 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaterPark: A Robustness Assessment of Language Model Watermarking
Nov 20, 2024



To mitigate the misuse of large language models (LLMs), such as disinformation, automated phishing, and academic cheating, there is a pressing need for the capability of identifying LLM-generated texts. Watermarking emerges as one promising solution: it plants statistical signals into LLMs' generative processes and subsequently verifies whether LLMs produce given texts. Various watermarking methods (``watermarkers'') have been proposed; yet, due to the lack of unified evaluation platforms, many critical questions remain under-explored: i) What are the strengths/limitations of various watermarkers, especially their attack robustness? ii) How do various design choices impact their robustness? iii) How to optimally operate watermarkers in adversarial environments? To fill this gap, we systematize existing LLM watermarkers and watermark removal attacks, mapping out their design spaces. We then develop WaterPark, a unified platform that integrates 10 state-of-the-art watermarkers and 12 representative attacks. More importantly, leveraging WaterPark, we conduct a comprehensive assessment of existing watermarkers, unveiling the impact of various design choices on their attack robustness. For instance, a watermarker's resilience to increasingly intensive attacks hinges on its context dependency. We further explore the best practices to operate watermarkers in adversarial environments. For instance, using a generic detector alongside a watermark-specific detector improves the security of vulnerable watermarkers. We believe our study sheds light on current LLM watermarking techniques while WaterPark serves as a valuable testbed to facilitate future research.
Fewer is More: Trojan Attacks on Parameter-Efficient Fine-Tuning
Oct 04, 2023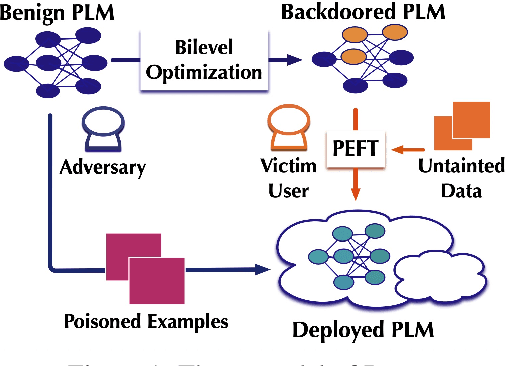


Parameter-efficient fine-tuning (PEFT) enables efficient adaptation of pre-trained language models (PLMs) to specific tasks. By tuning only a minimal set of (extra) parameters, PEFT achieves performance comparable to full fine-tuning. However, despite its prevalent use, the security implications of PEFT remain largely unexplored. In this paper, we conduct a pilot study revealing that PEFT exhibits unique vulnerability to trojan attacks. Specifically, we present PETA, a novel attack that accounts for downstream adaptation through bilevel optimization: the upper-level objective embeds the backdoor into a PLM while the lower-level objective simulates PEFT to retain the PLM's task-specific performance. With extensive evaluation across a variety of downstream tasks and trigger designs, we demonstrate PETA's effectiveness in terms of both attack success rate and unaffected clean accuracy, even after the victim user performs PEFT over the backdoored PLM using untainted data. Moreover, we empirically provide possible explanations for PETA's efficacy: the bilevel optimization inherently 'orthogonalizes' the backdoor and PEFT modules, thereby retaining the backdoor throughout PEFT. Based on this insight, we explore a simple defense that omits PEFT in selected layers of the backdoored PLM and unfreezes a subset of these layers' parameters, which is shown to effectively neutralize PETA.
Monitoring and Adapting ML Models on Mobile Devices
May 17, 2023



ML models are increasingly being pushed to mobile devices, for low-latency inference and offline operation. However, once the models are deployed, it is hard for ML operators to track their accuracy, which can degrade unpredictably (e.g., due to data drift). We design the first end-to-end system for continuously monitoring and adapting models on mobile devices without requiring feedback from users. Our key observation is that often model degradation is due to a specific root cause, which may affect a large group of devices. Therefore, once the system detects a consistent degradation across a large number of devices, it employs a root cause analysis to determine the origin of the problem and applies a cause-specific adaptation. We evaluate the system on two computer vision datasets, and show it consistently boosts accuracy compared to existing approaches. On a dataset containing photos collected from driving cars, our system improves the accuracy on average by 15%.