 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Wise Neural Architecture Search
Apr 23, 2020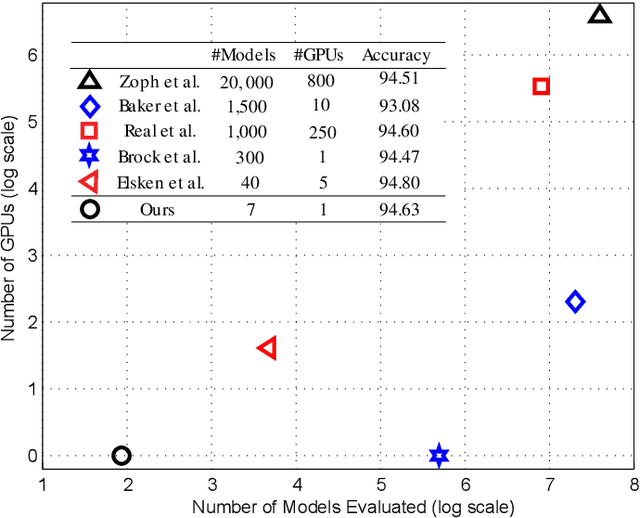
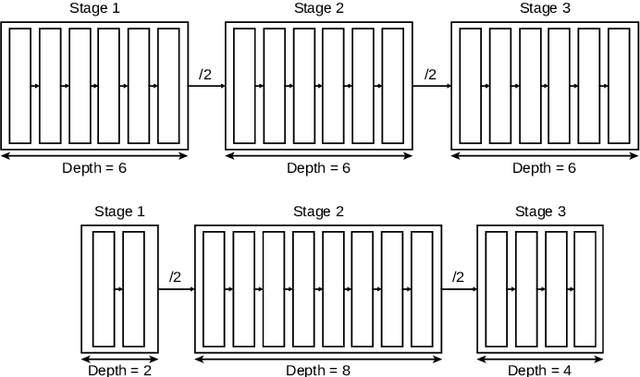
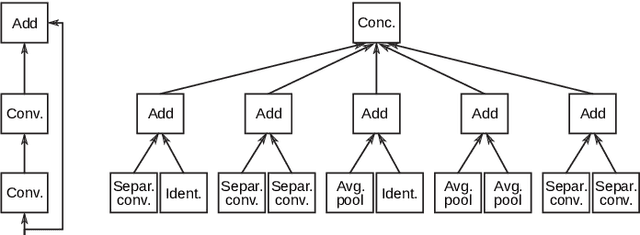
Modern convolutional networks such as ResNet and NASNet have achieved state-of-the-art results in many computer vision applications. These architectures consist of stages, which are sets of layers that operate on representations in the same resolution. It has been demonstrated that increasing the number of layers in each stage improves the prediction ability of the network. However, the resulting architecture becomes computationally expensive in terms of floating point operations, memory requirements and inference time. Thus, significant human effort is necessary to evaluate different trade-offs between depth and performance. To handle this problem, recent works have proposed to automatically design high-performance architectures, mainly by means of neural architecture search (NAS). Current NAS strategies analyze a large set of possible candidate architectures and, hence, require vast computational resources and take many GPUs days. Motivated by this, we propose a NAS approach to efficiently design accurate and low-cost convolutional architectures and demonstrate that an efficient strategy for designing these architectures is to learn the depth stage-by-stage. For this purpose, our approach increases depth incrementally in each stage taking into account its importance, such that stages with low importance are kept shallow while stages with high importance become deeper. We conduct experiments on the CIFAR and different versions of ImageNet datasets, where we show that architectures discovered by our approach achieve better accuracy and efficiency than human-designed architectures. Additionally, we show that architectures discovered on CIFAR-10 can be successfully transferred to large datasets. Compared to previous NAS approaches, our method is substantially more efficient, as it evaluates one order of magnitude fewer models and yields architectures on par with the state-of-the-art.
