 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Pruning with Consensus: A Triple-Win Solution
Nov 21, 2024Layer pruning offers a promising alternative to standard structured pruning, effectively reducing computational costs, latency, and memory footprint. While notable layer-pruning approaches aim to detect unimportant layers for removal, they often rely on single criteria that may not fully capture the complex, underlying properties of layers. We propose a novel approach that combines multiple similarity metrics into a single expressive measure of low-importance layers, called the Consensus criterion. Our technique delivers a triple-win solution: low accuracy drop, high-performance improvement, and increased robustness to adversarial attacks. With up to 78.80% FLOPs reduction and performance on par with state-of-the-art methods across different benchmarks, our approach reduces energy consumption and carbon emissions by up to 66.99% and 68.75%, respectively. Additionally, it avoids shortcut learning and improves robustness by up to 4 percentage points under various adversarial attacks. Overall, the Consensus criterion demonstrates its effectiveness in creating robust, efficient, and environmentally friendly pruned models.
Effective Layer Pruning Through Similarity Metric Perspective
May 27, 2024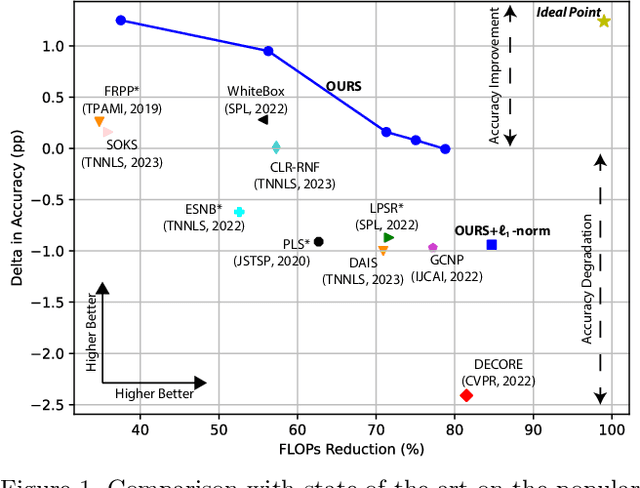
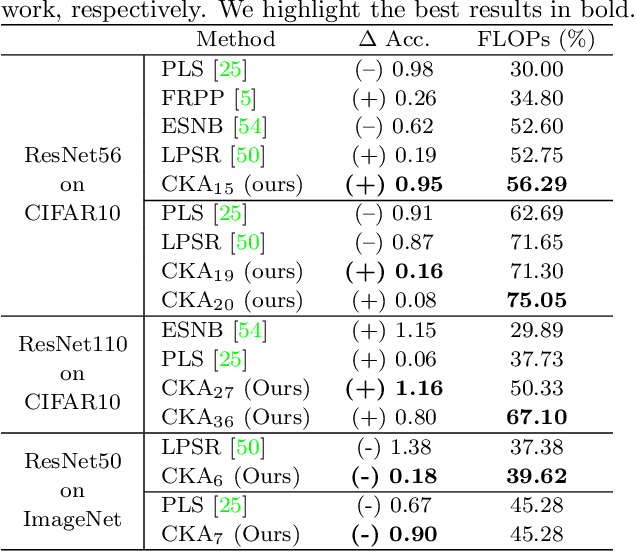
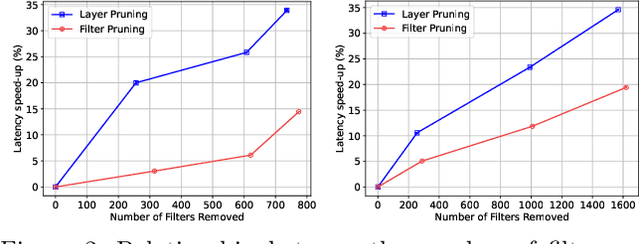
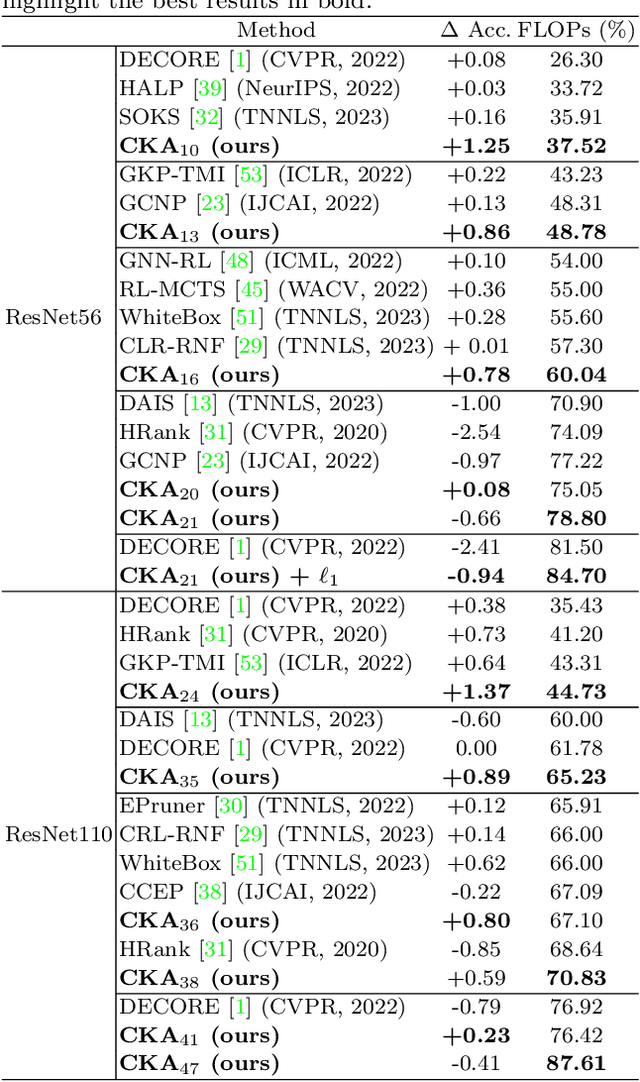
Deep neural networks have been the predominant paradigm in machine learning for solving cognitive tasks. Such models, however, are restricted by a high computational overhead, limiting their applicability and hindering advancements in the field. Extensive research demonstrated that pruning structures from these models is a straightforward approach to reducing network complexity. In this direction, most efforts focus on removing weights or filters. Studies have also been devoted to layer pruning as it promotes superior computational gains. However, layer pruning often hurts the network predictive ability (i.e., accuracy) at high compression rates. This work introduces an effective layer-pruning strategy that meets all underlying properties pursued by pruning methods. Our method estimates the relative importance of a layer using the Centered Kernel Alignment (CKA) metric, employed to measure the similarity between the representations of the unpruned model and a candidate layer for pruning. We confirm the effectiveness of our method on standard architectures and benchmarks, in which it outperforms existing layer-pruning strategies and other state-of-the-art pruning techniques. Particularly, we remove more than 75% of computation while improving predictive ability. At higher compression regimes, our method exhibits negligible accuracy drop, while other methods notably deteriorate model accuracy. Apart from these benefits, our pruned models exhibit robustness to adversarial and out-of-distribution samples.