 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing LLMs with MoP: Mixture of Pruners
Feb 05, 2026The high computational demands of Large Language Models (LLMs) motivate methods that reduce parameter count and accelerate inference. In response, model pruning emerges as an effective strategy, yet current methods typically focus on a single dimension-depth or width. We introduce MoP (Mixture of Pruners), an iterative framework that unifies these dimensions. At each iteration, MoP generates two branches-pruning in depth versus pruning in width-and selects a candidate to advance the path. On LLaMA-2 and LLaMA-3, MoP advances the frontier of structured pruning, exceeding the accuracy of competing methods across a broad set of compression regimes. It also consistently outperforms depth-only and width-only pruning. Furthermore, MoP translates structural pruning into real speedup, reducing end-to-end latency by 39% at 40% compression. Finally, extending MoP to the vision-language model LLaVA-1.5, we notably improve computational efficiency and demonstrate that text-only recovery fine-tuning can restore performance even on visual tasks.
Layer-wise LoRA fine-tuning: a similarity metric approach
Feb 05, 2026Pre-training Large Language Models (LLMs) on web-scale datasets becomes fundamental for advancing general-purpose AI. In contrast, enhancing their predictive performance on downstream tasks typically involves adapting their knowledge through fine-tuning. Parameter-efficient fine-tuning techniques, such as Low-Rank Adaptation (LoRA), aim to reduce the computational cost of this process by freezing the pre-trained model and updating a smaller number of parameters. In comparison to full fine-tuning, these methods achieve over 