 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline detection and infographic explanation of spam reviews with data drift adaptation
Jun 21, 2024Spam reviews are a pervasive problem on online platforms due to its significant impact on reputation. However, research into spam detection in data streams is scarce. Another concern lies in their need for transparency. Consequently, this paper addresses those problems by proposing an online solution for identifying and explaining spam reviews, incorporating data drift adaptation. It integrates (i) incremental profiling, (ii) data drift detection & adaptation, and (iii) identification of spam reviews employing Machine Learning. The explainable mechanism displays a visual and textual prediction explanation in a dashboard. The best results obtained reached up to 87 % spam F-measure.
Simulation, Modelling and Classification of Wiki Contributors: Spotting The Good, The Bad, and The Ugly
May 29, 2024
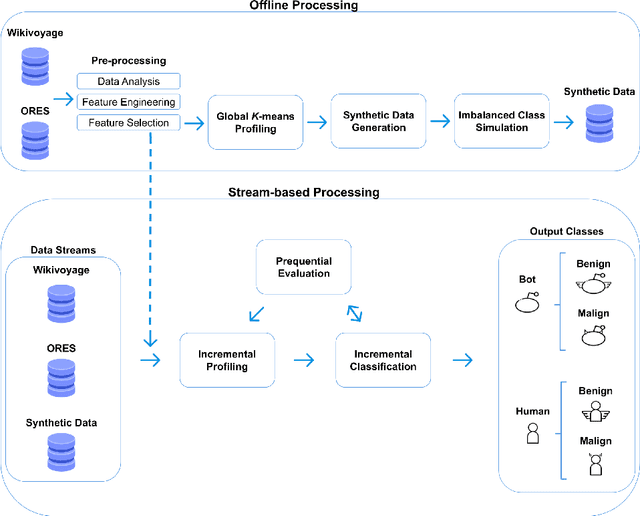


Data crowdsourcing is a data acquisition process where groups of voluntary contributors feed platforms with highly relevant data ranging from news, comments, and media to knowledge and classifications. It typically processes user-generated data streams to provide and refine popular services such as wikis, collaborative maps, e-commerce sites, and social networks. Nevertheless, this modus operandi raises severe concerns regarding ill-intentioned data manipulation in adversarial environments. This paper presents a simulation, modelling, and classification approach to automatically identify human and non-human (bots) as well as benign and malign contributors by using data fabrication to balance classes within experimental data sets, data stream modelling to build and update contributor profiles and, finally, autonomic data stream classification. By employing WikiVoyage - a free worldwide wiki travel guide open to contribution from the general public - as a testbed, our approach proves to significantly boost the confidence and quality of the classifier by using a class-balanced data stream, comprising both real and synthetic data. Our empirical results show that the proposed method distinguishes between benign and malign bots as well as human contributors with a classification accuracy of up to 92 %.
Interpretable classification of wiki-review streams
May 28, 2024Wiki articles are created and maintained by a crowd of editors, producing a continuous stream of reviews. Reviews can take the form of additions, reverts, or both. This crowdsourcing model is exposed to manipulation since neither reviews nor editors are automatically screened and purged. To protect articles against vandalism or damage, the stream of reviews can be mined to classify reviews and profile editors in real-time. The goal of this work is to anticipate and explain which reviews to revert. This way, editors are informed why their edits will be reverted. The proposed method employs stream-based processing, updating the profiling and classification models on each incoming event. The profiling uses side and content-based features employing Natural Language Processing, and editor profiles are incrementally updated based on their reviews. Since the proposed method relies on self-explainable classification algorithms, it is possible to understand why a review has been classified as a revert or a non-revert. In addition, this work contributes an algorithm for generating synthetic data for class balancing, making the final classification fairer. The proposed online method was tested with a real data set from Wikivoyage, which was balanced through the aforementioned synthetic data generation. The results attained near-90 % values for all evaluation metrics (accuracy, precision, recall, and F-measure).
Exposing and Explaining Fake News On-the-Fly
May 03, 2024Social media platforms enable the rapid dissemination and consumption of information. However, users instantly consume such content regardless of the reliability of the shared data. Consequently, the latter crowdsourcing model is exposed to manipulation. This work contributes with an explainable and online classification method to recognize fake news in real-time. The proposed method combines both unsupervised and supervised Machine Learning approaches with online created lexica. The profiling is built using creator-, content- and context-based features using Natural Language Processing techniques. The explainable classification mechanism displays in a dashboard the features selected for classification and the prediction confidence. The performance of the proposed solution has been validated with real data sets from Twitter and the results attain 80 % accuracy and macro F-measure. This proposal is the first to jointly provide data stream processing, profiling, classification and explainability. Ultimately, the proposed early detection, isolation and explanation of fake news contribute to increase the quality and trustworthiness of social media contents.