 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking environmental policy changes in the Brazilian Federal Official Gazette
Feb 11, 2022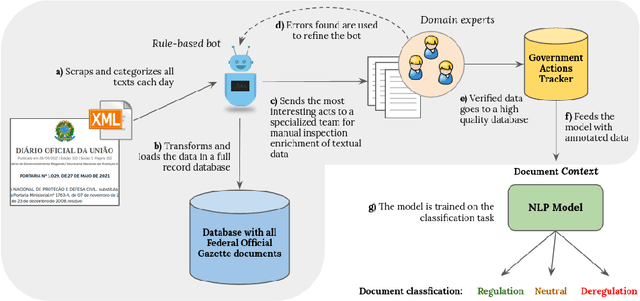
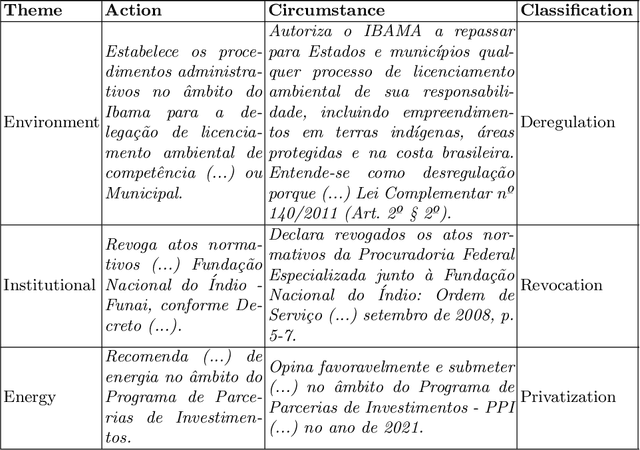
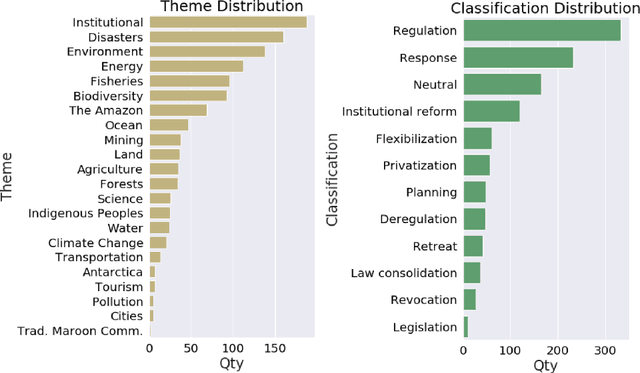
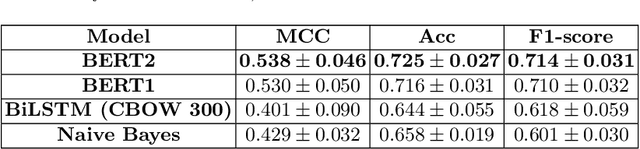
Even though most of its energy generation comes from renewable sources, Brazil is one of the largest emitters of greenhouse gases in the world, due to intense farming and deforestation of biomes such as the Amazon Rainforest, whose preservation is essential for compliance with the Paris Agreement. Still, regardless of lobbies or prevailing political orientation, all government legal actions are published daily in the Brazilian Federal Official Gazette (BFOG, or "Di\'ario Oficial da Uni\~ao" in Portuguese). However, with hundreds of decrees issued every day by the authorities, it is absolutely burdensome to manually analyze all these processes and find out which ones can pose serious environmental hazards. In this paper, we present a strategy to compose automated techniques and domain expert knowledge to process all the data from the BFOG. We also provide the Government Actions Tracker, a highly curated dataset, in Portuguese, annotated by domain experts, on federal government acts about the Brazilian environmental policies. Finally, we build and compared four different NLP models on the classfication task in this dataset. Our best model achieved a F1-score of $0.714 \pm 0.031$. In the future, this system should serve to scale up the high-quality tracking of all oficial documents with a minimum of human supervision and contribute to increasing society's awareness of government actions.
DEEPAGÉ: Answering Questions in Portuguese about the Brazilian Environment
Oct 19, 2021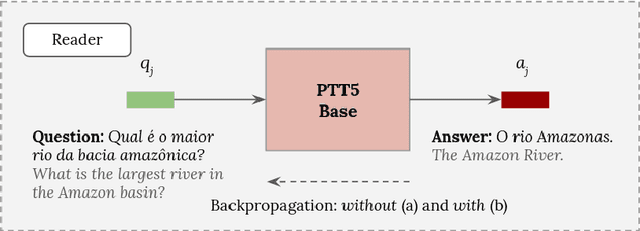
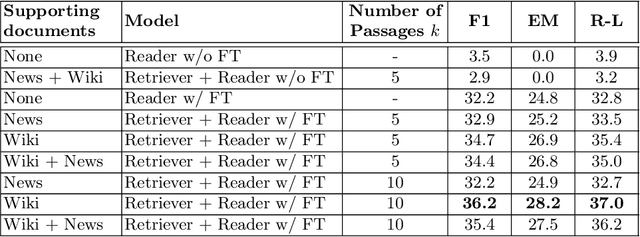
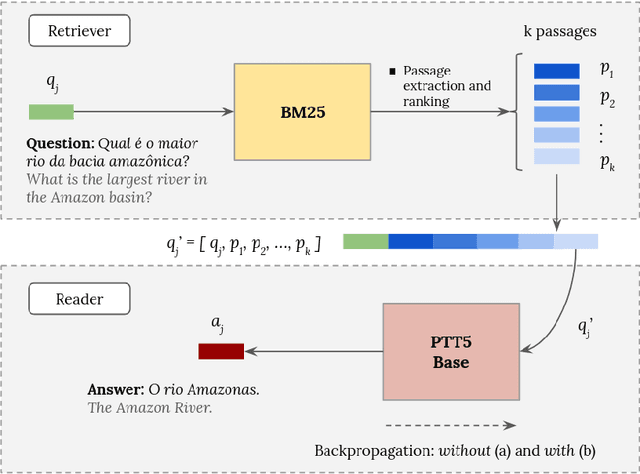
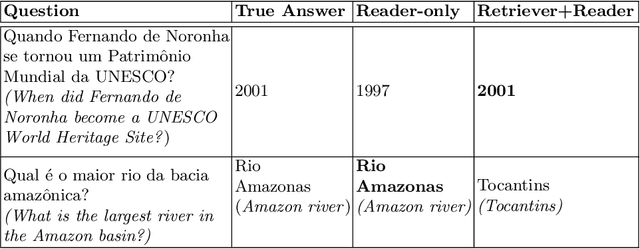
The challenge of climate change and biome conservation is one of the most pressing issues of our time - particularly in Brazil, where key environmental reserves are located. Given the availability of large textual databases on ecological themes, it is natural to resort to question answering (QA) systems to increase social awareness and understanding about these topics. In this work, we introduce multiple QA systems that combine in novel ways the BM25 algorithm, a sparse retrieval technique, with PTT5, a pre-trained state-of-the-art language model. Our QA systems focus on the Portuguese language, thus offering resources not found elsewhere in the literature. As training data, we collected questions from open-domain datasets, as well as content from the Portuguese Wikipedia and news from the press. We thus contribute with innovative architectures and novel applications, attaining an F1-score of 36.2 with our best model.