Z;X) by penalizing pullback volume expansion of the encoder. We further derive a natural-gradient optimizer consistent with the FR metric and prove that the standard additive natural-gradient step is first-order equivalent to the geodesic update. We conducted extensive experiments and observed that the GeoIB achieves a better trade-off between prediction accuracy and compression ratio in the information plane than the mainstream IB baselines on popular datasets. GeoIB improves invariance and optimization stability by unifying distributional and geometric regularization under a single bottleneck multiplier. The source code of GeoIB is released at "https://anonymous.4open.science/r/G-IB-0569".
EVE: Efficient Verification of Data Erasure through Customized Perturbation in Approximate Unlearning
Feb 03, 2026Verifying whether the machine unlearning process has been properly executed is critical but remains underexplored. Some existing approaches propose unlearning verification methods based on backdooring techniques. However, these methods typically require participation in the model's initial training phase to backdoor the model for later verification, which is inefficient and impractical. In this paper, we propose an efficient verification of erasure method (EVE) for verifying machine unlearning without requiring involvement in the model's initial training process. The core idea is to perturb the unlearning data to ensure the model prediction of the specified samples will change before and after unlearning with perturbed data. The unlearning users can leverage the observation of the changes as a verification signal. Specifically, the perturbations are designed with two key objectives: ensuring the unlearning effect and altering the unlearned model's prediction of target samples. We formalize the perturbation generation as an adversarial optimization problem, solving it by aligning the unlearning gradient with the gradient of boundary change for target samples. We conducted extensive experiments, and the results show that EVE can verify machine unlearning without involving the model's initial training process, unlike backdoor-based methods. Moreover, EVE significantly outperforms state-of-the-art unlearning verification methods, offering significant speedup in efficiency while enhancing verification accuracy. The source code of EVE is released at \uline{https://anonymous.4open.science/r/EVE-C143}, providing a novel tool for verification of machine unlearning.
BlindU: Blind Machine Unlearning without Revealing Erasing Data
Jan 12, 2026Machine unlearning enables data holders to remove the contribution of their specified samples from trained models to protect their privacy. However, it is paradoxical that most unlearning methods require the unlearning requesters to firstly upload their data to the server as a prerequisite for unlearning. These methods are infeasible in many privacy-preserving scenarios where servers are prohibited from accessing users' data, such as federated learning (FL). In this paper, we explore how to implement unlearning under the condition of not uncovering the erasing data to the server. We propose \textbf{Blind Unlearning (BlindU)}, which carries out unlearning using compressed representations instead of original inputs. BlindU only involves the server and the unlearning user: the user locally generates privacy-preserving representations, and the server performs unlearning solely on these representations and their labels. For the FL model training, we employ the information bottleneck (IB) mechanism. The encoder of the IB-based FL model learns representations that distort maximum task-irrelevant information from inputs, allowing FL users to generate compressed representations locally. For effective unlearning using compressed representation, BlindU integrates two dedicated unlearning modules tailored explicitly for IB-based models and uses a multiple gradient descent algorithm to balance forgetting and utility retaining. While IB compression already provides protection for task-irrelevant information of inputs, to further enhance the privacy protection, we introduce a noise-free differential privacy (DP) masking method to deal with the raw erasing data before compressing. Theoretical analysis and extensive experimental results illustrate the superiority of BlindU in privacy protection and unlearning effectiveness compared with the best existing privacy-preserving unlearning benchmarks.
Property-Preserving Hashing for $\ell_1$-Distance Predicates: Applications to Countering Adversarial Input Attacks
Apr 23, 2025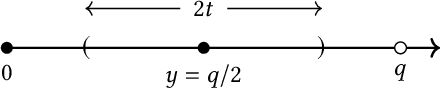
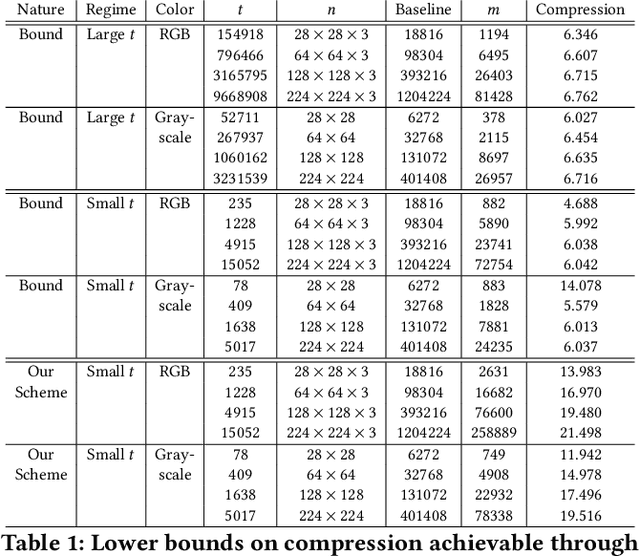
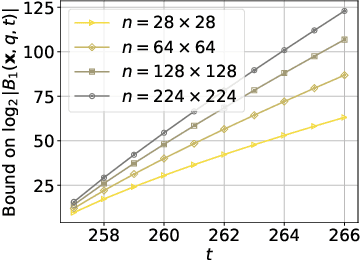
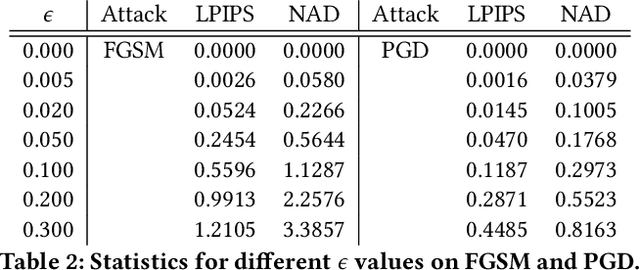
