 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Up ESM2 Architectures for Long Protein Sequences Analysis: Long and Quantized Approaches
Jan 13, 2025Various approaches utilizing Transformer architectures have achieved state-of-the-art results in Natural Language Processing (NLP). Based on this success, numerous architectures have been proposed for other types of data, such as in biology, particularly for protein sequences. Notably among these are the ESM2 architectures, pre-trained on billions of proteins, which form the basis of various state-of-the-art approaches in the field. However, the ESM2 architectures have a limitation regarding input size, restricting it to 1,022 amino acids, which necessitates the use of preprocessing techniques to handle sequences longer than this limit. In this paper, we present the long and quantized versions of the ESM2 architectures, doubling the input size limit to 2,048 amino acids.
P-NOC: Adversarial CAM Generation for Weakly Supervised Semantic Segmentation
May 21, 2023
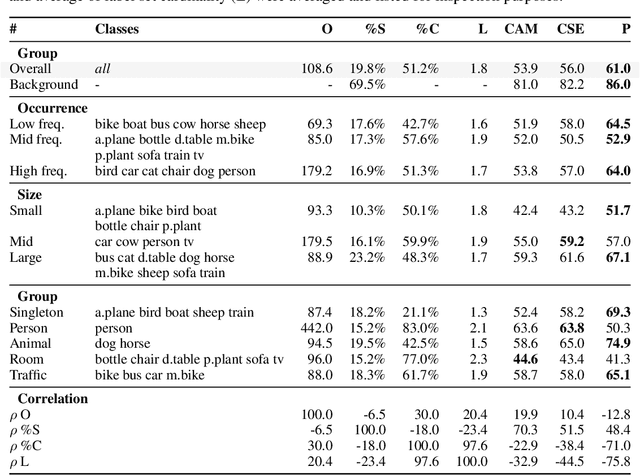
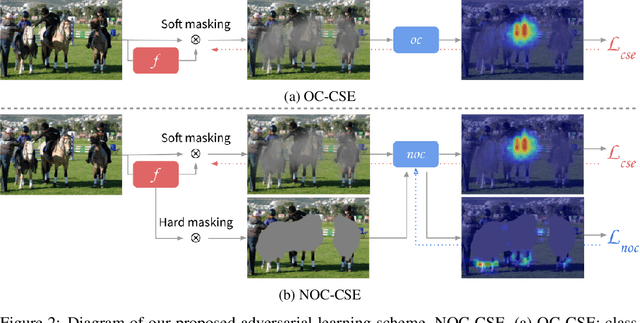

To mitigate the necessity for large amounts of supervised segmentation annotation sets, multiple Weakly Supervised Semantic Segmentation (WSSS) strategies have been devised. These will often rely on advanced data and model regularization strategies to instigate the development of useful properties (e.g., prediction completeness and fidelity to semantic boundaries) in segmentation priors, notwithstanding the lack of annotated information. In this work, we first create a strong baseline by analyzing complementary WSSS techniques and regularizing strategies, considering their strengths and limitations. We then propose a new Class-specific Adversarial Erasing strategy, comprising two adversarial CAM generating networks being gradually refined to produce robust semantic segmentation proposals. Empirical results suggest that our approach induces substantial improvement in the effectiveness of the baseline, resulting in a noticeable improvement over both Pascal VOC 2012 and MS COCO 2014 datasets.