 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroBERTo -- Leveraging Zero-Shot Text Classification by Topic Modeling
Jan 04, 2022

Traditional text classification approaches often require a good amount of labeled data, which is difficult to obtain, especially in restricted domains or less widespread languages. This lack of labeled data has led to the rise of low-resource methods, that assume low data availability in natural language processing. Among them, zero-shot learning stands out, which consists of learning a classifier without any previously labeled data. The best results reported with this approach use language models such as Transformers, but fall into two problems: high execution time and inability to handle long texts as input. This paper proposes a new model, ZeroBERTo, which leverages an unsupervised clustering step to obtain a compressed data representation before the classification task. We show that ZeroBERTo has better performance for long inputs and shorter execution time, outperforming XLM-R by about 12% in the F1 score in the FolhaUOL dataset. Keywords: Low-Resource NLP, Unlabeled data, Zero-Shot Learning, Topic Modeling, Transformers.
DEBACER: a method for slicing moderated debates
Dec 10, 2021
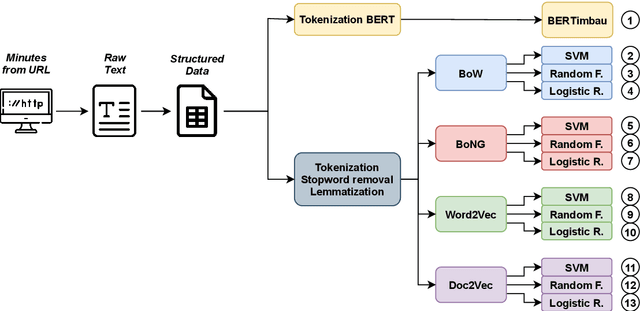
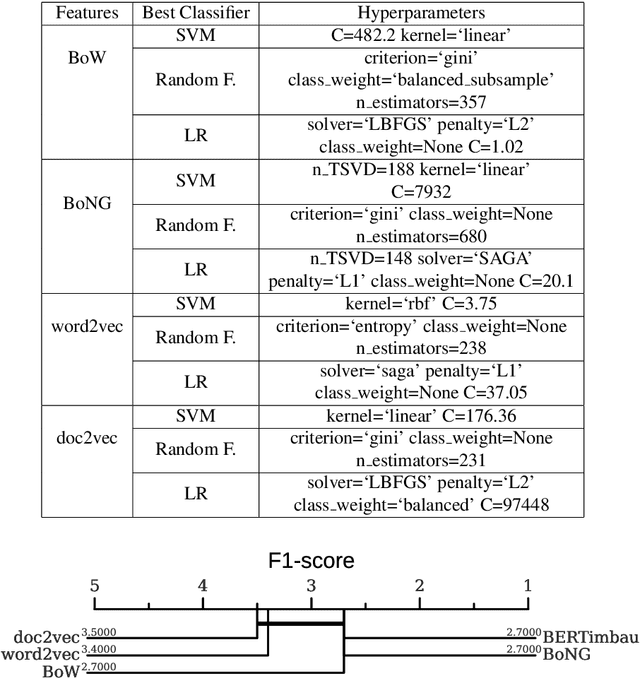
Subjects change frequently in moderated debates with several participants, such as in parliamentary sessions, electoral debates, and trials. Partitioning a debate into blocks with the same subject is essential for understanding. Often a moderator is responsible for defining when a new block begins so that the task of automatically partitioning a moderated debate can focus solely on the moderator's behavior. In this paper, we (i) propose a new algorithm, DEBACER, which partitions moderated debates; (ii) carry out a comparative study between conventional and BERTimbau pipelines; and (iii) validate DEBACER applying it to the minutes of the Assembly of the Republic of Portugal. Our results show the effectiveness of DEBACER. Keywords: Natural Language Processing, Political Documents, Spoken Text Processing, Speech Split, Dialogue Partitioning.
