 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing LLMs with MoP: Mixture of Pruners
Feb 05, 2026The high computational demands of Large Language Models (LLMs) motivate methods that reduce parameter count and accelerate inference. In response, model pruning emerges as an effective strategy, yet current methods typically focus on a single dimension-depth or width. We introduce MoP (Mixture of Pruners), an iterative framework that unifies these dimensions. At each iteration, MoP generates two branches-pruning in depth versus pruning in width-and selects a candidate to advance the path. On LLaMA-2 and LLaMA-3, MoP advances the frontier of structured pruning, exceeding the accuracy of competing methods across a broad set of compression regimes. It also consistently outperforms depth-only and width-only pruning. Furthermore, MoP translates structural pruning into real speedup, reducing end-to-end latency by 39% at 40% compression. Finally, extending MoP to the vision-language model LLaVA-1.5, we notably improve computational efficiency and demonstrate that text-only recovery fine-tuning can restore performance even on visual tasks.
Layer-wise LoRA fine-tuning: a similarity metric approach
Feb 05, 2026Pre-training Large Language Models (LLMs) on web-scale datasets becomes fundamental for advancing general-purpose AI. In contrast, enhancing their predictive performance on downstream tasks typically involves adapting their knowledge through fine-tuning. Parameter-efficient fine-tuning techniques, such as Low-Rank Adaptation (LoRA), aim to reduce the computational cost of this process by freezing the pre-trained model and updating a smaller number of parameters. In comparison to full fine-tuning, these methods achieve over 99\% reduction in trainable parameter count, depending on the configuration. Unfortunately, such a reduction may prove insufficient as LLMs continue to grow in scale. In this work, we address the previous problem by systematically selecting only a few layers to fine-tune using LoRA or its variants. We argue that not all layers contribute equally to the model adaptation. Leveraging this, we identify the most relevant layers to fine-tune by measuring their contribution to changes in internal representations. Our method is orthogonal to and readily compatible with existing low-rank adaptation techniques. We reduce the trainable parameters in LoRA-based techniques by up to 50\%, while maintaining the predictive performance across different models and tasks. Specifically, on encoder-only architectures, this reduction in trainable parameters leads to a negligible predictive performance drop on the GLUE benchmark. On decoder-only architectures, we achieve a small drop or even improvements in the predictive performance on mathematical problem-solving capabilities and coding tasks. Finally, this effectiveness extends to multimodal models, for which we also observe competitive results relative to fine-tuning with LoRA modules in all layers. Code is available at: https://github.com/c2d-usp/Layer-wise-LoRA-with-CKA
Comparing Normalization Methods for Portfolio Optimization with Reinforcement Learning
Aug 05, 2025Recently, reinforcement learning has achieved remarkable results in various domains, including robotics, games, natural language processing, and finance. In the financial domain, this approach has been applied to tasks such as portfolio optimization, where an agent continuously adjusts the allocation of assets within a financial portfolio to maximize profit. Numerous studies have introduced new simulation environments, neural network architectures, and training algorithms for this purpose. Among these, a domain-specific policy gradient algorithm has gained significant attention in the research community for being lightweight, fast, and for outperforming other approaches. However, recent studies have shown that this algorithm can yield inconsistent results and underperform, especially when the portfolio does not consist of cryptocurrencies. One possible explanation for this issue is that the commonly used state normalization method may cause the agent to lose critical information about the true value of the assets being traded. This paper explores this hypothesis by evaluating two of the most widely used normalization methods across three different markets (IBOVESPA, NYSE, and cryptocurrencies) and comparing them with the standard practice of normalizing data before training. The results indicate that, in this specific domain, the state normalization can indeed degrade the agent's performance.
