 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausally-Constrained Probabilistic Forecasting for Time-Series Anomaly Detection
Apr 20, 2026Anomaly detection in multivariate time series is a central challenge in industrial monitoring, as failures frequently arise from complex temporal dynamics and cross-sensor interactions. While recent deep learning models, including graph neural networks and Transformers, have demonstrated strong empirical performance, most approaches remain primarily correlational and offer limited support for causal interpretation and root-cause localization. This study introduces a causally-constrained probabilistic forecasting framework which is a Causally Guided Transformer (CGT) model for multivariate time-series anomaly detection, integrating an explicit time-lagged causal graph prior with deep sequence modeling. For each target variable, a dedicated forecasting block employs a hard parent mask derived from causal discovery to restrict the main prediction pathway to graph-supported causes, while a latent Gaussian head captures predictive uncertainty. To leverage residual correlational information without compromising the causal representation, a shadow auxiliary path with stop-gradient isolation and a safety-gated blending mechanism is incorporated to suppress non-causal contributions when reliability is low. Anomalies are identified using negative log-likelihood scores with adaptive streaming thresholding, and root-cause variables are determined through per-dimension probabilistic attribution and counterfactual clamping. Experiments on the ASD and SMD benchmarks indicate that the proposed method achieves state-of-the-art detection performance, with F1-scores of 96.19% on ASD and 95.32% on SMD, and enhances variable-level attribution quality. These findings suggest that causal structural priors can improve both robustness and interpretability in detecting deep anomalies in multivariate sensor systems.
Interpretable Rules for Online Failure Prediction: A Case Study on the Metro do Porto dataset
Feb 11, 2025Due to their high predictive performance, predictive maintenance applications have increasingly been approached with Deep Learning techniques in recent years. However, as in other real-world application scenarios, the need for explainability is often stated but not sufficiently addressed. This study will focus on predicting failures on Metro trains in Porto, Portugal. While recent works have found high-performing deep neural network architectures that feature a parallel explainability pipeline, the generated explanations are fairly complicated and need help explaining why the failures are happening. This work proposes a simple online rule-based explainability approach with interpretable features that leads to straightforward, interpretable rules. We showcase our approach on MetroPT2 and find that three specific sensors on the Metro do Porto trains suffice to predict the failures present in the dataset with simple rules.
Simulation, Modelling and Classification of Wiki Contributors: Spotting The Good, The Bad, and The Ugly
May 29, 2024
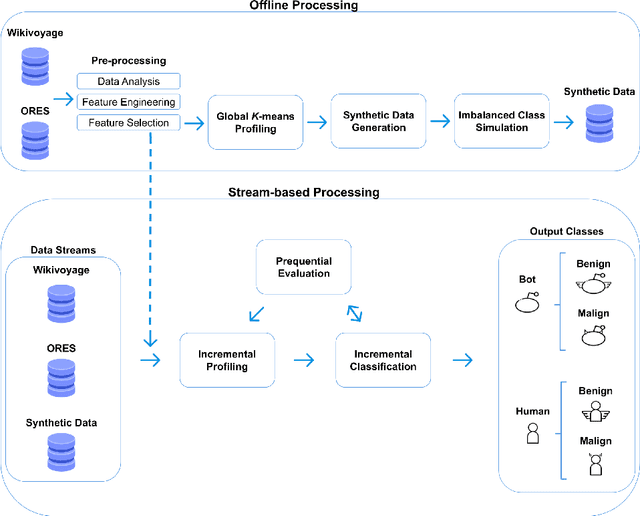


Data crowdsourcing is a data acquisition process where groups of voluntary contributors feed platforms with highly relevant data ranging from news, comments, and media to knowledge and classifications. It typically processes user-generated data streams to provide and refine popular services such as wikis, collaborative maps, e-commerce sites, and social networks. Nevertheless, this modus operandi raises severe concerns regarding ill-intentioned data manipulation in adversarial environments. This paper presents a simulation, modelling, and classification approach to automatically identify human and non-human (bots) as well as benign and malign contributors by using data fabrication to balance classes within experimental data sets, data stream modelling to build and update contributor profiles and, finally, autonomic data stream classification. By employing WikiVoyage - a free worldwide wiki travel guide open to contribution from the general public - as a testbed, our approach proves to significantly boost the confidence and quality of the classifier by using a class-balanced data stream, comprising both real and synthetic data. Our empirical results show that the proposed method distinguishes between benign and malign bots as well as human contributors with a classification accuracy of up to 92 %.
