 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorface: Improving Facial Expression Analysis by Identity Normalization
Jul 22, 2024



Facial Expression Analysis remains a challenging task due to unexpected task-irrelevant noise, such as identity, head pose, and background. To address this issue, this paper proposes a novel framework, called Norface, that is unified for both Action Unit (AU) analysis and Facial Emotion Recognition (FER) tasks. Norface consists of a normalization network and a classification network. First, the carefully designed normalization network struggles to directly remove the above task-irrelevant noise, by maintaining facial expression consistency but normalizing all original images to a common identity with consistent pose, and background. Then, these additional normalized images are fed into the classification network. Due to consistent identity and other factors (e.g. head pose, background, etc.), the normalized images enable the classification network to extract useful expression information more effectively. Additionally, the classification network incorporates a Mixture of Experts to refine the latent representation, including handling the input of facial representations and the output of multiple (AU or emotion) labels. Extensive experiments validate the carefully designed framework with the insight of identity normalization. The proposed method outperforms existing SOTA methods in multiple facial expression analysis tasks, including AU detection, AU intensity estimation, and FER tasks, as well as their cross-dataset tasks. For the normalized datasets and code please visit {https://norface-fea.github.io/}.
Global-to-local Expression-aware Embeddings for Facial Action Unit Detection
Oct 28, 2022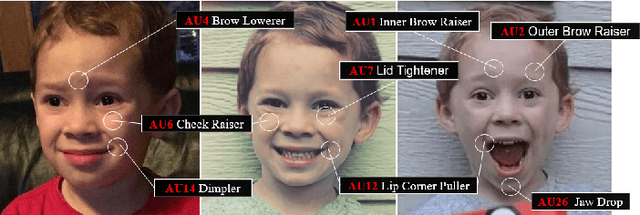
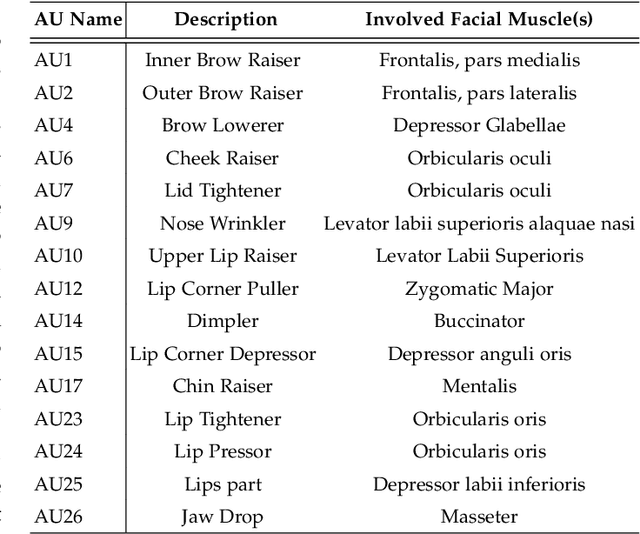
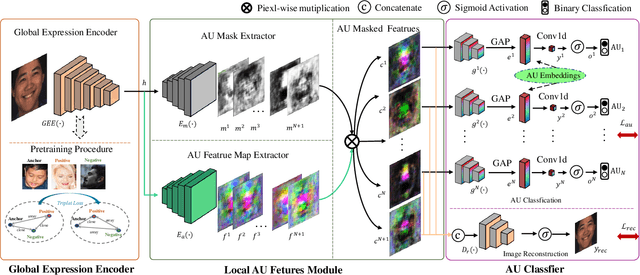

