 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProperty-Preserving Hashing for $\ell_1$-Distance Predicates: Applications to Countering Adversarial Input Attacks
Apr 23, 2025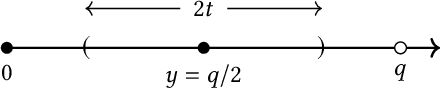
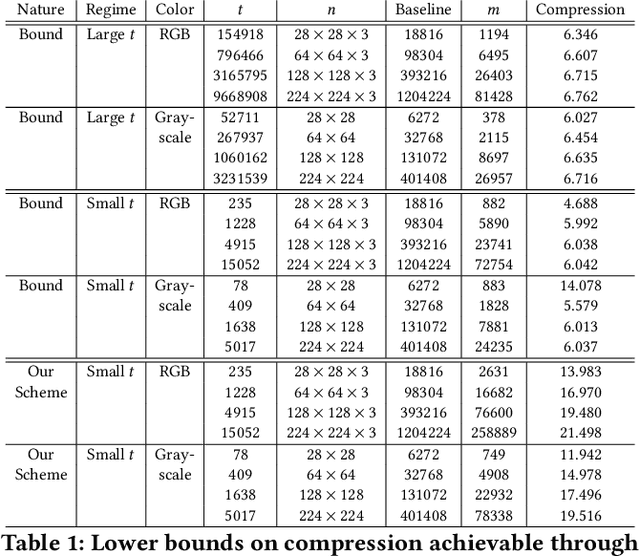
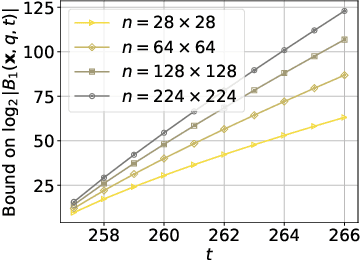
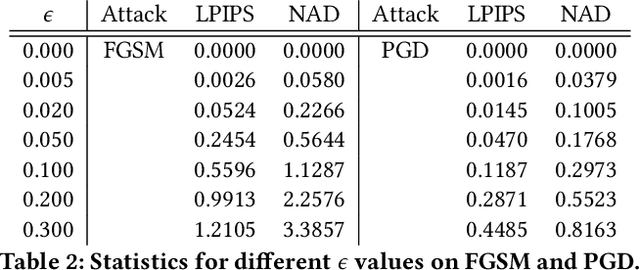
Perceptual hashing is used to detect whether an input image is similar to a reference image with a variety of security applications. Recently, they have been shown to succumb to adversarial input attacks which make small imperceptible changes to the input image yet the hashing algorithm does not detect its similarity to the original image. Property-preserving hashing (PPH) is a recent construct in cryptography, which preserves some property (predicate) of its inputs in the hash domain. Researchers have so far shown constructions of PPH for Hamming distance predicates, which, for instance, outputs 1 if two inputs are within Hamming distance $t$. A key feature of PPH is its strong correctness guarantee, i.e., the probability that the predicate will not be correctly evaluated in the hash domain is negligible. Motivated by the use case of detecting similar images under adversarial setting, we propose the first PPH construction for an $\ell_1$-distance predicate. Roughly, this predicate checks if the two one-sided $\ell_1$-distances between two images are within a threshold $t$. Since many adversarial attacks use $\ell_2$-distance (related to $\ell_1$-distance) as the objective function to perturb the input image, by appropriately choosing the threshold $t$, we can force the attacker to add considerable noise to evade detection, and hence significantly deteriorate the image quality. Our proposed scheme is highly efficient, and runs in time $O(t^2)$. For grayscale images of size $28 \times 28$, we can evaluate the predicate in $0.0784$ seconds when pixel values are perturbed by up to $1 \%$. For larger RGB images of size $224 \times 224$, by dividing the image into 1,000 blocks, we achieve times of $0.0128$ seconds per block for $1 \%$ change, and up to $0.2641$ seconds per block for $14\%$ change.
Targeted Therapy in Data Removal: Object Unlearning Based on Scene Graphs
Nov 25, 2024
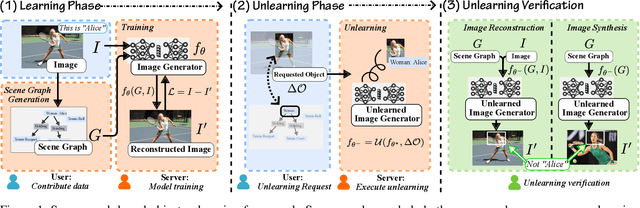


Users may inadvertently upload personally identifiable information (PII) to Machine Learning as a Service (MLaaS) providers. When users no longer want their PII on these services, regulations like GDPR and COPPA mandate a right to forget for these users. As such, these services seek efficient methods to remove the influence of specific data points. Thus the introduction of machine unlearning. Traditionally, unlearning is performed with the removal of entire data samples (sample unlearning) or whole features across the dataset (feature unlearning). However, these approaches are not equipped to handle the more granular and challenging task of unlearning specific objects within a sample. To address this gap, we propose a scene graph-based object unlearning framework. This framework utilizes scene graphs, rich in semantic representation, transparently translate unlearning requests into actionable steps. The result, is the preservation of the overall semantic integrity of the generated image, bar the unlearned object. Further, we manage high computational overheads with influence functions to approximate the unlearning process. For validation, we evaluate the unlearned object's fidelity in outputs under the tasks of image reconstruction and image synthesis. Our proposed framework demonstrates improved object unlearning outcomes, with the preservation of unrequested samples in contrast to sample and feature learning methods. This work addresses critical privacy issues by increasing the granularity of targeted machine unlearning through forgetting specific object-level details without sacrificing the utility of the whole data sample or dataset feature.
ConvoCache: Smart Re-Use of Chatbot Responses
Jun 26, 2024



We present ConvoCache, a conversational caching system that solves the problem of slow and expensive generative AI models in spoken chatbots. ConvoCache finds a semantically similar prompt in the past and reuses the response. In this paper we evaluate ConvoCache on the DailyDialog dataset. We find that ConvoCache can apply a UniEval coherence threshold of 90% and respond to 89% of prompts using the cache with an average latency of 214ms, replacing LLM and voice synthesis that can take over 1s. To further reduce latency we test prefetching and find limited usefulness. Prefetching with 80% of a request leads to a 63% hit rate, and a drop in overall coherence. ConvoCache can be used with any chatbot to reduce costs by reducing usage of generative AI by up to 89%.