 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation, Modelling and Classification of Wiki Contributors: Spotting The Good, The Bad, and The Ugly
Paper and Code

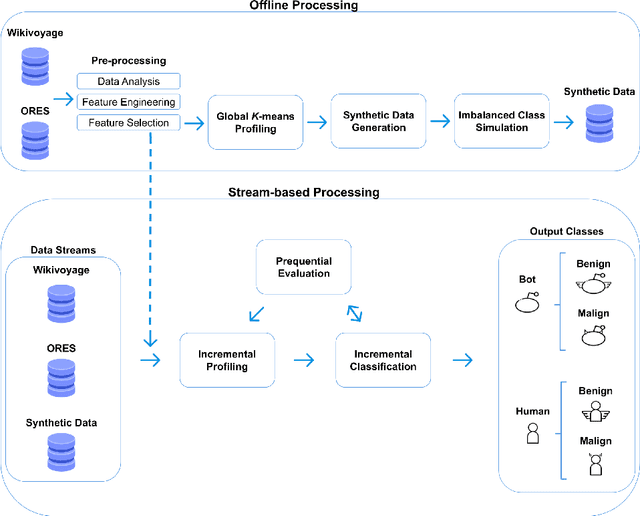


Data crowdsourcing is a data acquisition process where groups of voluntary contributors feed platforms with highly relevant data ranging from news, comments, and media to knowledge and classifications. It typically processes user-generated data streams to provide and refine popular services such as wikis, collaborative maps, e-commerce sites, and social networks. Nevertheless, this modus operandi raises severe concerns regarding ill-intentioned data manipulation in adversarial environments. This paper presents a simulation, modelling, and classification approach to automatically identify human and non-human (bots) as well as benign and malign contributors by using data fabrication to balance classes within experimental data sets, data stream modelling to build and update contributor profiles and, finally, autonomic data stream classification. By employing WikiVoyage - a free worldwide wiki travel guide open to contribution from the general public - as a testbed, our approach proves to significantly boost the confidence and quality of the classifier by using a class-balanced data stream, comprising both real and synthetic data. Our empirical results show that the proposed method distinguishes between benign and malign bots as well as human contributors with a classification accuracy of up to 92 %.