 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Argument Left Behind: Overlapping Chunks for Faster Processing of Arbitrarily Long Legal Texts
Oct 24, 2024



In a context where the Brazilian judiciary system, the largest in the world, faces a crisis due to the slow processing of millions of cases, it becomes imperative to develop efficient methods for analyzing legal texts. We introduce uBERT, a hybrid model that combines Transformer and Recurrent Neural Network architectures to effectively handle long legal texts. Our approach processes the full text regardless of its length while maintaining reasonable computational overhead. Our experiments demonstrate that uBERT achieves superior performance compared to BERT+LSTM when overlapping input is used and is significantly faster than ULMFiT for processing long legal documents.
From Random to Informed Data Selection: A Diversity-Based Approach to Optimize Human Annotation and Few-Shot Learning
Jan 24, 2024A major challenge in Natural Language Processing is obtaining annotated data for supervised learning. An option is the use of crowdsourcing platforms for data annotation. However, crowdsourcing introduces issues related to the annotator's experience, consistency, and biases. An alternative is to use zero-shot methods, which in turn have limitations compared to their few-shot or fully supervised counterparts. Recent advancements driven by large language models show potential, but struggle to adapt to specialized domains with severely limited data. The most common approaches therefore involve the human itself randomly annotating a set of datapoints to build initial datasets. But randomly sampling data to be annotated is often inefficient as it ignores the characteristics of the data and the specific needs of the model. The situation worsens when working with imbalanced datasets, as random sampling tends to heavily bias towards the majority classes, leading to excessive annotated data. To address these issues, this paper contributes an automatic and informed data selection architecture to build a small dataset for few-shot learning. Our proposal minimizes the quantity and maximizes diversity of data selected for human annotation, while improving model performance.
ZeroBERTo -- Leveraging Zero-Shot Text Classification by Topic Modeling
Jan 04, 2022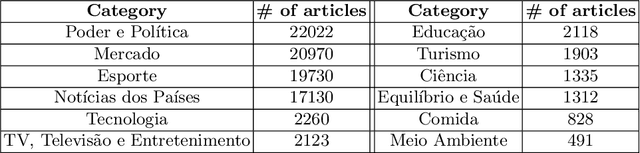
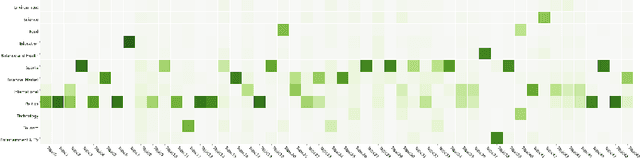

Traditional text classification approaches often require a good amount of labeled data, which is difficult to obtain, especially in restricted domains or less widespread languages. This lack of labeled data has led to the rise of low-resource methods, that assume low data availability in natural language processing. Among them, zero-shot learning stands out, which consists of learning a classifier without any previously labeled data. The best results reported with this approach use language models such as Transformers, but fall into two problems: high execution time and inability to handle long texts as input. This paper proposes a new model, ZeroBERTo, which leverages an unsupervised clustering step to obtain a compressed data representation before the classification task. We show that ZeroBERTo has better performance for long inputs and shorter execution time, outperforming XLM-R by about 12% in the F1 score in the FolhaUOL dataset. Keywords: Low-Resource NLP, Unlabeled data, Zero-Shot Learning, Topic Modeling, Transformers.
DEBACER: a method for slicing moderated debates
Dec 10, 2021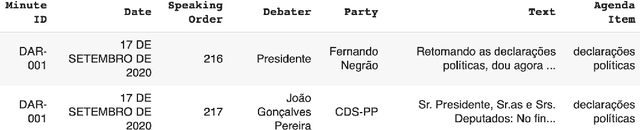
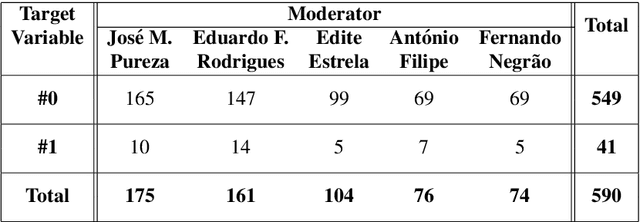
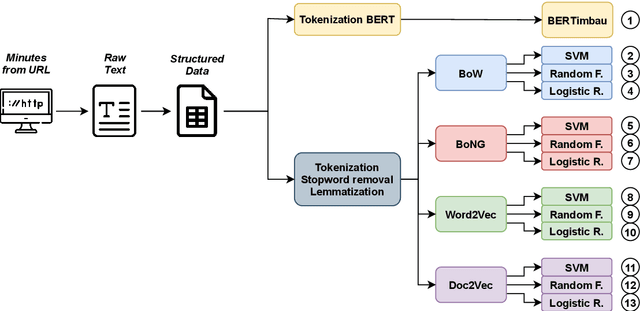
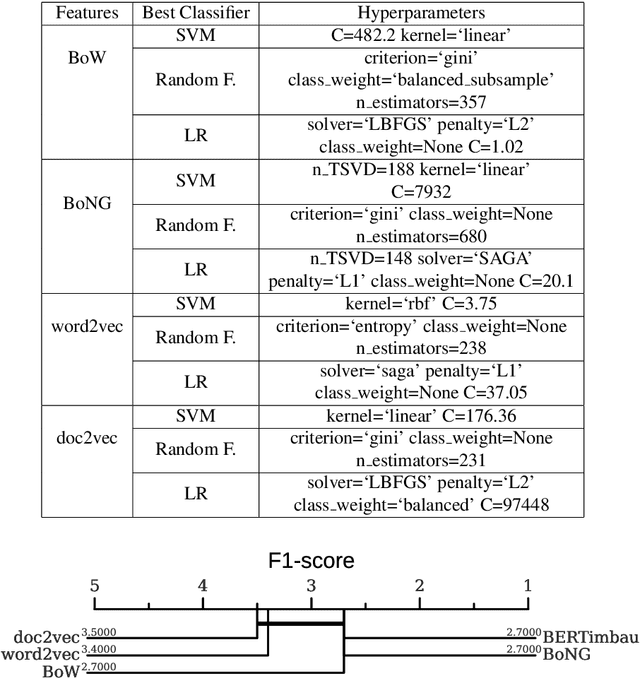
Subjects change frequently in moderated debates with several participants, such as in parliamentary sessions, electoral debates, and trials. Partitioning a debate into blocks with the same subject is essential for understanding. Often a moderator is responsible for defining when a new block begins so that the task of automatically partitioning a moderated debate can focus solely on the moderator's behavior. In this paper, we (i) propose a new algorithm, DEBACER, which partitions moderated debates; (ii) carry out a comparative study between conventional and BERTimbau pipelines; and (iii) validate DEBACER applying it to the minutes of the Assembly of the Republic of Portugal. Our results show the effectiveness of DEBACER. Keywords: Natural Language Processing, Political Documents, Spoken Text Processing, Speech Split, Dialogue Partitioning.
* Accepted on The 18th National Meeting on Artificial and Computational Intelligence (ENIAC 2021)