 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Multimodal Information Fusion for Facial Expression Analysis
Paper and Code
Mar 23, 2022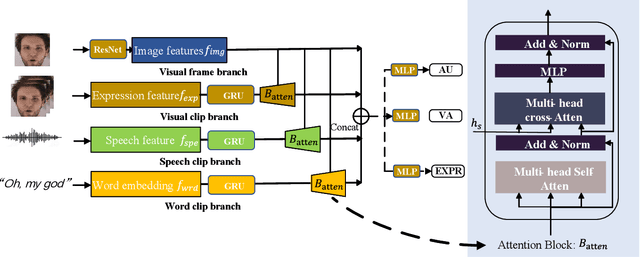
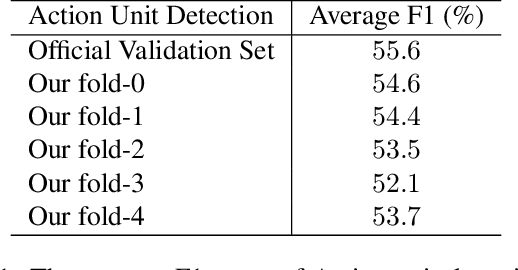

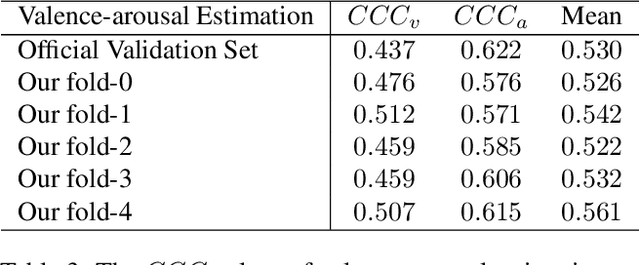
Facial expression analysis has been a crucial research problem in the computer vision area. With the recent development of deep learning techniques and large-scale in-the-wild annotated datasets, facial expression analysis is now aimed at challenges in real world settings. In this paper, we introduce our submission to CVPR2022 Competition on Affective Behavior Analysis in-the-wild (ABAW) that defines four competition tasks, including expression classification, action unit detection, valence-arousal estimation, and a multi-task-learning. The available multimodal information consist of spoken words, speech prosody, and visual expression in videos. Our work proposes four unified transformer-based network frameworks to create the fusion of the above multimodal information. The preliminary results on the official Aff-Wild2 dataset are reported and demonstrate the effectiveness of our proposed method.