99\% reduction in trainable parameter count, depending on the configuration. Unfortunately, such a reduction may prove insufficient as LLMs continue to grow in scale. In this work, we address the previous problem by systematically selecting only a few layers to fine-tune using LoRA or its variants. We argue that not all layers contribute equally to the model adaptation. Leveraging this, we identify the most relevant layers to fine-tune by measuring their contribution to changes in internal representations. Our method is orthogonal to and readily compatible with existing low-rank adaptation techniques. We reduce the trainable parameters in LoRA-based techniques by up to 50\%, while maintaining the predictive performance across different models and tasks. Specifically, on encoder-only architectures, this reduction in trainable parameters leads to a negligible predictive performance drop on the GLUE benchmark. On decoder-only architectures, we achieve a small drop or even improvements in the predictive performance on mathematical problem-solving capabilities and coding tasks. Finally, this effectiveness extends to multimodal models, for which we also observe competitive results relative to fine-tuning with LoRA modules in all layers. Code is available at: https://github.com/c2d-usp/Layer-wise-LoRA-with-CKA
Pruning Everything, Everywhere, All at Once
Jun 04, 2025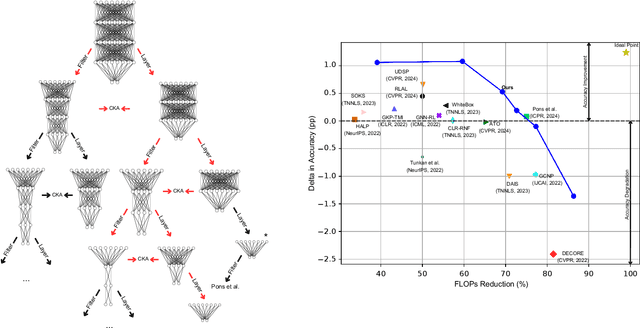

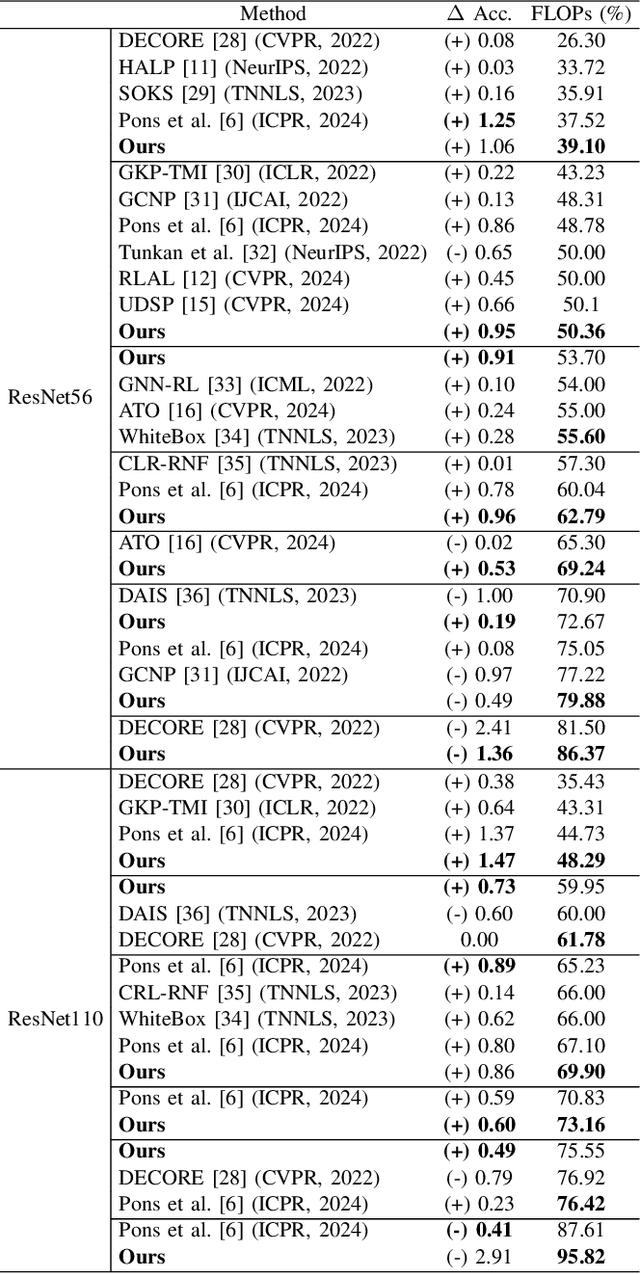
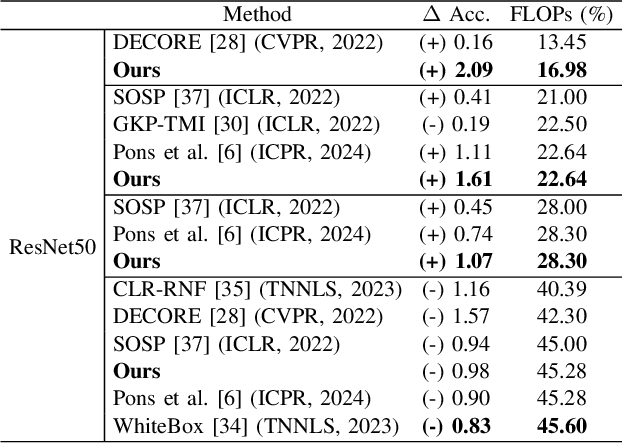
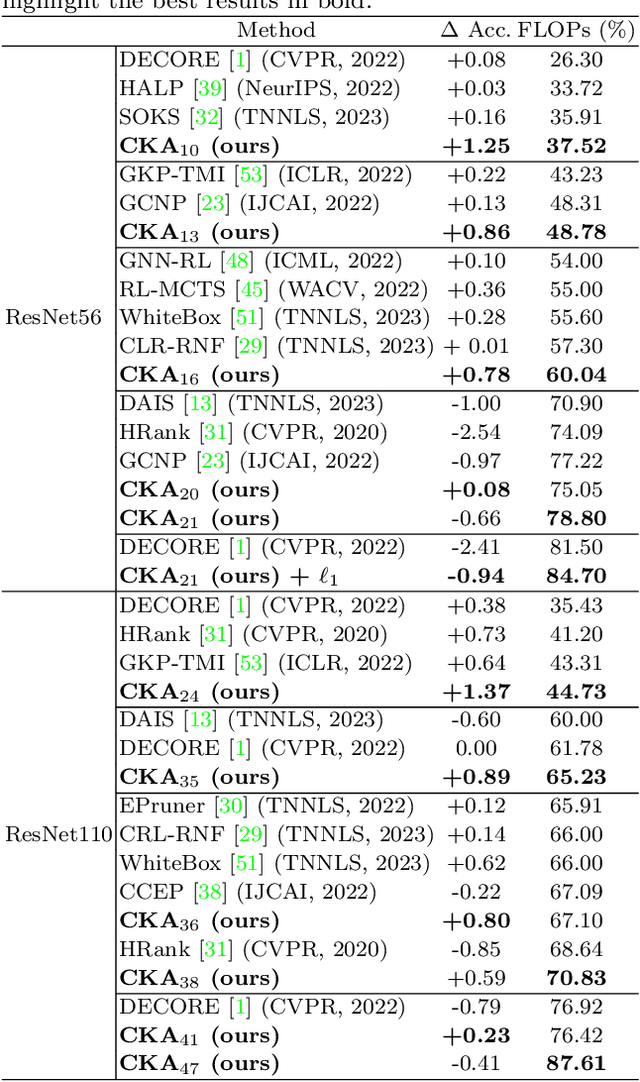
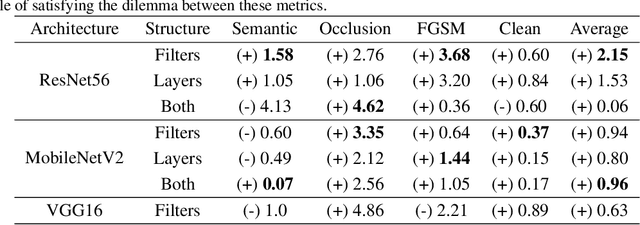