Pruning Everything, Everywhere, All at Once
Jun 04, 2025Deep learning stands as the modern paradigm for solving cognitive tasks. However, as the problem complexity increases, models grow deeper and computationally prohibitive, hindering advancements in real-world and resource-constrained applications. Extensive studies reveal that pruning structures in these models efficiently reduces model complexity and improves computational efficiency. Successful strategies in this sphere include removing neurons (i.e., filters, heads) or layers, but not both together. Therefore, simultaneously pruning different structures remains an open problem. To fill this gap and leverage the benefits of eliminating neurons and layers at once, we propose a new method capable of pruning different structures within a model as follows. Given two candidate subnetworks (pruned models), one from layer pruning and the other from neuron pruning, our method decides which to choose by selecting the one with the highest representation similarity to its parent (the network that generates the subnetworks) using the Centered Kernel Alignment metric. Iteratively repeating this process provides highly sparse models that preserve the original predictive ability. Throughout extensive experiments on standard architectures and benchmarks, we confirm the effectiveness of our approach and show that it outperforms state-of-the-art layer and filter pruning techniques. At high levels of Floating Point Operations reduction, most state-of-the-art methods degrade accuracy, whereas our approach either improves it or experiences only a minimal drop. Notably, on the popular ResNet56 and ResNet110, we achieve a milestone of 86.37% and 95.82% FLOPs reduction. Besides, our pruned models obtain robustness to adversarial and out-of-distribution samples and take an important step towards GreenAI, reducing carbon emissions by up to 83.31%. Overall, we believe our work opens a new chapter in pruning.
Improving Fairness in LLMs Through Testing-Time Adversaries
May 17, 2025



Large Language Models (LLMs) push the bound-aries in natural language processing and generative AI, driving progress across various aspects of modern society. Unfortunately, the pervasive issue of bias in LLMs responses (i.e., predictions) poses a significant and open challenge, hindering their application in tasks involving ethical sensitivity and responsible decision-making. In this work, we propose a straightforward, user-friendly and practical method to mitigate such biases, enhancing the reliability and trustworthiness of LLMs. Our method creates multiple variations of a given sentence by modifying specific attributes and evaluates the corresponding prediction behavior compared to the original, unaltered, prediction/sentence. The idea behind this process is that critical ethical predictions often exhibit notable inconsistencies, indicating the presence of bias. Unlike previous approaches, our method relies solely on forward passes (i.e., testing-time adversaries), eliminating the need for training, fine-tuning, or prior knowledge of the training data distribution. Through extensive experiments on the popular Llama family, we demonstrate the effectiveness of our method in improving various fairness metrics, focusing on the reduction of disparities in how the model treats individuals from different racial groups. Specifically, using standard metrics, we improve the fairness in Llama3 in up to 27 percentage points. Overall, our approach significantly enhances fairness, equity, and reliability in LLM-generated results without parameter tuning or training data modifications, confirming its effectiveness in practical scenarios. We believe our work establishes an important step toward enabling the use of LLMs in tasks that require ethical considerations and responsible decision-making.
Efficient LLMs with AMP: Attention Heads and MLP Pruning
Apr 29, 2025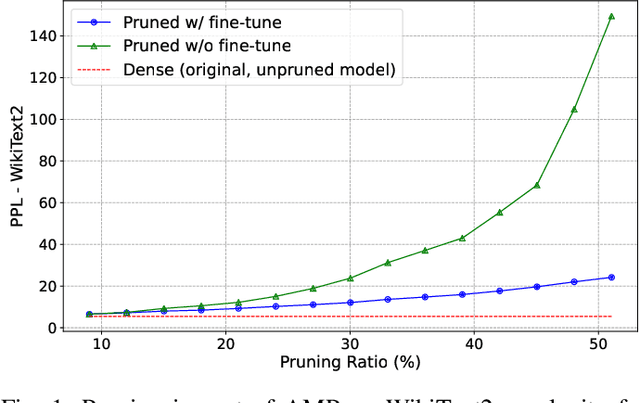
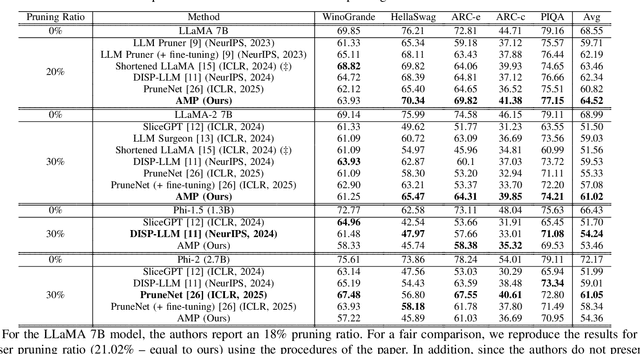
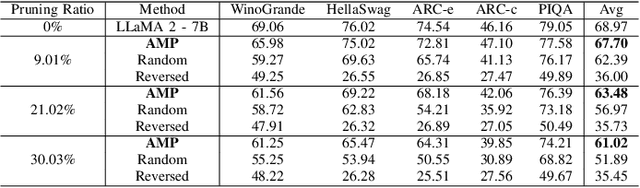

