 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Modeling of Human Teams to Infer False Beliefs
Oct 19, 2023



We develop a probabilistic graphical model (PGM) for artificially intelligent (AI) agents to infer human beliefs during a simulated urban search and rescue (USAR) scenario executed in a Minecraft environment with a team of three players. The PGM approach makes observable states and actions explicit, as well as beliefs and intentions grounded by evidence about what players see and do over time. This approach also supports inferring the effect of interventions, which are vital if AI agents are to assist human teams. The experiment incorporates manipulations of players' knowledge, and the virtual Minecraft-based testbed provides access to several streams of information, including the objects in the players' field of view. The participants are equipped with a set of marker blocks that can be placed near room entrances to signal the presence or absence of victims in the rooms to their teammates. In each team, one of the members is given a different legend for the markers than the other two, which may mislead them about the state of the rooms; that is, they will hold a false belief. We extend previous works in this field by introducing ToMCAT, an AI agent that can reason about individual and shared mental states. We find that the players' behaviors are affected by what they see in their in-game field of view, their beliefs about the meaning of the markers, and their beliefs about which meaning the team decided to adopt. In addition, we show that ToMCAT's beliefs are consistent with the players' actions and that it can infer false beliefs with accuracy significantly better than chance and comparable to inferences made by human observers.
Nowcasting-Nets: Deep Neural Network Structures for Precipitation Nowcasting Using IMERG
Aug 16, 2021



Accurate and timely estimation of precipitation is critical for issuing hazard warnings (e.g., for flash floods or landslides). Current remotely sensed precipitation products have a few hours of latency, associated with the acquisition and processing of satellite data. By applying a robust nowcasting system to these products, it is (in principle) possible to reduce this latency and improve their applicability, value, and impact. However, the development of such a system is complicated by the chaotic nature of the atmosphere, and the consequent rapid changes that can occur in the structures of precipitation systems In this work, we develop two approaches (hereafter referred to as Nowcasting-Nets) that use Recurrent and Convolutional deep neural network structures to address the challenge of precipitation nowcasting. A total of five models are trained using Global Precipitation Measurement (GPM) Integrated Multi-satellitE Retrievals for GPM (IMERG) precipitation data over the Eastern Contiguous United States (CONUS) and then tested against independent data for the Eastern and Western CONUS. The models were designed to provide forecasts with a lead time of up to 1.5 hours and, by using a feedback loop approach, the ability of the models to extend the forecast time to 4.5 hours was also investigated. Model performance was compared against the Random Forest (RF) and Linear Regression (LR) machine learning methods, and also against a persistence benchmark (BM) that used the most recent observation as the forecast. Independent IMERG observations were used as a reference, and experiments were conducted to examine both overall statistics and case studies involving specific precipitation events. Overall, the forecasts provided by the Nowcasting-Net models are superior, with the Convolutional Nowcasting Network with Residual Head (CNC-R) achieving 25%, 28%, and 46% improvement in the test ...