Deep learning stands as the modern paradigm for solving cognitive tasks. However, as the problem complexity increases, models grow deeper and computationally prohibitive, hindering advancements in real-world and resource-constrained applications. Extensive studies reveal that pruning structures in these models efficiently reduces model complexity and improves computational efficiency. Successful strategies in this sphere include removing neurons (i.e., filters, heads) or layers, but not both together. Therefore, simultaneously pruning different structures remains an open problem. To fill this gap and leverage the benefits of eliminating neurons and layers at once, we propose a new method capable of pruning different structures within a model as follows. Given two candidate subnetworks (pruned models), one from layer pruning and the other from neuron pruning, our method decides which to choose by selecting the one with the highest representation similarity to its parent (the network that generates the subnetworks) using the Centered Kernel Alignment metric. Iteratively repeating this process provides highly sparse models that preserve the original predictive ability. Throughout extensive experiments on standard architectures and benchmarks, we confirm the effectiveness of our approach and show that it outperforms state-of-the-art layer and filter pruning techniques. At high levels of Floating Point Operations reduction, most state-of-the-art methods degrade accuracy, whereas our approach either improves it or experiences only a minimal drop. Notably, on the popular ResNet56 and ResNet110, we achieve a milestone of 86.37% and 95.82% FLOPs reduction. Besides, our pruned models obtain robustness to adversarial and out-of-distribution samples and take an important step towards GreenAI, reducing carbon emissions by up to 83.31%. Overall, we believe our work opens a new chapter in pruning.
