 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfusing Prompts with Syntax and Semantics
Dec 08, 2024Despite impressive success, language models often generate outputs with flawed linguistic structure. We analyze the effect of directly infusing various kinds of syntactic and semantic information into large language models. To demonstrate the value of our proposals, we focus on the translation of natural language queries to SQL, in particular dealing with languages with less resources than English, to better investigate how much help we can get from low cost syntactic and semantic information. We show that linguistic analysis can significantly boost language models, to the point that we have surpassed previous best systems.
Assessing Good, Bad and Ugly Arguments Generated by ChatGPT: a New Dataset, its Methodology and Associated Tasks
Jun 21, 2024The recent success of Large Language Models (LLMs) has sparked concerns about their potential to spread misinformation. As a result, there is a pressing need for tools to identify ``fake arguments'' generated by such models. To create these tools, examples of texts generated by LLMs are needed. This paper introduces a methodology to obtain good, bad and ugly arguments from argumentative essays produced by ChatGPT, OpenAI's LLM. We then describe a novel dataset containing a set of diverse arguments, ArGPT. We assess the effectiveness of our dataset and establish baselines for several argumentation-related tasks. Finally, we show that the artificially generated data relates well to human argumentation and thus is useful as a tool to train and test systems for the defined tasks.
dPASP: A Comprehensive Differentiable Probabilistic Answer Set Programming Environment For Neurosymbolic Learning and Reasoning
Aug 05, 2023

We present dPASP, a novel declarative probabilistic logic programming framework for differentiable neuro-symbolic reasoning. The framework allows for the specification of discrete probabilistic models with neural predicates, logic constraints and interval-valued probabilistic choices, thus supporting models that combine low-level perception (images, texts, etc), common-sense reasoning, and (vague) statistical knowledge. To support all such features, we discuss the several semantics for probabilistic logic programs that can express nondeterministic, contradictory, incomplete and/or statistical knowledge. We also discuss how gradient-based learning can be performed with neural predicates and probabilistic choices under selected semantics. We then describe an implemented package that supports inference and learning in the language, along with several example programs. The package requires minimal user knowledge of deep learning system's inner workings, while allowing end-to-end training of rather sophisticated models and loss functions.
A Multilingual Translator to SQL with Database Schema Pruning to Improve Self-Attention
Jun 25, 2023Long sequences of text are challenging in the context of transformers, due to quadratic memory increase in the self-attention mechanism. As this issue directly affects the translation from natural language to SQL queries (as techniques usually take as input a concatenated text with the question and the database schema), we present techniques that allow long text sequences to be handled by transformers with up to 512 input tokens. We propose a training process with database schema pruning (removal of tables and columns names that are useless for the query of interest). In addition, we used a multilingual approach with the mT5-large model fine-tuned with a data-augmented Spider dataset in four languages simultaneously: English, Portuguese, Spanish, and French. Our proposed technique used the Spider dataset and increased the exact set match accuracy results from 0.718 to 0.736 in a validation dataset (Dev). Source code, evaluations, and checkpoints are available at: \underline{https://github.com/C4AI/gap-text2sql}.
Markov Conditions and Factorization in Logical Credal Networks
Mar 17, 2023We examine the recently proposed language of Logical Credal Networks, in particular investigating the consequences of various Markov conditions. We introduce the notion of structure for a Logical Credal Network and show that a structure without directed cycles leads to a well-known factorization result. For networks with directed cycles, we analyze the differences between Markov conditions, factorization results, and specification requirements.
Augmenting a Physics-Informed Neural Network for the 2D Burgers Equation by Addition of Solution Data Points
Jan 18, 2023We implement a Physics-Informed Neural Network (PINN) for solving the two-dimensional Burgers equations. This type of model can be trained with no previous knowledge of the solution; instead, it relies on evaluating the governing equations of the system in points of the physical domain. It is also possible to use points with a known solution during training. In this paper, we compare PINNs trained with different amounts of governing equation evaluation points and known solution points. Comparing models that were trained purely with known solution points to those that have also used the governing equations, we observe an improvement in the overall observance of the underlying physics in the latter. We also investigate how changing the number of each type of point affects the resulting models differently. Finally, we argue that the addition of the governing equations during training may provide a way to improve the overall performance of the model without relying on additional data, which is especially important for situations where the number of known solution points is limited.