Perceptual hashing is used to detect whether an input image is similar to a reference image with a variety of security applications. Recently, they have been shown to succumb to adversarial input attacks which make small imperceptible changes to the input image yet the hashing algorithm does not detect its similarity to the original image. Property-preserving hashing (PPH) is a recent construct in cryptography, which preserves some property (predicate) of its inputs in the hash domain. Researchers have so far shown constructions of PPH for Hamming distance predicates, which, for instance, outputs 1 if two inputs are within Hamming distance $t$. A key feature of PPH is its strong correctness guarantee, i.e., the probability that the predicate will not be correctly evaluated in the hash domain is negligible. Motivated by the use case of detecting similar images under adversarial setting, we propose the first PPH construction for an $\ell_1$-distance predicate. Roughly, this predicate checks if the two one-sided $\ell_1$-distances between two images are within a threshold $t$. Since many adversarial attacks use $\ell_2$-distance (related to $\ell_1$-distance) as the objective function to perturb the input image, by appropriately choosing the threshold $t$, we can force the attacker to add considerable noise to evade detection, and hence significantly deteriorate the image quality. Our proposed scheme is highly efficient, and runs in time $O(t^2)$. For grayscale images of size $28 \times 28$, we can evaluate the predicate in $0.0784$ seconds when pixel values are perturbed by up to $1 \%$. For larger RGB images of size $224 \times 224$, by dividing the image into 1,000 blocks, we achieve times of $0.0128$ seconds per block for $1 \%$ change, and up to $0.2641$ seconds per block for $14\%$ change.
SCU: An Efficient Machine Unlearning Scheme for Deep Learning Enabled Semantic Communications
Feb 27, 2025Deep learning (DL) enabled semantic communications leverage DL to train encoders and decoders (codecs) to extract and recover semantic information. However, most semantic training datasets contain personal private information. Such concerns call for enormous requirements for specified data erasure from semantic codecs when previous users hope to move their data from the semantic system. {Existing machine unlearning solutions remove data contribution from trained models, yet usually in supervised sole model scenarios. These methods are infeasible in semantic communications that often need to jointly train unsupervised encoders and decoders.} In this paper, we investigate the unlearning problem in DL-enabled semantic communications and propose a semantic communication unlearning (SCU) scheme to tackle the problem. {SCU includes two key components. Firstly,} we customize the joint unlearning method for semantic codecs, including the encoder and decoder, by minimizing mutual information between the learned semantic representation and the erased samples. {Secondly,} to compensate for semantic model utility degradation caused by unlearning, we propose a contrastive compensation method, which considers the erased data as the negative samples and the remaining data as the positive samples to retrain the unlearned semantic models contrastively. Theoretical analysis and extensive experimental results on three representative datasets demonstrate the effectiveness and efficiency of our proposed methods.
Targeted Therapy in Data Removal: Object Unlearning Based on Scene Graphs
Nov 25, 2024
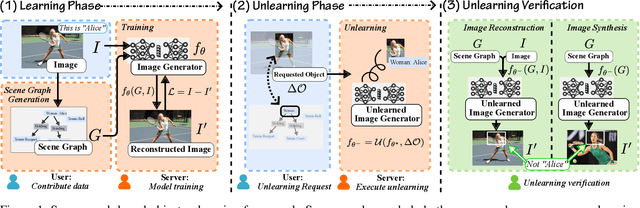


Users may inadvertently upload personally identifiable information (PII) to Machine Learning as a Service (MLaaS) providers. When users no longer want their PII on these services, regulations like GDPR and COPPA mandate a right to forget for these users. As such, these services seek efficient methods to remove the influence of specific data points. Thus the introduction of machine unlearning. Traditionally, unlearning is performed with the removal of entire data samples (sample unlearning) or whole features across the dataset (feature unlearning). However, these approaches are not equipped to handle the more granular and challenging task of unlearning specific objects within a sample. To address this gap, we propose a scene graph-based object unlearning framework. This framework utilizes scene graphs, rich in semantic representation, transparently translate unlearning requests into actionable steps. The result, is the preservation of the overall semantic integrity of the generated image, bar the unlearned object. Further, we manage high computational overheads with influence functions to approximate the unlearning process. For validation, we evaluate the unlearned object's fidelity in outputs under the tasks of image reconstruction and image synthesis. Our proposed framework demonstrates improved object unlearning outcomes, with the preservation of unrequested samples in contrast to sample and feature learning methods. This work addresses critical privacy issues by increasing the granularity of targeted machine unlearning through forgetting specific object-level details without sacrificing the utility of the whole data sample or dataset feature.