Efficient LLMs with AMP: Attention Heads and MLP Pruning
Apr 29, 2025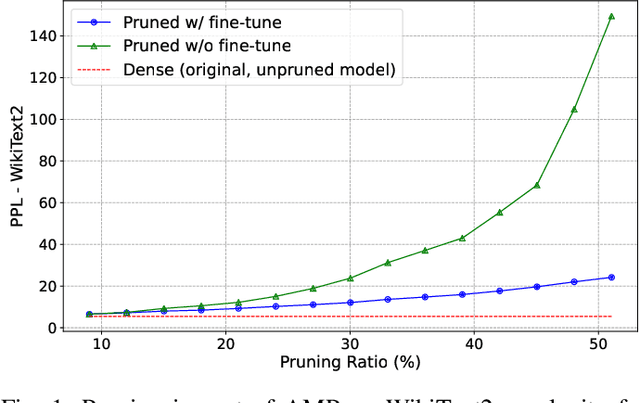
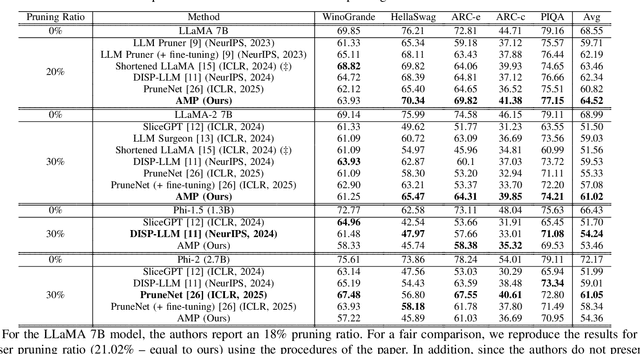
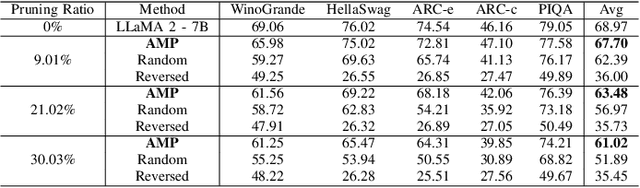

Deep learning drives a new wave in computing systems and triggers the automation of increasingly complex problems. In particular, Large Language Models (LLMs) have significantly advanced cognitive tasks, often matching or even surpassing human-level performance. However, their extensive parameters result in high computational costs and slow inference, posing challenges for deployment in resource-limited settings. Among the strategies to overcome the aforementioned challenges, pruning emerges as a successful mechanism since it reduces model size while maintaining predictive ability. In this paper, we introduce AMP: Attention Heads and MLP Pruning, a novel structured pruning method that efficiently compresses LLMs by removing less critical structures within Multi-Head Attention (MHA) and Multilayer Perceptron (MLP). By projecting the input data onto weights, AMP assesses structural importance and overcomes the limitations of existing techniques, which often fall short in flexibility or efficiency. In particular, AMP surpasses the current state-of-the-art on commonsense reasoning tasks by up to 1.49 percentage points, achieving a 30% pruning ratio with minimal impact on zero-shot task performance. Moreover, AMP also improves inference speeds, making it well-suited for deployment in resource-constrained environments. We confirm the flexibility of AMP on different families of LLMs, including LLaMA and Phi.
Layer Pruning with Consensus: A Triple-Win Solution
Nov 21, 2024Layer pruning offers a promising alternative to standard structured pruning, effectively reducing computational costs, latency, and memory footprint. While notable layer-pruning approaches aim to detect unimportant layers for removal, they often rely on single criteria that may not fully capture the complex, underlying properties of layers. We propose a novel approach that combines multiple similarity metrics into a single expressive measure of low-importance layers, called the Consensus criterion. Our technique delivers a triple-win solution: low accuracy drop, high-performance improvement, and increased robustness to adversarial attacks. With up to 78.80% FLOPs reduction and performance on par with state-of-the-art methods across different benchmarks, our approach reduces energy consumption and carbon emissions by up to 66.99% and 68.75%, respectively. Additionally, it avoids shortcut learning and improves robustness by up to 4 percentage points under various adversarial attacks. Overall, the Consensus criterion demonstrates its effectiveness in creating robust, efficient, and environmentally friendly pruned models.