Deep learning drives a new wave in computing systems and triggers the automation of increasingly complex problems. In particular, Large Language Models (LLMs) have significantly advanced cognitive tasks, often matching or even surpassing human-level performance. However, their extensive parameters result in high computational costs and slow inference, posing challenges for deployment in resource-limited settings. Among the strategies to overcome the aforementioned challenges, pruning emerges as a successful mechanism since it reduces model size while maintaining predictive ability. In this paper, we introduce AMP: Attention Heads and MLP Pruning, a novel structured pruning method that efficiently compresses LLMs by removing less critical structures within Multi-Head Attention (MHA) and Multilayer Perceptron (MLP). By projecting the input data onto weights, AMP assesses structural importance and overcomes the limitations of existing techniques, which often fall short in flexibility or efficiency. In particular, AMP surpasses the current state-of-the-art on commonsense reasoning tasks by up to 1.49 percentage points, achieving a 30% pruning ratio with minimal impact on zero-shot task performance. Moreover, AMP also improves inference speeds, making it well-suited for deployment in resource-constrained environments. We confirm the flexibility of AMP on different families of LLMs, including LLaMA and Phi.
No Argument Left Behind: Overlapping Chunks for Faster Processing of Arbitrarily Long Legal Texts
Oct 24, 2024



In a context where the Brazilian judiciary system, the largest in the world, faces a crisis due to the slow processing of millions of cases, it becomes imperative to develop efficient methods for analyzing legal texts. We introduce uBERT, a hybrid model that combines Transformer and Recurrent Neural Network architectures to effectively handle long legal texts. Our approach processes the full text regardless of its length while maintaining reasonable computational overhead. Our experiments demonstrate that uBERT achieves superior performance compared to BERT+LSTM when overlapping input is used and is significantly faster than ULMFiT for processing long legal documents.
From Random to Informed Data Selection: A Diversity-Based Approach to Optimize Human Annotation and Few-Shot Learning
Jan 24, 2024A major challenge in Natural Language Processing is obtaining annotated data for supervised learning. An option is the use of crowdsourcing platforms for data annotation. However, crowdsourcing introduces issues related to the annotator's experience, consistency, and biases. An alternative is to use zero-shot methods, which in turn have limitations compared to their few-shot or fully supervised counterparts. Recent advancements driven by large language models show potential, but struggle to adapt to specialized domains with severely limited data. The most common approaches therefore involve the human itself randomly annotating a set of datapoints to build initial datasets. But randomly sampling data to be annotated is often inefficient as it ignores the characteristics of the data and the specific needs of the model. The situation worsens when working with imbalanced datasets, as random sampling tends to heavily bias towards the majority classes, leading to excessive annotated data. To address these issues, this paper contributes an automatic and informed data selection architecture to build a small dataset for few-shot learning. Our proposal minimizes the quantity and maximizes diversity of data selected for human annotation, while improving model performance.
Augmenting a Physics-Informed Neural Network for the 2D Burgers Equation by Addition of Solution Data Points
Jan 18, 2023We implement a Physics-Informed Neural Network (PINN) for solving the two-dimensional Burgers equations. This type of model can be trained with no previous knowledge of the solution; instead, it relies on evaluating the governing equations of the system in points of the physical domain. It is also possible to use points with a known solution during training. In this paper, we compare PINNs trained with different amounts of governing equation evaluation points and known solution points. Comparing models that were trained purely with known solution points to those that have also used the governing equations, we observe an improvement in the overall observance of the underlying physics in the latter. We also investigate how changing the number of each type of point affects the resulting models differently. Finally, we argue that the addition of the governing equations during training may provide a way to improve the overall performance of the model without relying on additional data, which is especially important for situations where the number of known solution points is limited.
