 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal expressive personality recognition in data non-ideal audiovisual based on multi-scale feature enhancement and modal augment
Mar 08, 2025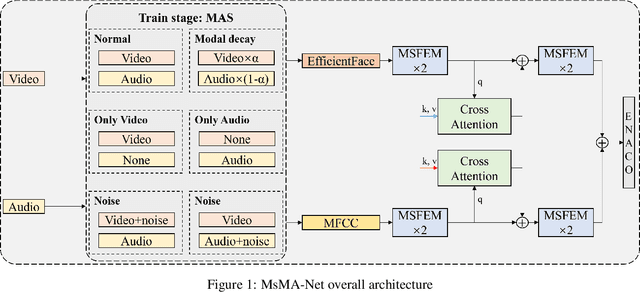

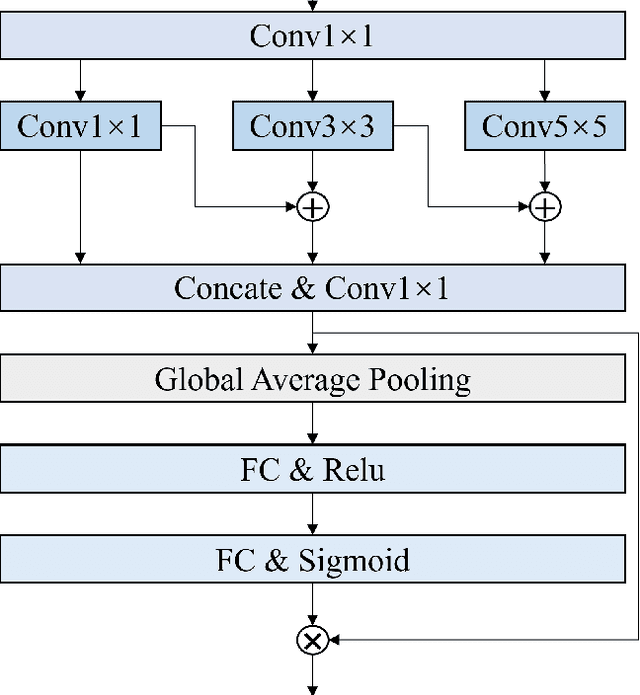

Automatic personality recognition is a research hotspot in the intersection of computer science and psychology, and in human-computer interaction, personalised has a wide range of applications services and other scenarios. In this paper, an end-to-end multimodal performance personality is established for both visual and auditory modal datarecognition network , and the through feature-level fusion , which effectively of the two modalities is carried out the cross-attention mechanismfuses the features of the two modal data; and a is proposed multiscale feature enhancement modalitiesmodule , which enhances for visual and auditory boththe expression of the information of effective the features and suppresses the interference of the redundant information. In addition, during the training process, this paper proposes a modal enhancement training strategy to simulate non-ideal such as modal loss and noise interferencedata situations , which enhances the adaptability ofand the model to non-ideal data scenarios improves the robustness of the model. Experimental results show that the method proposed in this paper is able to achieve an average Big Five personality accuracy of , which outperforms existing 0.916 on the personality analysis dataset ChaLearn First Impressionother methods based on audiovisual and audio-visual both modalities. The ablation experiments also validate our proposed , respectivelythe contribution of module and modality enhancement strategy to the model performance. Finally, we simulate in the inference phase multi-scale feature enhancement six non-ideal data scenarios to verify the modal enhancement strategy's improvement in model robustness.
Prior-based Objective Inference Mining Potential Uncertainty for Facial Expression Recognition
Nov 20, 2024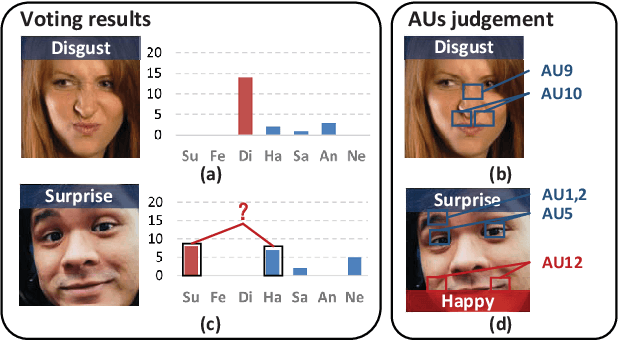
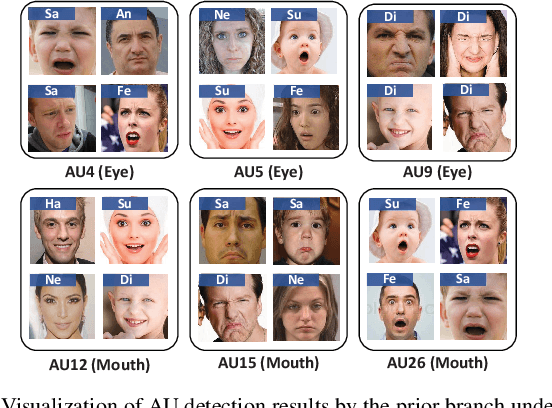
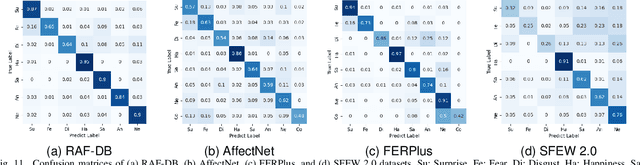
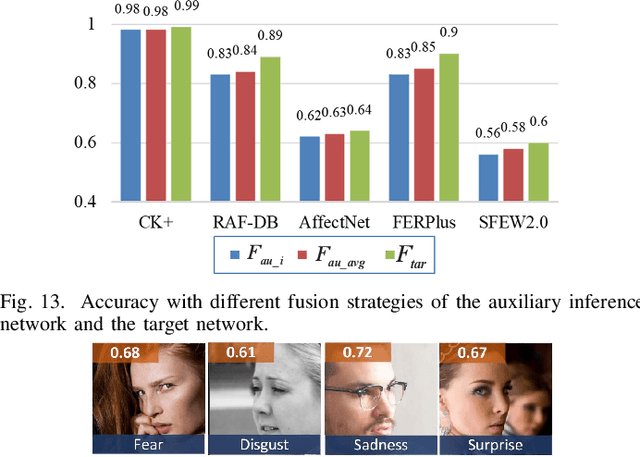
Annotation ambiguity caused by the inherent subjectivity of visual judgment has always been a major challenge for Facial Expression Recognition (FER) tasks, particularly for largescale datasets from in-the-wild scenarios. A potential solution is the evaluation of relatively objective emotional distributions to help mitigate the ambiguity of subjective annotations. To this end, this paper proposes a novel Prior-based Objective Inference (POI) network. This network employs prior knowledge to derive a more objective and varied emotional distribution and tackles the issue of subjective annotation ambiguity through dynamic knowledge transfer. POI comprises two key networks: Firstly, the Prior Inference Network (PIN) utilizes the prior knowledge of AUs and emotions to capture intricate motion details. To reduce over-reliance on priors and facilitate objective emotional inference, PIN aggregates inferential knowledge from various key facial subregions, encouraging mutual learning. Secondly, the Target Recognition Network (TRN) integrates subjective emotion annotations and objective inference soft labels provided by the PIN, fostering an understanding of inherent facial expression diversity, thus resolving annotation ambiguity. Moreover, we introduce an uncertainty estimation module to quantify and balance facial expression confidence. This module enables a flexible approach to dealing with the uncertainties of subjective annotations. Extensive experiments show that POI exhibits competitive performance on both synthetic noisy datasets and multiple real-world datasets. All codes and training logs will be publicly available at https://github.com/liuhw01/POI.
Norface: Improving Facial Expression Analysis by Identity Normalization
Jul 22, 2024