Effective Layer Pruning Through Similarity Metric Perspective
May 27, 2024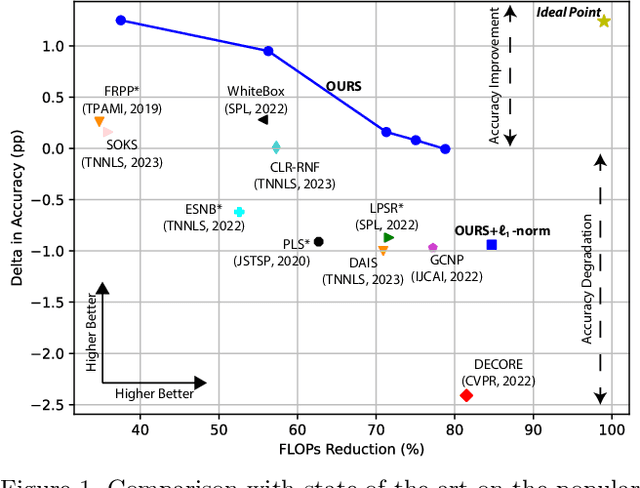
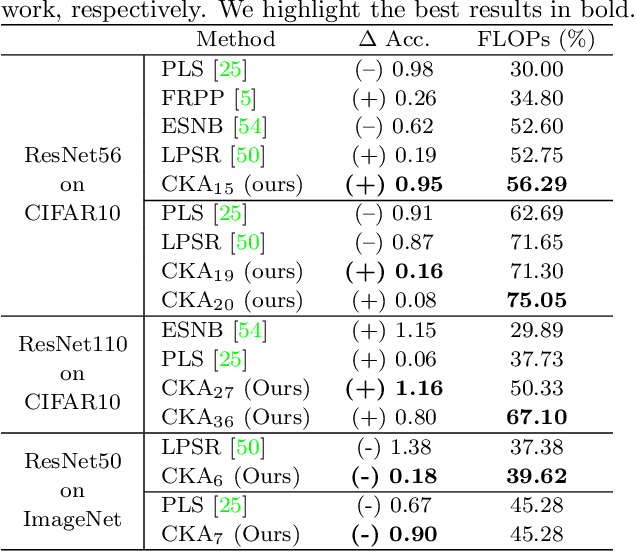
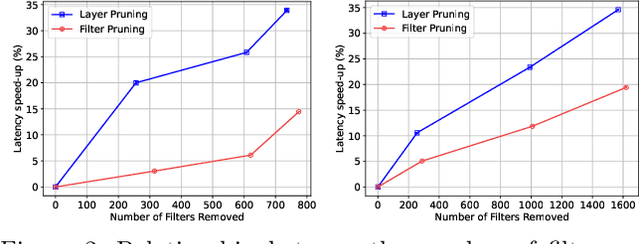
Deep neural networks have been the predominant paradigm in machine learning for solving cognitive tasks. Such models, however, are restricted by a high computational overhead, limiting their applicability and hindering advancements in the field. Extensive research demonstrated that pruning structures from these models is a straightforward approach to reducing network complexity. In this direction, most efforts focus on removing weights or filters. Studies have also been devoted to layer pruning as it promotes superior computational gains. However, layer pruning often hurts the network predictive ability (i.e., accuracy) at high compression rates. This work introduces an effective layer-pruning strategy that meets all underlying properties pursued by pruning methods. Our method estimates the relative importance of a layer using the Centered Kernel Alignment (CKA) metric, employed to measure the similarity between the representations of the unpruned model and a candidate layer for pruning. We confirm the effectiveness of our method on standard architectures and benchmarks, in which it outperforms existing layer-pruning strategies and other state-of-the-art pruning techniques. Particularly, we remove more than 75% of computation while improving predictive ability. At higher compression regimes, our method exhibits negligible accuracy drop, while other methods notably deteriorate model accuracy. Apart from these benefits, our pruned models exhibit robustness to adversarial and out-of-distribution samples.
