 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLine of Sight Curvature for Missile Guidance using Reinforcement Meta-Learning
Paper and Code
Apr 29, 2022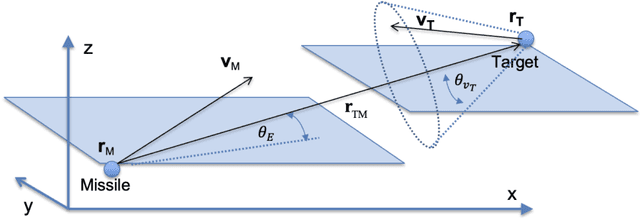

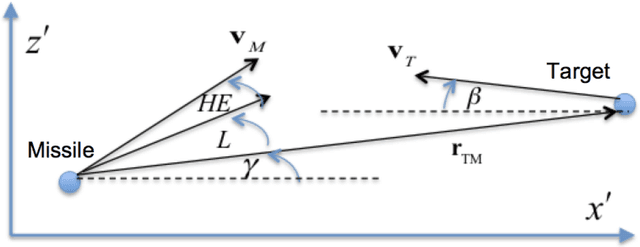
We use reinforcement meta learning to optimize a line of sight curvature policy that increases the effectiveness of a guidance system against maneuvering targets. The policy is implemented as a recurrent neural network that maps navigation system outputs to a Euler 321 attitude representation. The attitude representation is then used to construct a direction cosine matrix that biases the observed line of sight vector. The line of sight rotation rate derived from the biased line of sight is then mapped to a commanded acceleration by the guidance system. By varying the bias as a function of navigation system outputs, the policy enhances accuracy against highly maneuvering targets. Importantly, our method does not require an estimate of target acceleration. In our experiments, we demonstrate that when our method is combined with proportional navigation, the system significantly outperforms augmented proportional navigation with perfect knowledge of target acceleration, achieving improved accuracy with less control effort against a wide range of target maneuvers.