* This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this contribution is published in the Lecture Notes in Computer Science book series (LNAI,volume 13654), and is available online at https://doi.org/10.1007/978-3-031-21689-3_28
Tracking environmental policy changes in the Brazilian Federal Official Gazette
Feb 11, 2022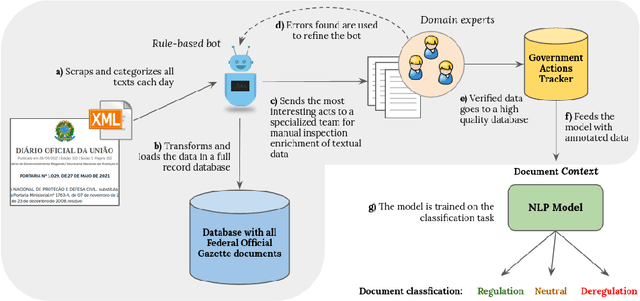
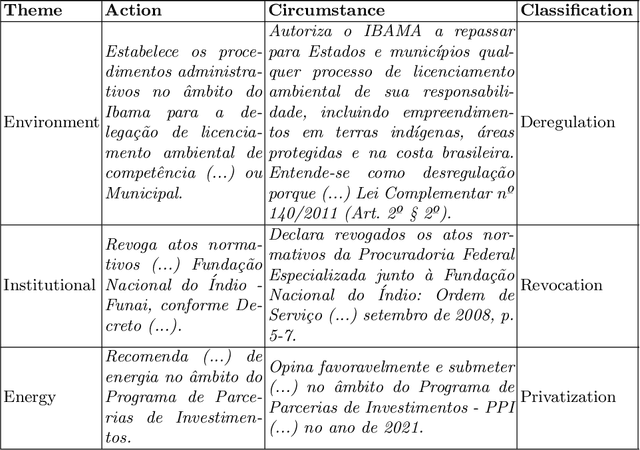
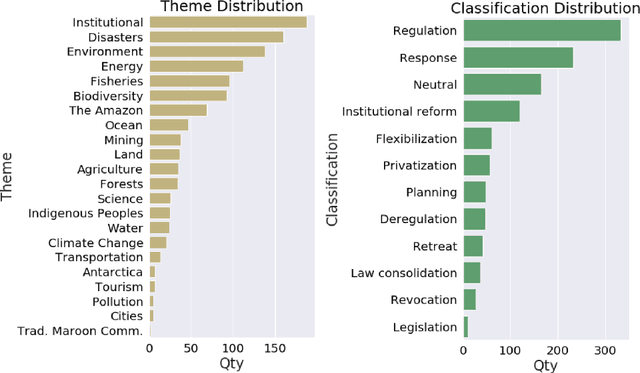
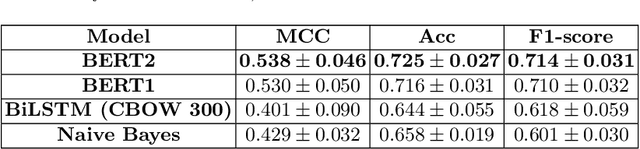
Even though most of its energy generation comes from renewable sources, Brazil is one of the largest emitters of greenhouse gases in the world, due to intense farming and deforestation of biomes such as the Amazon Rainforest, whose preservation is essential for compliance with the Paris Agreement. Still, regardless of lobbies or prevailing political orientation, all government legal actions are published daily in the Brazilian Federal Official Gazette (BFOG, or "Di\'ario Oficial da Uni\~ao" in Portuguese). However, with hundreds of decrees issued every day by the authorities, it is absolutely burdensome to manually analyze all these processes and find out which ones can pose serious environmental hazards. In this paper, we present a strategy to compose automated techniques and domain expert knowledge to process all the data from the BFOG. We also provide the Government Actions Tracker, a highly curated dataset, in Portuguese, annotated by domain experts, on federal government acts about the Brazilian environmental policies. Finally, we build and compared four different NLP models on the classfication task in this dataset. Our best model achieved a F1-score of $0.714 \pm 0.031$. In the future, this system should serve to scale up the high-quality tracking of all oficial documents with a minimum of human supervision and contribute to increasing society's awareness of government actions.