A Neuro-Symbolic Explainer for Rare Events: A Case Study on Predictive Maintenance
Apr 21, 2024



Predictive Maintenance applications are increasingly complex, with interactions between many components. Black box models are popular approaches based on deep learning techniques due to their predictive accuracy. This paper proposes a neural-symbolic architecture that uses an online rule-learning algorithm to explain when the black box model predicts failures. The proposed system solves two problems in parallel: anomaly detection and explanation of the anomaly. For the first problem, we use an unsupervised state of the art autoencoder. For the second problem, we train a rule learning system that learns a mapping from the input features to the autoencoder reconstruction error. Both systems run online and in parallel. The autoencoder signals an alarm for the examples with a reconstruction error that exceeds a threshold. The causes of the signal alarm are hard for humans to understand because they result from a non linear combination of sensor data. The rule that triggers that example describes the relationship between the input features and the autoencoder reconstruction error. The rule explains the failure signal by indicating which sensors contribute to the alarm and allowing the identification of the component involved in the failure. The system can present global explanations for the black box model and local explanations for why the black box model predicts a failure. We evaluate the proposed system in a real-world case study of Metro do Porto and provide explanations that illustrate its benefits.
Super-Resolution Analysis for Landfill Waste Classification
Apr 02, 2024Illegal landfills are a critical issue due to their environmental, economic, and public health impacts. This study leverages aerial imagery for environmental crime monitoring. While advances in artificial intelligence and computer vision hold promise, the challenge lies in training models with high-resolution literature datasets and adapting them to open-access low-resolution images. Considering the substantial quality differences and limited annotation, this research explores the adaptability of models across these domains. Motivated by the necessity for a comprehensive evaluation of waste detection algorithms, it advocates cross-domain classification and super-resolution enhancement to analyze the impact of different image resolutions on waste classification as an evaluation to combat the proliferation of illegal landfills. We observed performance improvements by enhancing image quality but noted an influence on model sensitivity, necessitating careful threshold fine-tuning.
From Random to Informed Data Selection: A Diversity-Based Approach to Optimize Human Annotation and Few-Shot Learning
Jan 24, 2024A major challenge in Natural Language Processing is obtaining annotated data for supervised learning. An option is the use of crowdsourcing platforms for data annotation. However, crowdsourcing introduces issues related to the annotator's experience, consistency, and biases. An alternative is to use zero-shot methods, which in turn have limitations compared to their few-shot or fully supervised counterparts. Recent advancements driven by large language models show potential, but struggle to adapt to specialized domains with severely limited data. The most common approaches therefore involve the human itself randomly annotating a set of datapoints to build initial datasets. But randomly sampling data to be annotated is often inefficient as it ignores the characteristics of the data and the specific needs of the model. The situation worsens when working with imbalanced datasets, as random sampling tends to heavily bias towards the majority classes, leading to excessive annotated data. To address these issues, this paper contributes an automatic and informed data selection architecture to build a small dataset for few-shot learning. Our proposal minimizes the quantity and maximizes diversity of data selected for human annotation, while improving model performance.