Modular Procedural Generation for Voxel Maps
Apr 18, 2021

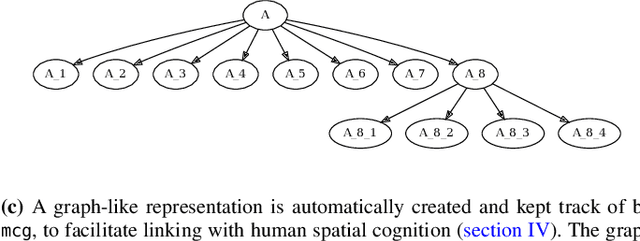
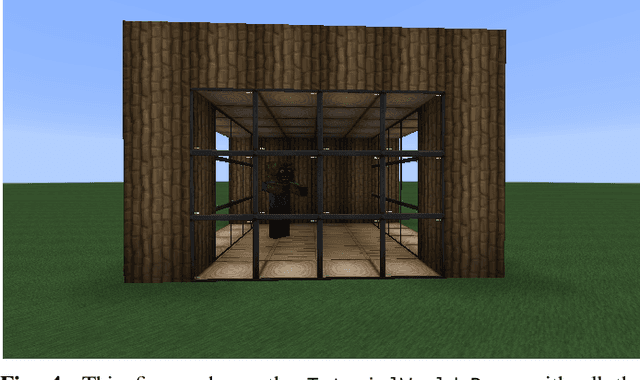
Task environments developed in Minecraft are becoming increasingly popular for artificial intelligence (AI) research. However, most of these are currently constructed manually, thus failing to take advantage of procedural content generation (PCG), a capability unique to virtual task environments. In this paper, we present mcg, an open-source library to facilitate implementing PCG algorithms for voxel-based environments such as Minecraft. The library is designed with human-machine teaming research in mind, and thus takes a 'top-down' approach to generation, simultaneously generating low and high level machine-readable representations that are suitable for empirical research. These can be consumed by downstream AI applications that consider human spatial cognition. The benefits of this approach include rapid, scalable, and efficient development of virtual environments, the ability to control the statistics of the environment at a semantic level, and the ability to generate novel environments in response to player actions in real time.
Attentional Local Contrast Networks for Infrared Small Target Detection
Dec 15, 2020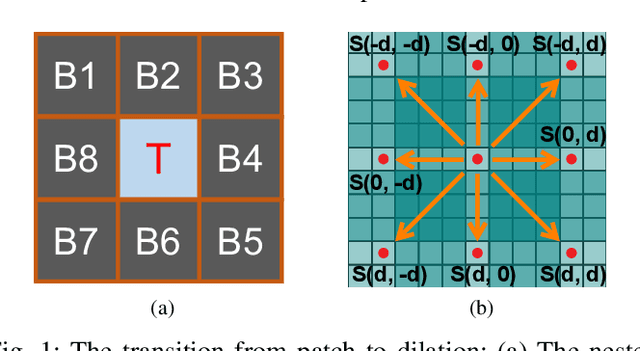

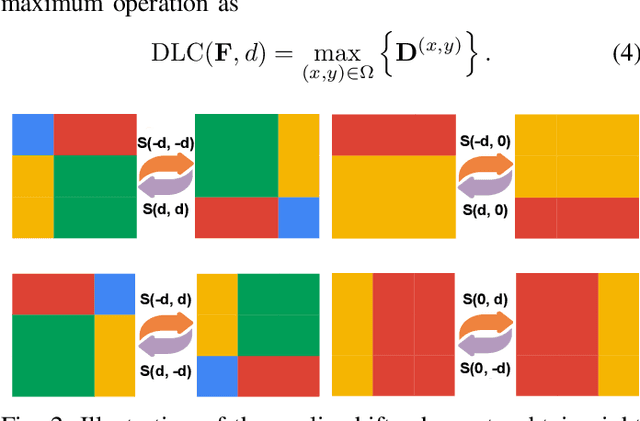
To mitigate the issue of minimal intrinsic features for pure data-driven methods, in this paper, we propose a novel model-driven deep network for infrared small target detection, which combines discriminative networks and conventional model-driven methods to make use of both labeled data and the domain knowledge. By designing a feature map cyclic shift scheme, we modularize a conventional local contrast measure method as a depth-wise parameterless nonlinear feature refinement layer in an end-to-end network, which encodes relatively long-range contextual interactions with clear physical interpretability. To highlight and preserve the small target features, we also exploit a bottom-up attentional modulation integrating the smaller scale subtle details of low-level features into high-level features of deeper layers. We conduct detailed ablation studies with varying network depths to empirically verify the effectiveness and efficiency of the design of each component in our network architecture. We also compare the performance of our network against other model-driven methods and deep networks on the open SIRST dataset as well. The results suggest that our network yields a performance boost over its competitors. Our code, trained models, and results are available online.