Covariance-free Partial Least Squares: An Incremental Dimensionality Reduction Method
Oct 05, 2019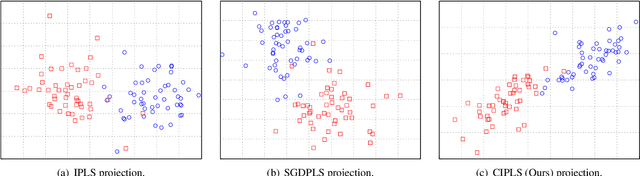
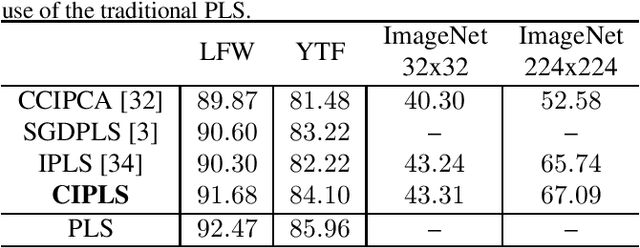
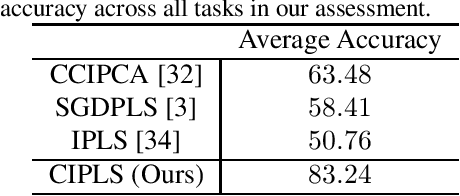
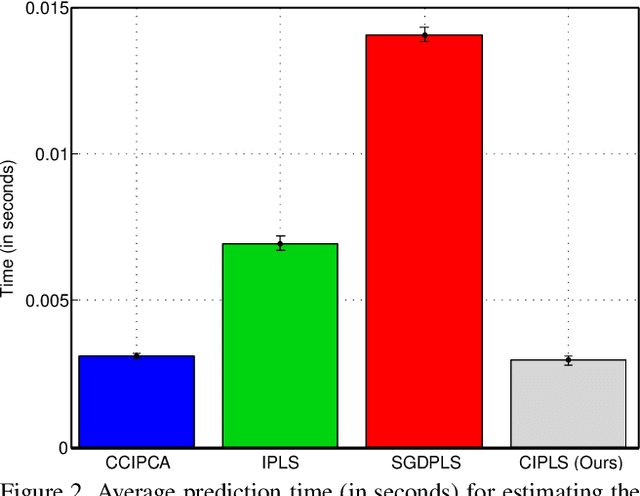
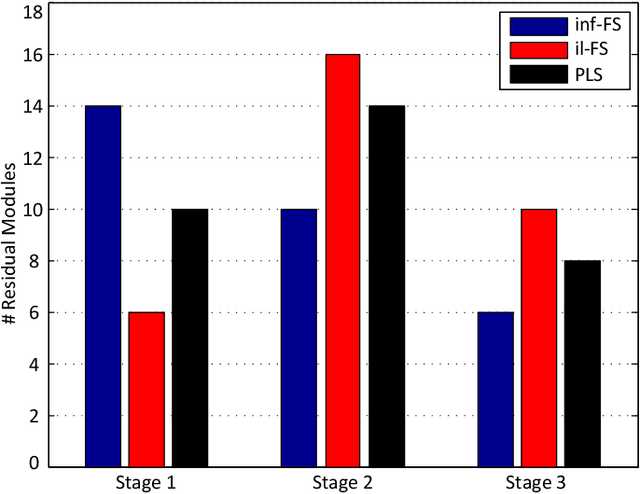
Dimensionality reduction plays an important role in computer vision problems since it reduces computational cost and is often capable of yielding more discriminative data representation. In this context, Partial Least Squares (PLS) has presented notable results in tasks such as image classification and neural network optimization. However, PLS is infeasible on large datasets (e.g., ImageNet) because it requires all the data to be in memory in advance, which is often impractical due to hardware limitations. Additionally, this requirement prevents us from employing PLS on streaming applications where the data are being continuously generated. Motivated by this, we propose a novel incremental PLS, named Covariance-free Incremental Partial Least Squares (CIPLS), which learns a low-dimensional representation of the data using a single sample at a time. In contrast to other state-of-the-art approaches, instead of adopting a partially-discriminative or SGD-based model, we extend Nonlinear Iterative Partial Least Squares (NIPALS) - the standard algorithm used to compute PLS - for incremental processing. Among the advantages of this approach are the preservation of discriminative information across all components, the possibility of employing its score matrices for feature selection, and its computational efficiency. We validate CIPLS on face verification and image classification tasks, where it outperforms several other incremental dimensionality reduction methods. In the context of feature selection, CIPLS achieves comparable results when compared to state-of-the-art techniques.