Explainable Predictive Maintenance
Jun 08, 2023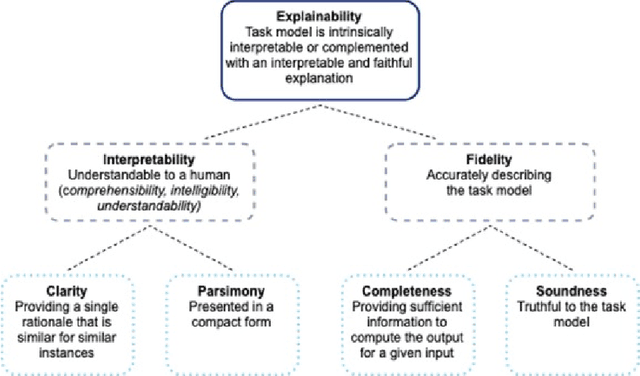

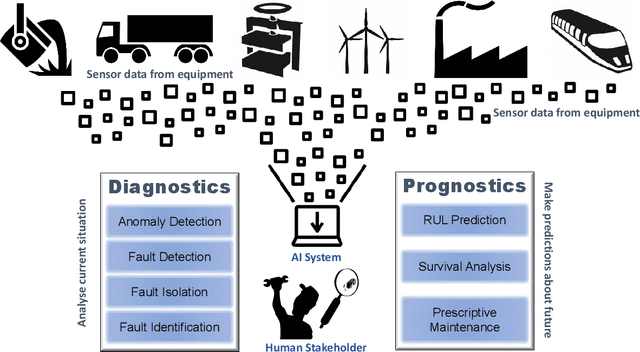
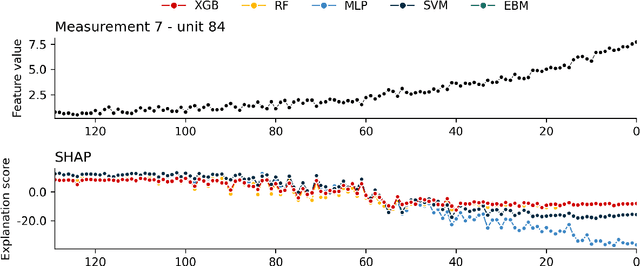
Explainable Artificial Intelligence (XAI) fills the role of a critical interface fostering interactions between sophisticated intelligent systems and diverse individuals, including data scientists, domain experts, end-users, and more. It aids in deciphering the intricate internal mechanisms of ``black box'' Machine Learning (ML), rendering the reasons behind their decisions more understandable. However, current research in XAI primarily focuses on two aspects; ways to facilitate user trust, or to debug and refine the ML model. The majority of it falls short of recognising the diverse types of explanations needed in broader contexts, as different users and varied application areas necessitate solutions tailored to their specific needs. One such domain is Predictive Maintenance (PdM), an exploding area of research under the Industry 4.0 \& 5.0 umbrella. This position paper highlights the gap between existing XAI methodologies and the specific requirements for explanations within industrial applications, particularly the Predictive Maintenance field. Despite explainability's crucial role, this subject remains a relatively under-explored area, making this paper a pioneering attempt to bring relevant challenges to the research community's attention. We provide an overview of predictive maintenance tasks and accentuate the need and varying purposes for corresponding explanations. We then list and describe XAI techniques commonly employed in the literature, discussing their suitability for PdM tasks. Finally, to make the ideas and claims more concrete, we demonstrate XAI applied in four specific industrial use cases: commercial vehicles, metro trains, steel plants, and wind farms, spotlighting areas requiring further research.