When Layers Play the Lottery, all Tickets Win at Initialization
Jan 25, 2023Pruning is a standard technique for reducing the computational cost of deep networks. Many advances in pruning leverage concepts from the Lottery Ticket Hypothesis (LTH). LTH reveals that inside a trained dense network exists sparse subnetworks (tickets) able to achieve similar accuracy (i.e., win the lottery - winning tickets). Pruning at initialization focuses on finding winning tickets without training a dense network. Studies on these concepts share the trend that subnetworks come from weight or filter pruning. In this work, we investigate LTH and pruning at initialization from the lens of layer pruning. First, we confirm the existence of winning tickets when the pruning process removes layers. Leveraged by this observation, we propose to discover these winning tickets at initialization, eliminating the requirement of heavy computational resources for training the initial (over-parameterized) dense network. Extensive experiments show that our winning tickets notably speed up the training phase and reduce up to 51% of carbon emission, an important step towards democratization and green Artificial Intelligence. Beyond computational benefits, our winning tickets exhibit robustness against adversarial and out-of-distribution examples. Finally, we show that our subnetworks easily win the lottery at initialization while tickets from filter removal (the standard structured LTH) hardly become winning tickets.
On the Effect of Pruning on Adversarial Robustness
Aug 10, 2021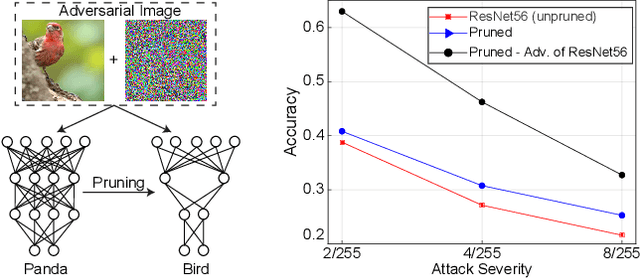
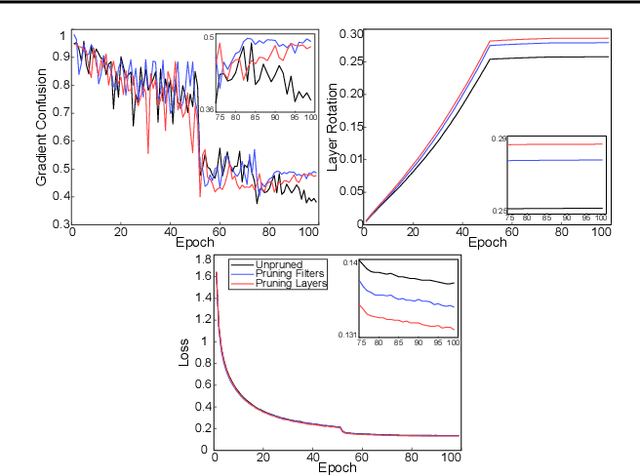
Pruning is a well-known mechanism for reducing the computational cost of deep convolutional networks. However, studies have shown the potential of pruning as a form of regularization, which reduces overfitting and improves generalization. We demonstrate that this family of strategies provides additional benefits beyond computational performance and generalization. Our analyses reveal that pruning structures (filters and/or layers) from convolutional networks increase not only generalization but also robustness to adversarial images (natural images with content modified). Such achievements are possible since pruning reduces network capacity and provides regularization, which have been proven effective tools against adversarial images. In contrast to promising defense mechanisms that require training with adversarial images and careful regularization, we show that pruning obtains competitive results considering only natural images (e.g., the standard and low-cost training). We confirm these findings on several adversarial attacks and architectures; thus suggesting the potential of pruning as a novel defense mechanism against adversarial images.
