 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Entity Representation Learning for Pinterest Ads Ranking
Sep 04, 2025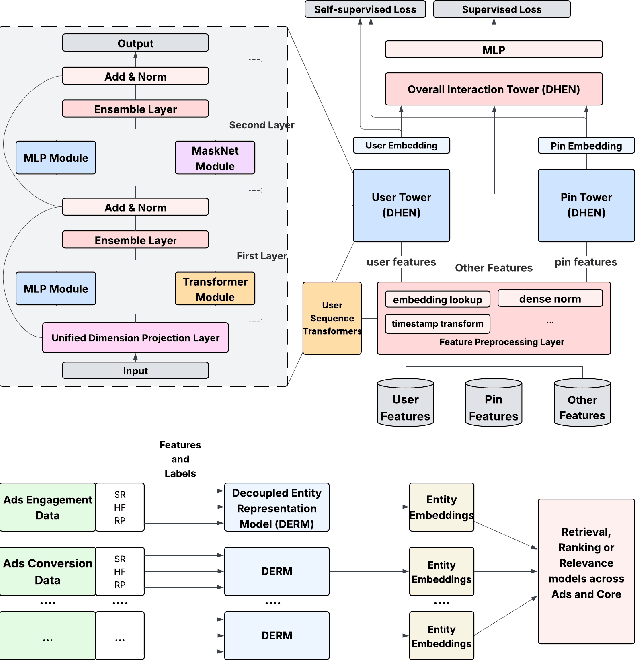



In this paper, we introduce a novel framework following an upstream-downstream paradigm to construct user and item (Pin) embeddings from diverse data sources, which are essential for Pinterest to deliver personalized Pins and ads effectively. Our upstream models are trained on extensive data sources featuring varied signals, utilizing complex architectures to capture intricate relationships between users and Pins on Pinterest. To ensure scalability of the upstream models, entity embeddings are learned, and regularly refreshed, rather than real-time computation, allowing for asynchronous interaction between the upstream and downstream models. These embeddings are then integrated as input features in numerous downstream tasks, including ad retrieval and ranking models for CTR and CVR predictions. We demonstrate that our framework achieves notable performance improvements in both offline and online settings across various downstream tasks. This framework has been deployed in Pinterest's production ad ranking systems, resulting in significant gains in online metrics.
Chatting Up Attachment: Using LLMs to Predict Adult Bonds
Aug 31, 2024



Obtaining data in the medical field is challenging, making the adoption of AI technology within the space slow and high-risk. We evaluate whether we can overcome this obstacle with synthetic data generated by large language models (LLMs). In particular, we use GPT-4 and Claude 3 Opus to create agents that simulate adults with varying profiles, childhood memories, and attachment styles. These agents participate in simulated Adult Attachment Interviews (AAI), and we use their responses to train models for predicting their underlying attachment styles. We evaluate our models using a transcript dataset from 9 humans who underwent the same interview protocol, analyzed and labeled by mental health professionals. Our findings indicate that training the models using only synthetic data achieves performance comparable to training the models on human data. Additionally, while the raw embeddings from synthetic answers occupy a distinct space compared to those from real human responses, the introduction of unlabeled human data and a simple standardization allows for a closer alignment of these representations. This adjustment is supported by qualitative analyses and is reflected in the enhanced predictive accuracy of the standardized embeddings.
Probabilistic Modeling of Human Teams to Infer False Beliefs
Oct 19, 2023



We develop a probabilistic graphical model (PGM) for artificially intelligent (AI) agents to infer human beliefs during a simulated urban search and rescue (USAR) scenario executed in a Minecraft environment with a team of three players. The PGM approach makes observable states and actions explicit, as well as beliefs and intentions grounded by evidence about what players see and do over time. This approach also supports inferring the effect of interventions, which are vital if AI agents are to assist human teams. The experiment incorporates manipulations of players' knowledge, and the virtual Minecraft-based testbed provides access to several streams of information, including the objects in the players' field of view. The participants are equipped with a set of marker blocks that can be placed near room entrances to signal the presence or absence of victims in the rooms to their teammates. In each team, one of the members is given a different legend for the markers than the other two, which may mislead them about the state of the rooms; that is, they will hold a false belief. We extend previous works in this field by introducing ToMCAT, an AI agent that can reason about individual and shared mental states. We find that the players' behaviors are affected by what they see in their in-game field of view, their beliefs about the meaning of the markers, and their beliefs about which meaning the team decided to adopt. In addition, we show that ToMCAT's beliefs are consistent with the players' actions and that it can infer false beliefs with accuracy significantly better than chance and comparable to inferences made by human observers.