Asymmetric Contextual Modulation for Infrared Small Target Detection
Sep 30, 2020
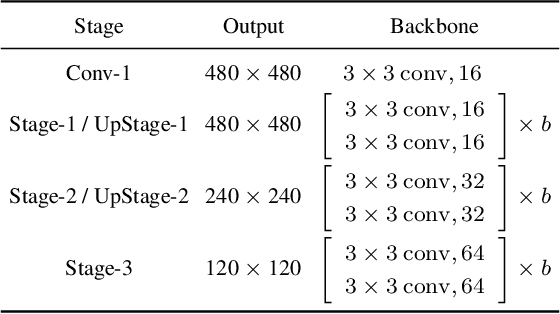
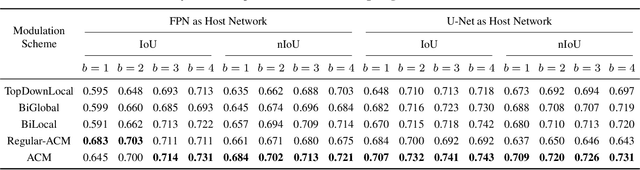

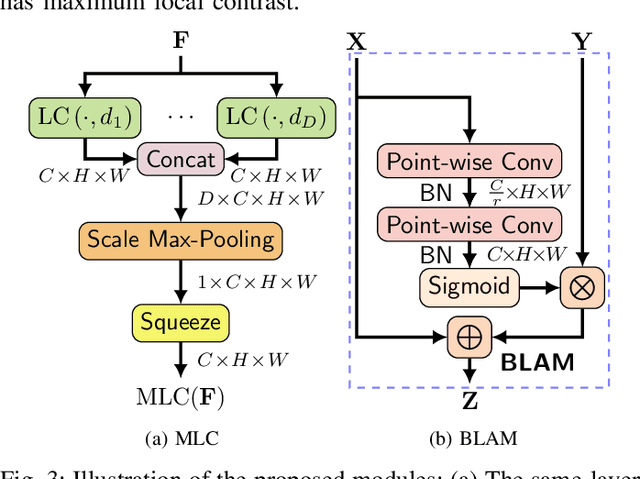
Single-frame infrared small target detection remains a challenge not only due to the scarcity of intrinsic target characteristics but also because of lacking a public dataset. In this paper, we first contribute an open dataset with high-quality annotations to advance the research in this field. We also propose an asymmetric contextual modulation module specially designed for detecting infrared small targets. To better highlight small targets, besides a top-down global contextual feedback, we supplement a bottom-up modulation pathway based on point-wise channel attention for exchanging high-level semantics and subtle low-level details. We report ablation studies and comparisons to state-of-the-art methods, where we find that our approach performs significantly better. Our dataset and code are available online.
Attentional Feature Fusion
Sep 29, 2020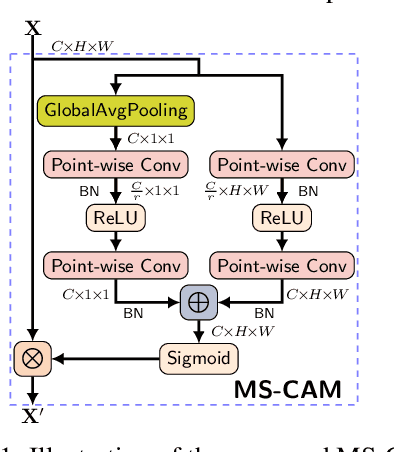

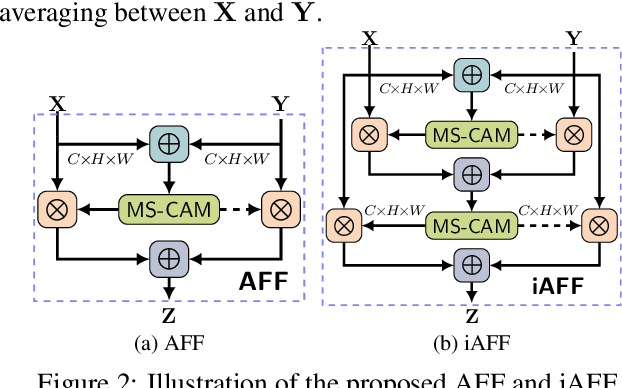
Feature fusion, the combination of features from different layers or branches, is an omnipresent part of modern network architectures. It is often implemented via simple operations, such as summation or concatenation, but this might not be the best choice. In this work, we propose a uniform and general scheme, namely attentional feature fusion, which is applicable for most common scenarios, including feature fusion induced by short and long skip connections as well as within Inception layers. To better fuse features of inconsistent semantics and scales, we propose a multi-scale channel attention module, which addresses issues that arise when fusing features given at different scales. We also demonstrate that the initial integration of feature maps can become a bottleneck and that this issue can be alleviated by adding another