Depth-Wise Neural Architecture Search
Apr 23, 2020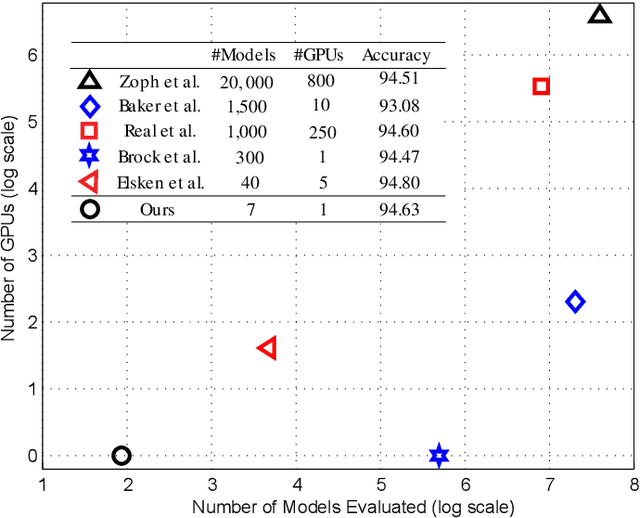
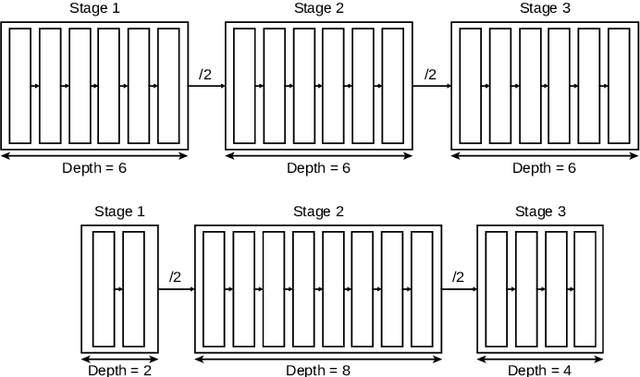
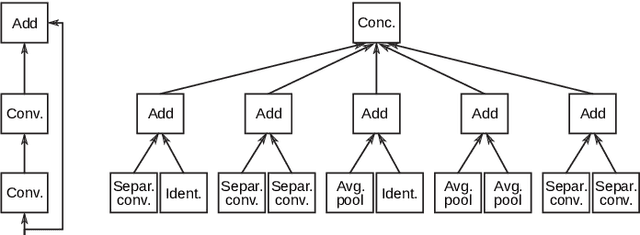
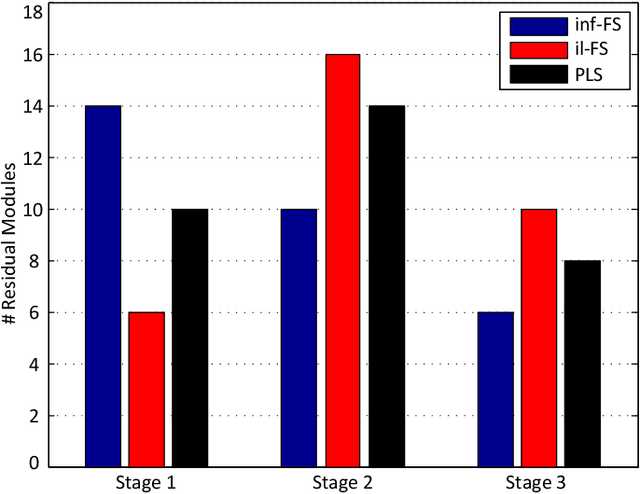
Modern convolutional networks such as ResNet and NASNet have achieved state-of-the-art results in many computer vision applications. These architectures consist of stages, which are sets of layers that operate on representations in the same resolution. It has been demonstrated that increasing the number of layers in each stage improves the prediction ability of the network. However, the resulting architecture becomes computationally expensive in terms of floating point operations, memory requirements and inference time. Thus, significant human effort is necessary to evaluate different trade-offs between depth and performance. To handle this problem, recent works have proposed to automatically design high-performance architectures, mainly by means of neural architecture search (NAS). Current NAS strategies analyze a large set of possible candidate architectures and, hence, require vast computational resources and take many GPUs days. Motivated by this, we propose a NAS approach to efficiently design accurate and low-cost convolutional architectures and demonstrate that an efficient strategy for designing these architectures is to learn the depth stage-by-stage. For this purpose, our approach increases depth incrementally in each stage taking into account its importance, such that stages with low importance are kept shallow while stages with high importance become deeper. We conduct experiments on the CIFAR and different versions of ImageNet datasets, where we show that architectures discovered by our approach achieve better accuracy and efficiency than human-designed architectures. Additionally, we show that architectures discovered on CIFAR-10 can be successfully transferred to large datasets. Compared to previous NAS approaches, our method is substantially more efficient, as it evaluates one order of magnitude fewer models and yields architectures on par with the state-of-the-art.