Modeling Events and Interactions through Temporal Processes -- A Survey
Mar 10, 2023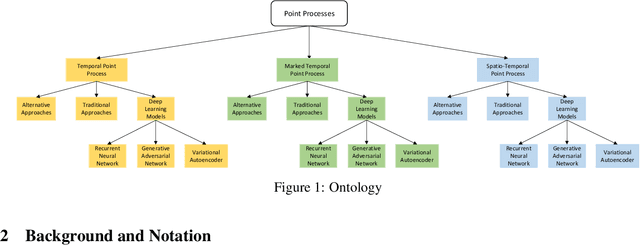
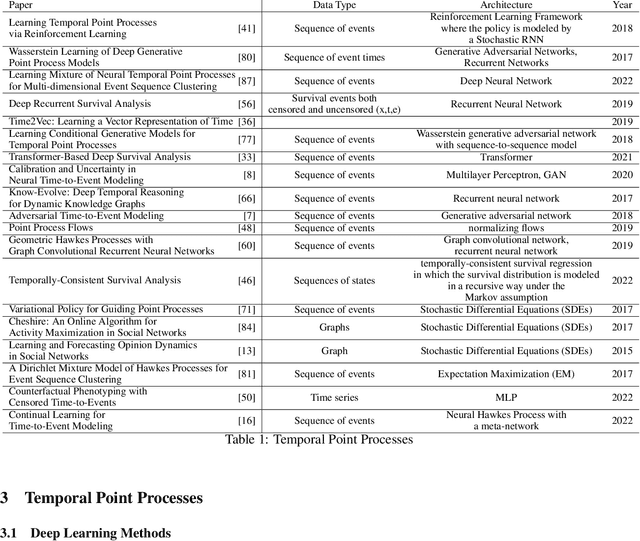
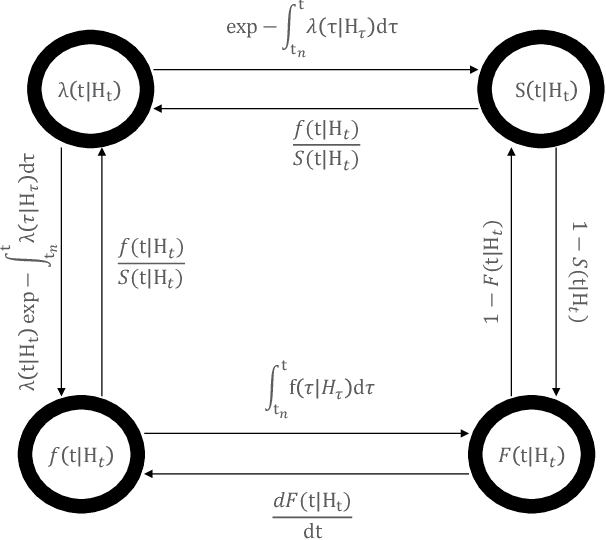
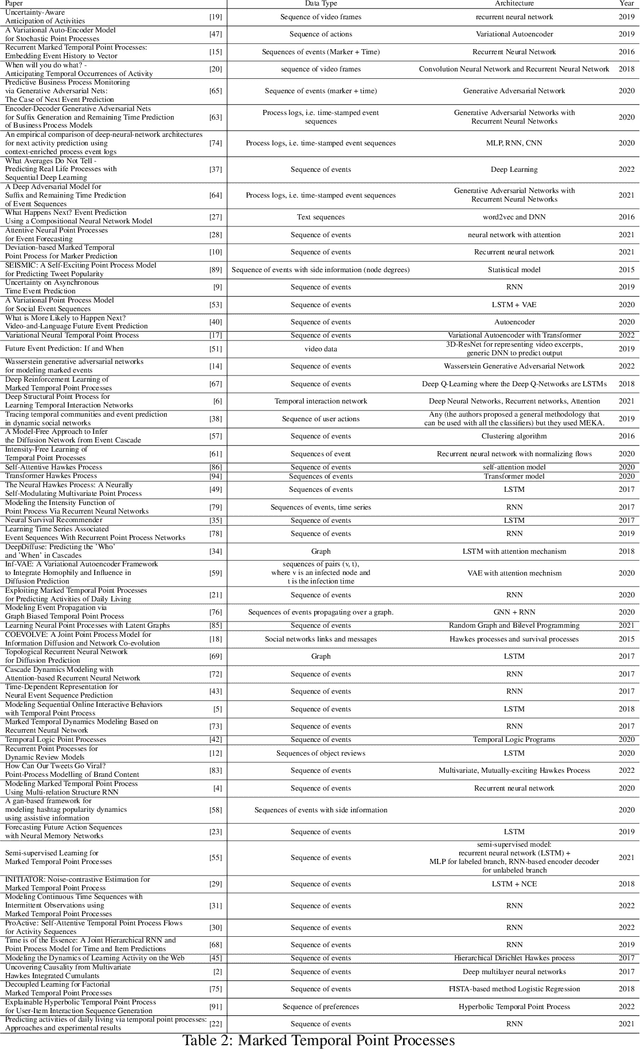
In real-world scenario, many phenomena produce a collection of events that occur in continuous time. Point Processes provide a natural mathematical framework for modeling these sequences of events. In this survey, we investigate probabilistic models for modeling event sequences through temporal processes. We revise the notion of event modeling and provide the mathematical foundations that characterize the literature on the topic. We define an ontology to categorize the existing approaches in terms of three families: simple, marked, and spatio-temporal point processes. For each family, we systematically review the existing approaches based based on deep learning. Finally, we analyze the scenarios where the proposed techniques can be used for addressing prediction and modeling aspects.