level of attention, which we refer to as iterative attentional feature fusion. With fewer layers or parameters, our models outperform state-of-the-art networks on both CIFAR-100 and ImageNet datasets, which suggests that more sophisticated attention mechanisms for feature fusion hold great potential to consistently yield better results compared to their direct counterparts. Our codes and trained models are available online.
Attention as Activation
Aug 02, 2020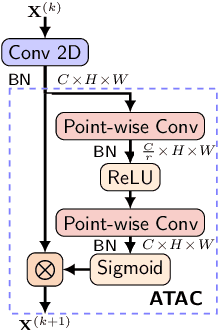
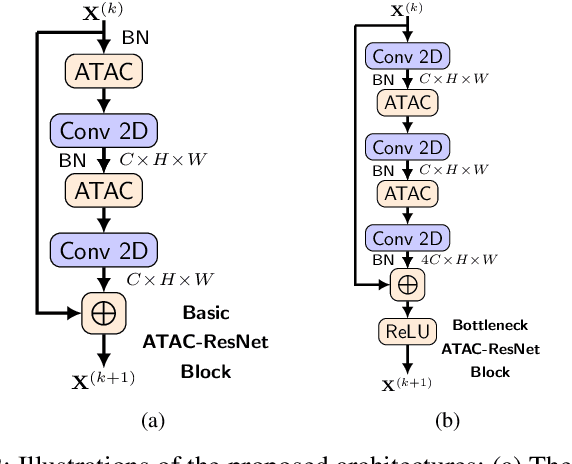
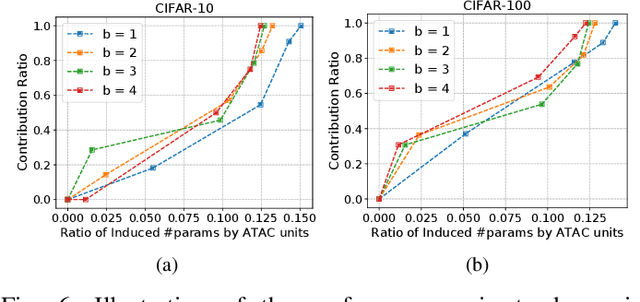
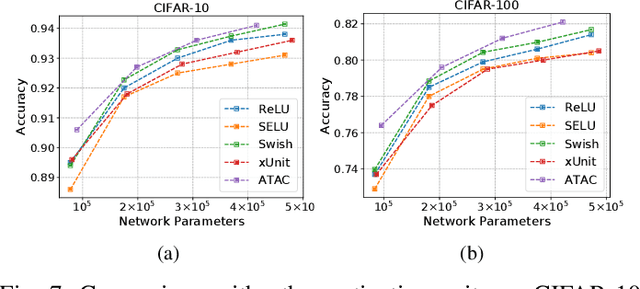
Activation functions and attention mechanisms are typically treated as having different purposes and have evolved differently. However, both concepts can be formulated as a non-linear gating function. Inspired by their similarity, we propose a novel type of activation units called attentional activation (ATAC) units as a unification of activation functions and attention mechanisms. In particular, we propose a local channel attention module for the simultaneous non-linear activation and element-wise feature refinement, which locally aggregates point-wise cross-channel feature contexts. By replacing the well-known rectified linear units by such ATAC units in convolutional networks, we can construct fully attentional networks that perform significantly better with a modest number of additional parameters. We conducted detailed ablation studies on the ATAC units using several host networks with varying network depths to empirically verify the effectiveness and efficiency of the units. Furthermore, we compared the performance of the ATAC units against existing activation functions as well as other attention mechanisms on the CIFAR-10, CIFAR-100, and ImageNet datasets. Our experimental results show that networks constructed with the proposed ATAC units generally yield performance gains over their competitors given a comparable number of parameters.