Covariance-free Partial Least Squares: An Incremental Dimensionality Reduction Method
Oct 05, 2019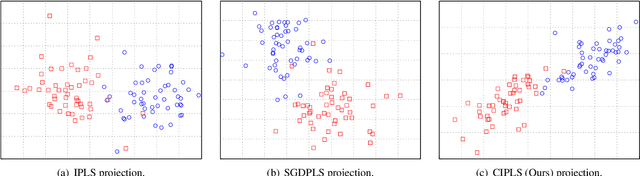
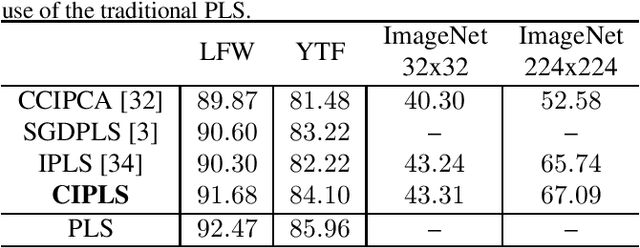
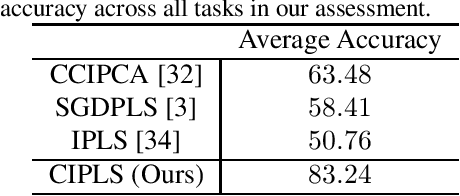
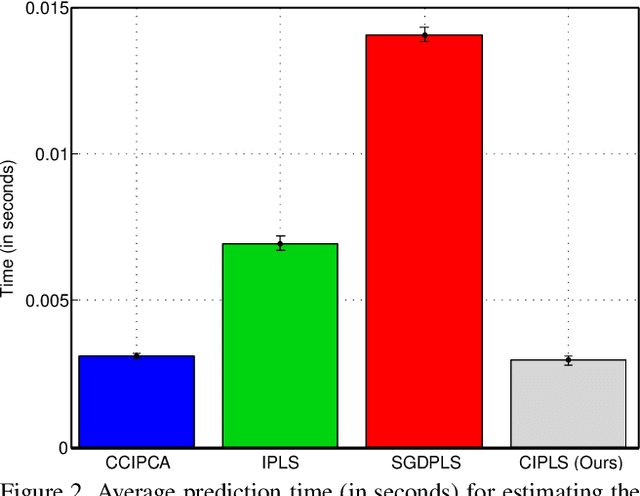
Dimensionality reduction plays an important role in computer vision problems since it reduces computational cost and is often capable of yielding more discriminative data representation. In this context, Partial Least Squares (PLS) has presented notable results in tasks such as image classification and neural network optimization. However, PLS is infeasible on large datasets (e.g., ImageNet) because it requires all the data to be in memory in advance, which is often impractical due to hardware limitations. Additionally, this requirement prevents us from employing PLS on streaming applications where the data are being continuously generated. Motivated by this, we propose a novel incremental PLS, named Covariance-free Incremental Partial Least Squares (CIPLS), which learns a low-dimensional representation of the data using a single sample at a time. In contrast to other state-of-the-art approaches, instead of adopting a partially-discriminative or SGD-based model, we extend Nonlinear Iterative Partial Least Squares (NIPALS) - the standard algorithm used to compute PLS - for incremental processing. Among the advantages of this approach are the preservation of discriminative information across all components, the possibility of employing its score matrices for feature selection, and its computational efficiency. We validate CIPLS on face verification and image classification tasks, where it outperforms several other incremental dimensionality reduction methods. In the context of feature selection, CIPLS achieves comparable results when compared to state-of-the-art techniques.