 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Wise Neural Architecture Search
Paper and Code
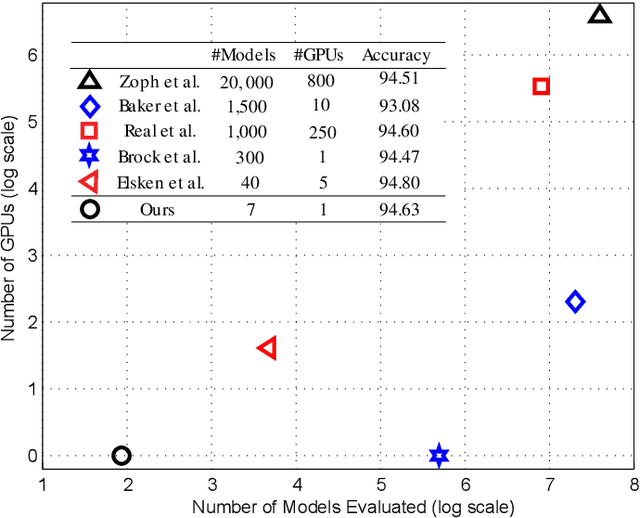
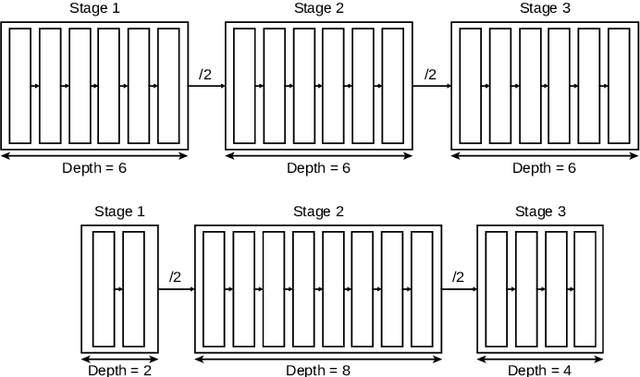
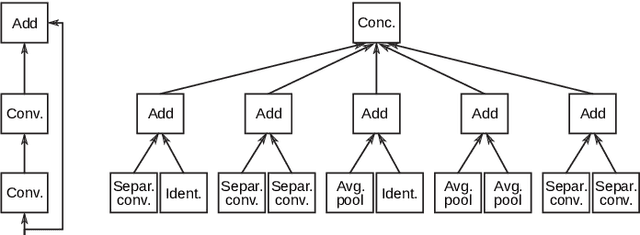
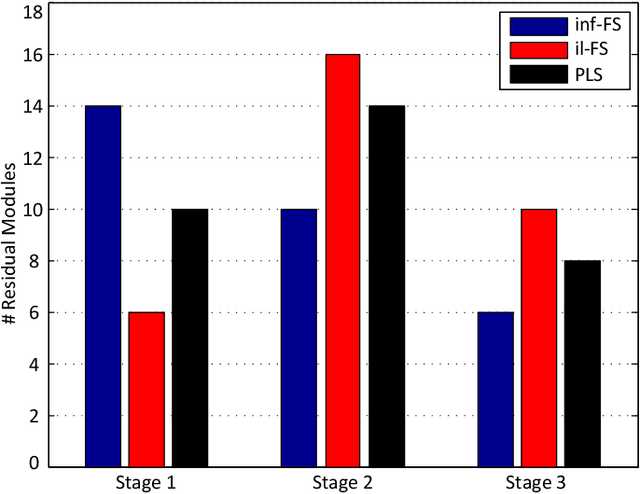
Modern convolutional networks such as ResNet and NASNet have achieved state-of-the-art results in many computer vision applications. These architectures consist of stages, which are sets of layers that operate on representations in the same resolution. It has been demonstrated that increasing the number of layers in each stage improves the prediction ability of the network. However, the resulting architecture becomes computationally expensive in terms of floating point operations, memory requirements and inference time. Thus, significant human effort is necessary to evaluate different trade-offs between depth and performance. To handle this problem, recent works have proposed to automatically design high-performance architectures, mainly by means of neural architecture search (NAS). Current NAS strategies analyze a large set of possible candidate architectures and, hence, require vast computational resources and take many GPUs days. Motivated by this, we propose a NAS approach to efficiently design accurate and low-cost convolutional architectures and demonstrate that an efficient strategy for designing these architectures is to learn the depth stage-by-stage. For this purpose, our approach increases depth incrementally in each stage taking into account its importance, such that stages with low importance are kept shallow while stages with high importance become deeper. We conduct experiments on the CIFAR and different versions of ImageNet datasets, where we show that architectures discovered by our approach achieve better accuracy and efficiency than human-designed architectures. Additionally, we show that architectures discovered on CIFAR-10 can be successfully transferred to large datasets. Compared to previous NAS approaches, our method is substantially more efficient, as it evaluates one order of magnitude fewer models and yields architectures on par with the state-of-the-art.