Can Self Supervision Rejuvenate Similarity-Based Link Prediction?
Oct 24, 2024
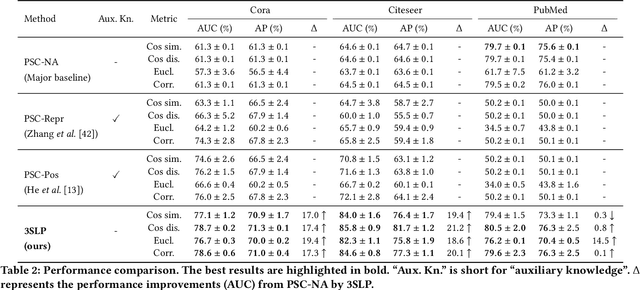
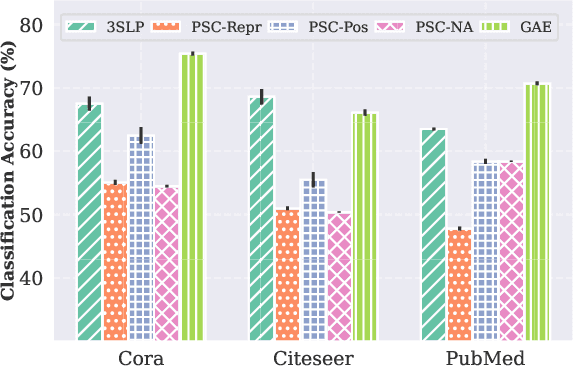
Although recent advancements in end-to-end learning-based link prediction (LP) methods have shown remarkable capabilities, the significance of traditional similarity-based LP methods persists in unsupervised scenarios where there are no known link labels. However, the selection of node features for similarity computation in similarity-based LP can be challenging. Less informative node features can result in suboptimal LP performance. To address these challenges, we integrate self-supervised graph learning techniques into similarity-based LP and propose a novel method: Self-Supervised Similarity-based LP (3SLP). 3SLP is suitable for the unsupervised condition of similarity-based LP without the assistance of known link labels. Specifically, 3SLP introduces a dual-view contrastive node representation learning (DCNRL) with crafted data augmentation and node representation learning. DCNRL is dedicated to developing more informative node representations, replacing the node attributes as inputs in the similarity-based LP backbone. Extensive experiments over benchmark datasets demonstrate the salient improvement of 3SLP, outperforming the baseline of traditional similarity-based LP by up to 21.2% (AUC).
Data-Driven Shape Sensing in Continuum Manipulators via Sliding Resistive Flex Sensors
Nov 29, 2023We introduce a novel shape-sensing method using Resistive Flex Sensors (RFS) embedded in cable-driven Continuum Dexterous Manipulators (CDMs). The RFS is predominantly sensitive to deformation rather than direct forces, making it a distinctive tool for shape sensing. The RFS unit we designed is a considerably less expensive and robust alternative, offering comparable accuracy and real-time performance to existing shape sensing methods used for the CDMs proposed for minimally-invasive surgery. Our design allows the RFS to move along and inside the CDM conforming to its curvature, offering the ability to capture resistance metrics from various bending positions without the need for elaborate sensor setups. The RFS unit is calibrated using an overhead camera and a ResNet machine learning framework. Experiments using a 3D printed prototype of the CDM achieved an average shape estimation error of 0.968 mm with a standard error of 0.275 mm. The response time of the model was approximately 1.16 ms, making real-time shape sensing feasible. While this preliminary study successfully showed the feasibility of our approach for C-shape CDM deformations with non-constant curvatures, we are currently extending the results to show the feasibility for adapting to more complex CDM configurations such as S-shape created in obstructed environments or in presence of the external forces.
Pair-wise Layer Attention with Spatial Masking for Video Prediction
Nov 19, 2023Video prediction yields future frames by employing the historical frames and has exhibited its great potential in many applications, e.g., meteorological prediction, and autonomous driving. Previous works often decode the ultimate high-level semantic features to future frames without texture details, which deteriorates the prediction quality. Motivated by this, we develop a Pair-wise Layer Attention (PLA) module to enhance the layer-wise semantic dependency of the feature maps derived from the U-shape structure in Translator, by coupling low-level visual cues and high-level features. Hence, the texture details of predicted frames are enriched. Moreover, most existing methods capture the spatiotemporal dynamics by Translator, but fail to sufficiently utilize the spatial features of Encoder. This inspires us to design a Spatial Masking (SM) module to mask partial encoding features during pretraining, which adds the visibility of remaining feature pixels by Decoder. To this end, we present a Pair-wise Layer Attention with Spatial Masking (PLA-SM) framework for video prediction to capture the spatiotemporal dynamics, which reflect the motion trend. Extensive experiments and rigorous ablation studies on five benchmarks demonstrate the advantages of the proposed approach. The code is available at GitHub.