Improving Visual Feature Extraction in Glacial Environments
Aug 27, 2019

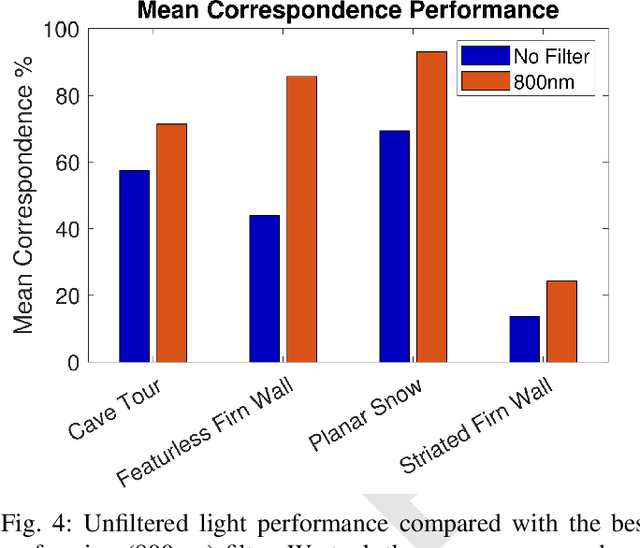
Glacial science could benefit tremendously from autonomous robots, but previous glacial robots have had perception issues in these colorless and featureless environments, specifically with visual feature extraction. Glaciologists use near-infrared imagery to reveal the underlying heterogeneous spatial structure of snow and ice, and we theorize that this hidden near-infrared structure could produce more and higher quality features than available in visible light. We took a custom camera rig to Igloo Cave at Mt. St. Helens to test our theory. The camera rig contains two identical machine vision cameras, one which was outfitted with multiple filters to see only near-infrared light. We extracted features from short video clips taken inside Igloo Cave at Mt. St. Helens, using three popular feature extractors (FAST, SIFT, and SURF). We quantified the number of features and their quality for visual navigation using feature correspondence and the epipolar constraint. Our results indicate that near-infrared imagery produces more features that tend to be of higher quality than that of visible light imagery.
Branching Gaussian Processes with Applications to Spatiotemporal Reconstruction of 3D Trees
Aug 14, 2016



We propose a robust method for estimating dynamic 3D curvilinear branching structure from monocular images. While 3D reconstruction from images has been widely studied, estimating thin structure has received less attention. This problem becomes more challenging in the presence of camera error, scene motion, and a constraint that curves are attached in a branching structure. We propose a new general-purpose prior, a branching Gaussian processes (BGP), that models spatial smoothness and temporal dynamics of curves while enforcing attachment between them. We apply this prior to fit 3D trees directly to image data, using an efficient scheme for approximate inference based on expectation propagation. The BGP prior's Gaussian form allows us to approximately marginalize over 3D trees with a given model structure, enabling principled comparison between tree models with varying complexity. We test our approach on a novel multi-view dataset depicting plants with known 3D structures and topologies undergoing small nonrigid motion. Our method outperforms a state-of-the-art 3D reconstruction method designed for non-moving thin structure. We evaluate under several common measures, and we propose a new measure for reconstructions of branching multi-part 3D scenes under motion.