 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal expressive personality recognition in data non-ideal audiovisual based on multi-scale feature enhancement and modal augment
Paper and Code
Mar 08, 2025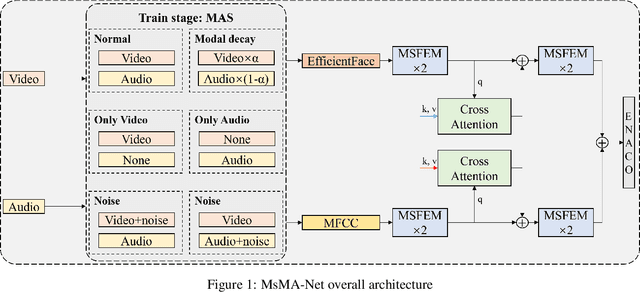

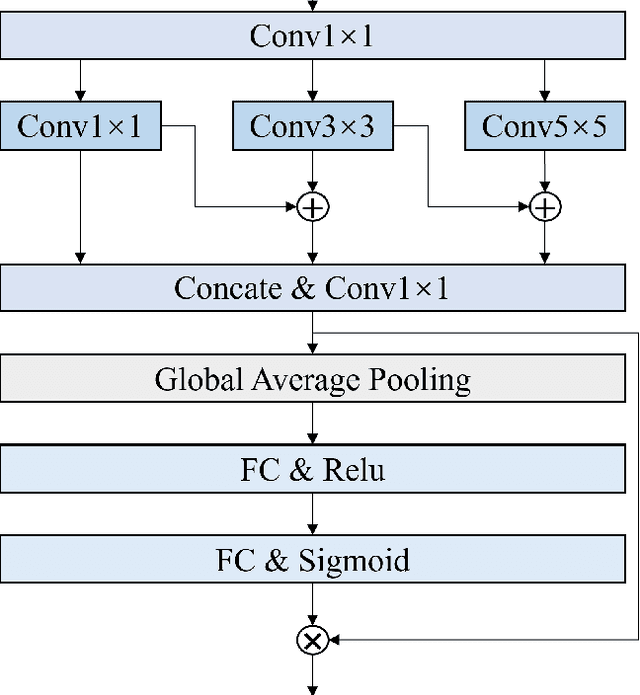

Automatic personality recognition is a research hotspot in the intersection of computer science and psychology, and in human-computer interaction, personalised has a wide range of applications services and other scenarios. In this paper, an end-to-end multimodal performance personality is established for both visual and auditory modal datarecognition network , and the through feature-level fusion , which effectively of the two modalities is carried out the cross-attention mechanismfuses the features of the two modal data; and a is proposed multiscale feature enhancement modalitiesmodule , which enhances for visual and auditory boththe expression of the information of effective the features and suppresses the interference of the redundant information. In addition, during the training process, this paper proposes a modal enhancement training strategy to simulate non-ideal such as modal loss and noise interferencedata situations , which enhances the adaptability ofand the model to non-ideal data scenarios improves the robustness of the model. Experimental results show that the method proposed in this paper is able to achieve an average Big Five personality accuracy of , which outperforms existing 0.916 on the personality analysis dataset ChaLearn First Impressionother methods based on audiovisual and audio-visual both modalities. The ablation experiments also validate our proposed , respectivelythe contribution of module and modality enhancement strategy to the model performance. Finally, we simulate in the inference phase multi-scale feature enhancement six non-ideal data scenarios to verify the modal enhancement strategy's improvement in model robustness.