 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Semantic Clustering in Deep Reinforcement Learning for Video Games
Sep 25, 2024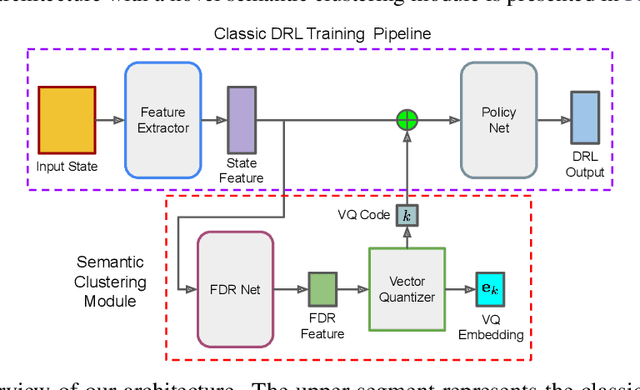
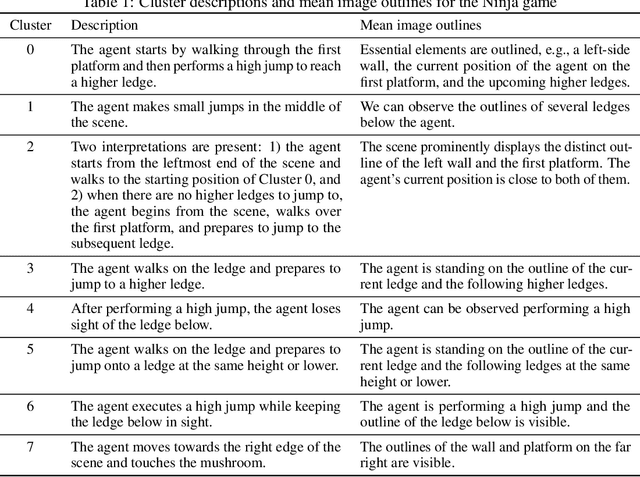
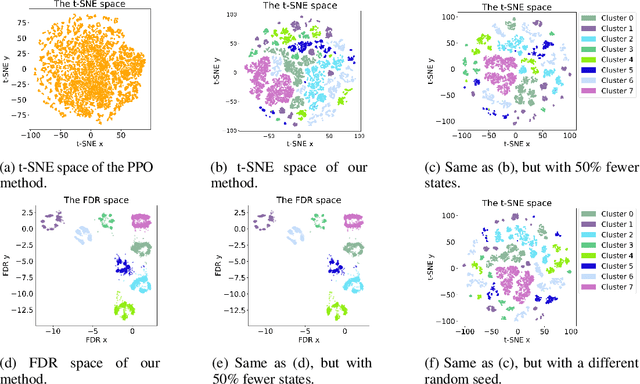

In this paper, we investigate the semantic clustering properties of deep reinforcement learning (DRL) for video games, enriching our understanding of the internal dynamics of DRL and advancing its interpretability. In this context, semantic clustering refers to the inherent capacity of neural networks to internally group video inputs based on semantic similarity. To achieve this, we propose a novel DRL architecture that integrates a semantic clustering module featuring both feature dimensionality reduction and online clustering. This module seamlessly integrates into the DRL training pipeline, addressing instability issues observed in previous t-SNE-based analysis methods and eliminating the necessity for extensive manual annotation of semantic analysis. Through experiments, we validate the effectiveness of the proposed module and the semantic clustering properties in DRL for video games. Additionally, based on these properties, we introduce new analytical methods to help understand the hierarchical structure of policies and the semantic distribution within the feature space.
Using Features at Multiple Temporal and Spatial Resolutions to Predict Human Behavior in Real Time
Nov 12, 2022



When performing complex tasks, humans naturally reason at multiple temporal and spatial resolutions simultaneously. We contend that for an artificially intelligent agent to effectively model human teammates, i.e., demonstrate computational theory of mind (ToM), it should do the same. In this paper, we present an approach for integrating high and low-resolution spatial and temporal information to predict human behavior in real time and evaluate it on data collected from human subjects performing simulated urban search and rescue (USAR) missions in a Minecraft-based environment. Our model composes neural networks for high and low-resolution feature extraction with a neural network for behavior prediction, with all three networks trained simultaneously. The high-resolution extractor encodes dynamically changing goals robustly by taking as input the Manhattan distance difference between the humans' Minecraft avatars and candidate goals in the environment for the latest few actions, computed from a high-resolution gridworld representation. In contrast, the low-resolution extractor encodes participants' historical behavior using a historical state matrix computed from a low-resolution graph representation. Through supervised learning, our model acquires a robust prior for human behavior prediction, and can effectively deal with long-term observations. Our experimental results demonstrate that our method significantly improves prediction accuracy compared to approaches that only use high-resolution information.
Deep Reinforcement Learning with Vector Quantized Encoding
Nov 12, 2022


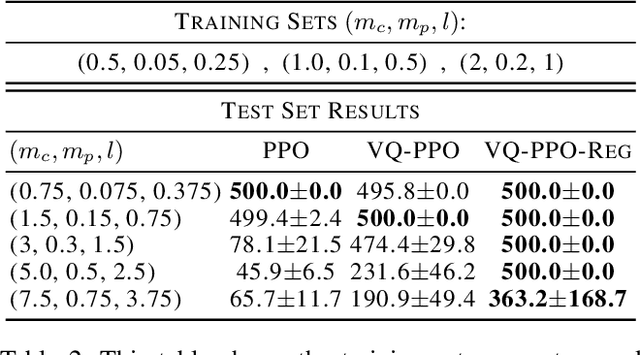
Human decision-making often involves combining similar states into categories and reasoning at the level of the categories rather than the actual states. Guided by this intuition, we propose a novel method for clustering state features in deep reinforcement learning (RL) methods to improve their interpretability. Specifically, we propose a plug-and-play framework termed \emph{vector quantized reinforcement learning} (VQ-RL) that extends classic RL pipelines with an auxiliary classification task based on vector quantized (VQ) encoding and aligns with policy training. The VQ encoding method categorizes features with similar semantics into clusters and results in tighter clusters with better separation compared to classic deep RL methods, thus enabling neural models to learn similarities and differences between states better. Furthermore, we introduce two regularization methods to help increase the separation between clusters and avoid the risks associated with VQ training. In simulations, we demonstrate that VQ-RL improves interpretability and investigate its impact on robustness and generalization of deep RL.