 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Randomized Smoothing: Certifying Multi-Step Defences against Adversarial Examples
Jun 14, 2024



We propose Adaptive Randomized Smoothing (ARS) to certify the predictions of our test-time adaptive models against adversarial examples. ARS extends the analysis of randomized smoothing using f-Differential Privacy to certify the adaptive composition of multiple steps. For the first time, our theory covers the sound adaptive composition of general and high-dimensional functions of noisy input. We instantiate ARS on deep image classification to certify predictions against adversarial examples of bounded $L_{\infty}$ norm. In the $L_{\infty}$ threat model, our flexibility enables adaptation through high-dimensional input-dependent masking. We design adaptivity benchmarks, based on CIFAR-10 and CelebA, and show that ARS improves accuracy by $2$ to $5\%$ points. On ImageNet, ARS improves accuracy by $1$ to $3\%$ points over standard RS without adaptivity.
Differentially Private Latent Diffusion Models
May 25, 2023
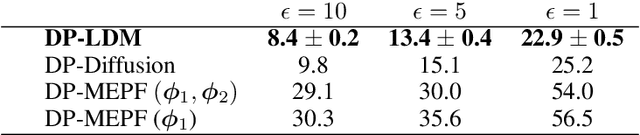
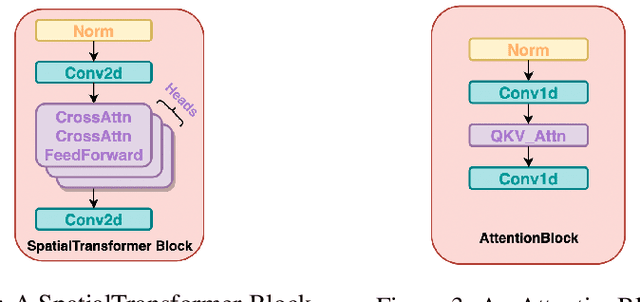

Diffusion models (DMs) are widely used for generating high-quality image datasets. However, since they operate directly in the high-dimensional pixel space, optimization of DMs is computationally expensive, requiring long training times. This contributes to large amounts of noise being injected into the differentially private learning process, due to the composability property of differential privacy. To address this challenge, we propose training Latent Diffusion Models (LDMs) with differential privacy. LDMs use powerful pre-trained autoencoders to reduce the high-dimensional pixel space to a much lower-dimensional latent space, making training DMs more efficient and fast. Unlike [Ghalebikesabi et al., 2023] that pre-trains DMs with public data then fine-tunes them with private data, we fine-tune only the attention modules of LDMs at varying layers with privacy-sensitive data, reducing the number of trainable parameters by approximately 96% compared to fine-tuning the entire DM. We test our algorithm on several public-private data pairs, such as ImageNet as public data and CIFAR10 and CelebA as private data, and SVHN as public data and MNIST as private data. Our approach provides a promising direction for training more powerful, yet training-efficient differentially private DMs that can produce high-quality synthetic images.