Facial Expression Analysis remains a challenging task due to unexpected task-irrelevant noise, such as identity, head pose, and background. To address this issue, this paper proposes a novel framework, called Norface, that is unified for both Action Unit (AU) analysis and Facial Emotion Recognition (FER) tasks. Norface consists of a normalization network and a classification network. First, the carefully designed normalization network struggles to directly remove the above task-irrelevant noise, by maintaining facial expression consistency but normalizing all original images to a common identity with consistent pose, and background. Then, these additional normalized images are fed into the classification network. Due to consistent identity and other factors (e.g. head pose, background, etc.), the normalized images enable the classification network to extract useful expression information more effectively. Additionally, the classification network incorporates a Mixture of Experts to refine the latent representation, including handling the input of facial representations and the output of multiple (AU or emotion) labels. Extensive experiments validate the carefully designed framework with the insight of identity normalization. The proposed method outperforms existing SOTA methods in multiple facial expression analysis tasks, including AU detection, AU intensity estimation, and FER tasks, as well as their cross-dataset tasks. For the normalized datasets and code please visit {https://norface-fea.github.io/}.
A Review of Intelligent Music Generation Systems
Nov 22, 2022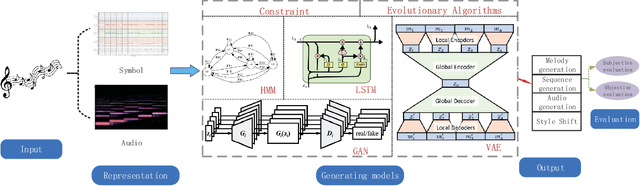

Intelligent music generation, one of the most popular subfields of computer creativity, can lower the creative threshold for non-specialists and increase the efficiency of music creation. In the last five years, the quality of algorithm-based automatic music generation has increased significantly, motivated by the use of modern generative algorithms to learn the patterns implicit within a piece of music based on rule constraints or a musical corpus, thus generating music samples in various styles. Some of the available literature reviews lack a systematic benchmark of generative models and are traditional and conservative in their perspective, resulting in a vision of the future development of the field that is not deeply integrated with the current rapid scientific progress. In this paper, we conduct a comprehensive survey and analysis of recent intelligent music generation techniques,provide a critical discussion, explicitly identify their respective characteristics, and present them in a general table. We first introduce how music as a stream of information is encoded and the relevant datasets, then compare different types of generation algorithms, summarize their strengths and weaknesses, and discuss existing methods for evaluation. Finally, the development of artificial intelligence in composition is studied, especially by comparing the different characteristics of music generation techniques in the East and West and analyzing the development prospects in this field.