* Accepted on The 18th National Meeting on Artificial and Computational Intelligence (ENIAC 2021)
PLSUM: Generating PT-BR Wikipedia by Summarizing Multiple Websites
Dec 02, 2021



Wikipedia is an important free source of intelligible knowledge. Despite that, Brazilian Portuguese Wikipedia still lacks descriptions for many subjects. In an effort to expand the Brazilian Wikipedia, we contribute PLSum, a framework for generating wiki-like abstractive summaries from multiple descriptive websites. The framework has an extractive stage followed by an abstractive one. In particular, for the abstractive stage, we fine-tune and compare two recent variations of the Transformer neural network, PTT5, and Longformer. To fine-tune and evaluate the model, we created a dataset with thousands of examples, linking reference websites to Wikipedia. Our results show that it is possible to generate meaningful abstractive summaries from Brazilian Portuguese web content.
DEEPAGÉ: Answering Questions in Portuguese about the Brazilian Environment
Oct 19, 2021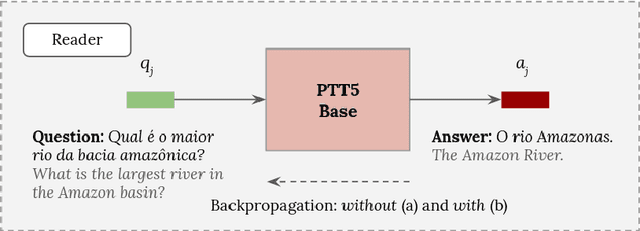
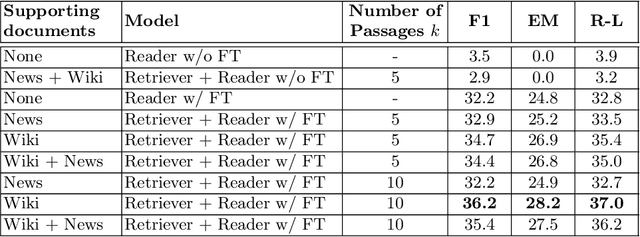
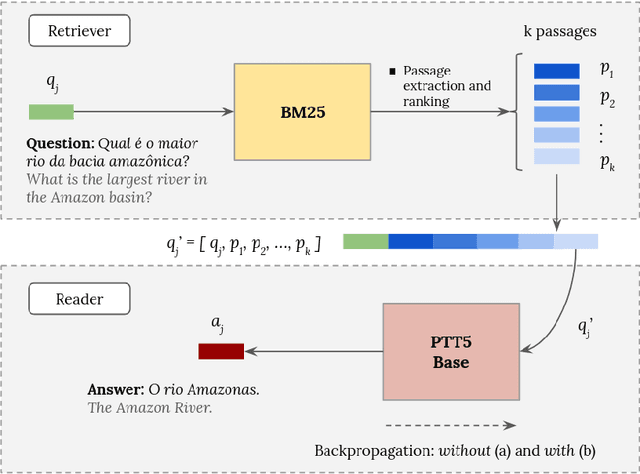
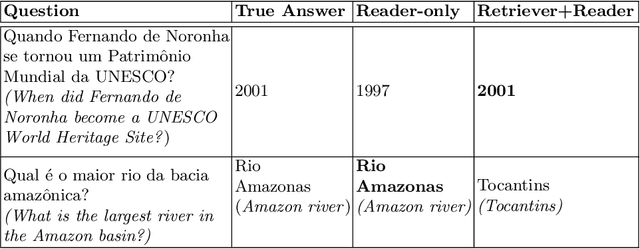
The challenge of climate change and biome conservation is one of the most pressing issues of our time - particularly in Brazil, where key environmental reserves are located. Given the availability of large textual databases on ecological themes, it is natural to resort to question answering (QA) systems to increase social awareness and understanding about these topics. In this work, we introduce multiple QA systems that combine in novel ways the BM25 algorithm, a sparse retrieval technique, with PTT5, a pre-trained state-of-the-art language model. Our QA systems focus on the Portuguese language, thus offering resources not found elsewhere in the literature. As training data, we collected questions from open-domain datasets, as well as content from the Portuguese Wikipedia and news from the press. We thus contribute with innovative architectures and novel applications, attaining an F1-score of 36.2 with our best model.