A Benchmark dataset for predictive maintenance
Jul 18, 2022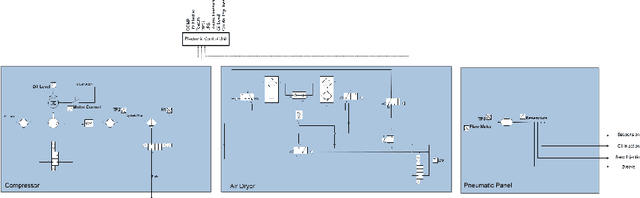
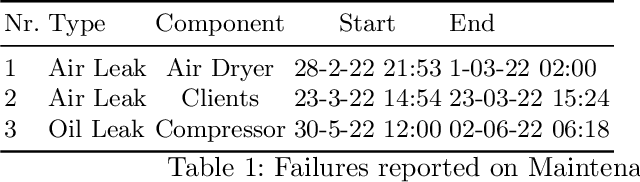
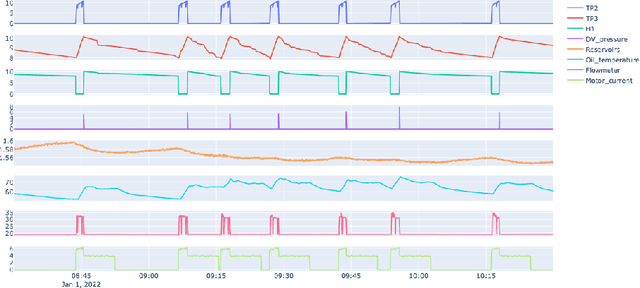
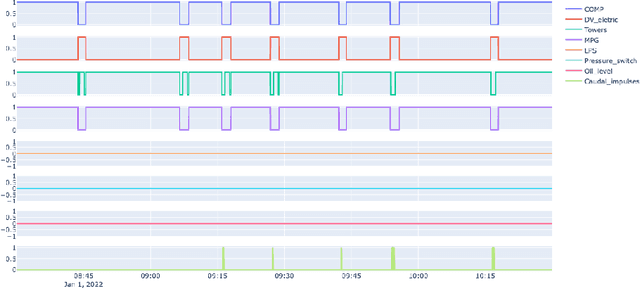
The paper describes the MetroPT data set, an outcome of a eXplainable Predictive Maintenance (XPM) project with an urban metro public transportation service in Porto, Portugal. The data was collected in 2022 that aimed to evaluate machine learning methods for online anomaly detection and failure prediction. By capturing several analogic sensor signals (pressure, temperature, current consumption), digital signals (control signals, discrete signals), and GPS information (latitude, longitude, and speed), we provide a dataset that can be easily used to evaluate online machine learning methods. This dataset contains some interesting characteristics and can be a good benchmark for predictive maintenance models.