Expressions and facial action units (AUs) are two levels of facial behavior descriptors. Expression auxiliary information has been widely used to improve the AU detection performance. However, most existing expression representations can only describe pre-determined discrete categories (e.g., Angry, Disgust, Happy, Sad, etc.) and cannot capture subtle expression transformations like AUs. In this paper, we propose a novel fine-grained \textsl{Global Expression representation Encoder} to capture subtle and continuous facial movements, to promote AU detection. To obtain such a global expression representation, we propose to train an expression embedding model on a large-scale expression dataset according to global expression similarity. Moreover, considering the local definition of AUs, it is essential to extract local AU features. Therefore, we design a \textsl{Local AU Features Module} to generate local facial features for each AU. Specifically, it consists of an AU feature map extractor and a corresponding AU mask extractor. First, the two extractors transform the global expression representation into AU feature maps and masks, respectively. Then, AU feature maps and their corresponding AU masks are multiplied to generate AU masked features focusing on local facial region. Finally, the AU masked features are fed into an AU classifier for judging the AU occurrence. Extensive experiment results demonstrate the superiority of our proposed method. Our method validly outperforms previous works and achieves state-of-the-art performances on widely-used face datasets, including BP4D, DISFA, and BP4D+.
Facial Action Unit Detection and Intensity Estimation from Self-supervised Representation
Oct 28, 2022



As a fine-grained and local expression behavior measurement, facial action unit (FAU) analysis (e.g., detection and intensity estimation) has been documented for its time-consuming, labor-intensive, and error-prone annotation. Thus a long-standing challenge of FAU analysis arises from the data scarcity of manual annotations, limiting the generalization ability of trained models to a large extent. Amounts of previous works have made efforts to alleviate this issue via semi/weakly supervised methods and extra auxiliary information. However, these methods still require domain knowledge and have not yet avoided the high dependency on data annotation. This paper introduces a robust facial representation model MAE-Face for AU analysis. Using masked autoencoding as the self-supervised pre-training approach, MAE-Face first learns a high-capacity model from a feasible collection of face images without additional data annotations. Then after being fine-tuned on AU datasets, MAE-Face exhibits convincing performance for both AU detection and AU intensity estimation, achieving a new state-of-the-art on nearly all the evaluation results. Further investigation shows that MAE-Face achieves decent performance even when fine-tuned on only 1\% of the AU training set, strongly proving its robustness and generalization performance.
Transformer-based Multimodal Information Fusion for Facial Expression Analysis
Mar 23, 2022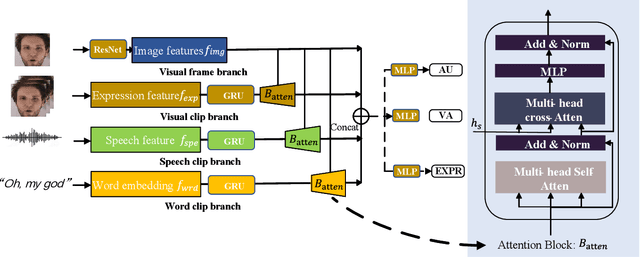
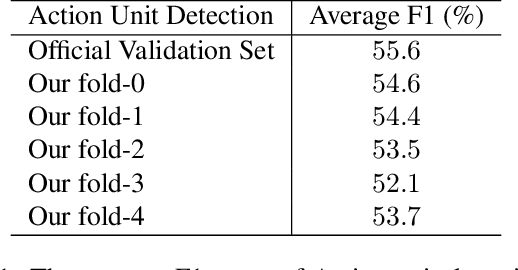

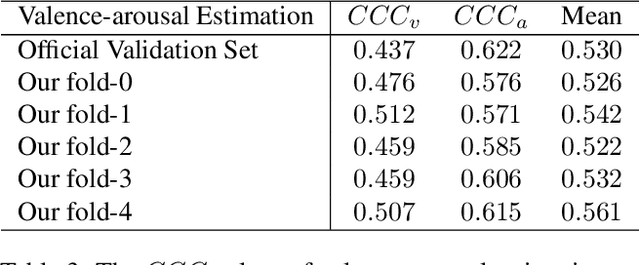
Facial expression analysis has been a crucial research problem in the computer vision area. With the recent development of deep learning techniques and large-scale in-the-wild annotated datasets, facial expression analysis is now aimed at challenges in real world settings. In this paper, we introduce our submission to CVPR2022 Competition on Affective Behavior Analysis in-the-wild (ABAW) that defines four competition tasks, including expression classification, action unit detection, valence-arousal estimation, and a multi-task-learning. The available multimodal information consist of spoken words, speech prosody, and visual expression in videos. Our work proposes four unified transformer-based network frameworks to create the fusion of the above multimodal information. The preliminary results on the official Aff-Wild2 dataset are reported and demonstrate the effectiveness of our proposed method.