* This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this contribution is published in the Lecture Notes in Computer Science book series (LNAI,volume 13654), and is available online at https://doi.org/10.1007/978-3-031-21689-3_28
mRAT-SQL+GAP:A Portuguese Text-to-SQL Transformer
Oct 07, 2021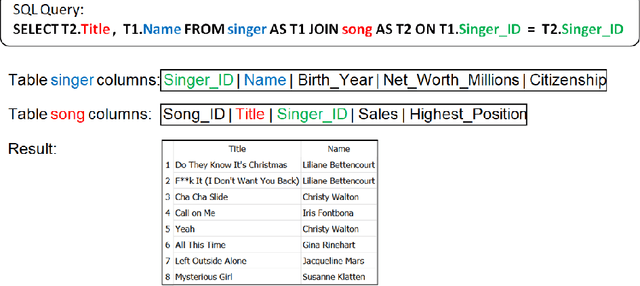


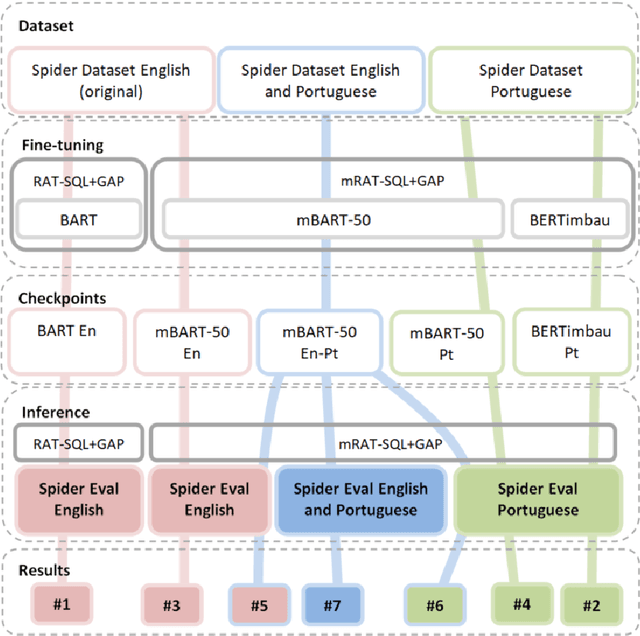
The translation of natural language questions to SQL queries has attracted growing attention, in particular in connection with transformers and similar language models. A large number of techniques are geared towards the English language; in this work, we thus investigated translation to SQL when input questions are given in the Portuguese language. To do so, we properly adapted state-of-the-art tools and resources. We changed the RAT-SQL+GAP system by relying on a multilingual BART model (we report tests with other language models), and we produced a translated version of the Spider dataset. Our experiments expose interesting phenomena that arise when non-English languages are targeted; in particular, it is better to train with original and translated training datasets together, even if a single target language is desired. This multilingual BART model fine-tuned with a double-size training dataset (English and Portuguese) achieved 83% of the baseline, making inferences for the Portuguese test dataset. This investigation can help other researchers to produce results in Machine Learning in a language different from English. Our multilingual ready version of RAT-SQL+GAP and the data are available, open-sourced as mRAT-SQL+GAP at: https://github.com/C4AI/gap-text2sql
An Empirical Accuracy Law for Sequential Machine Translation: the Case of Google Translate
Apr 08, 2020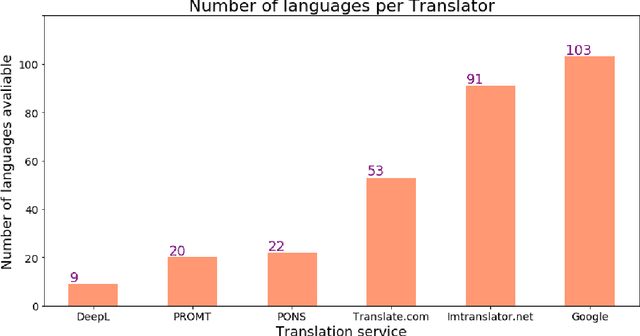
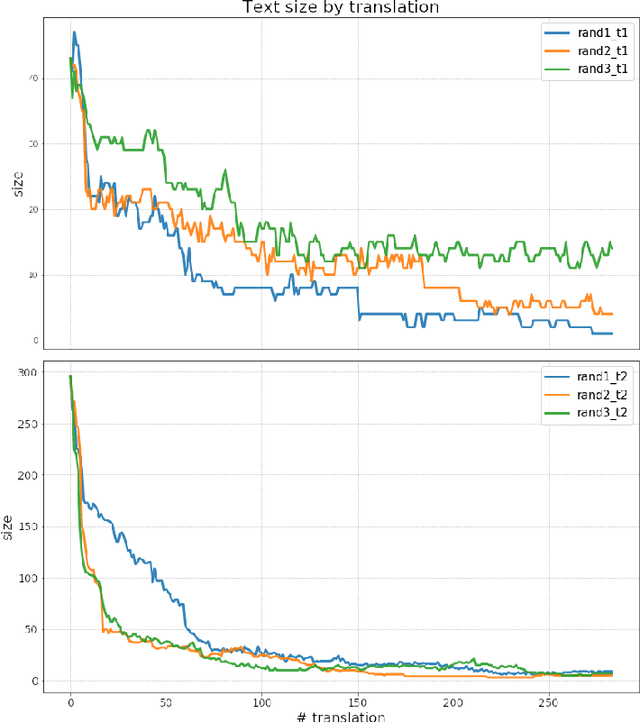
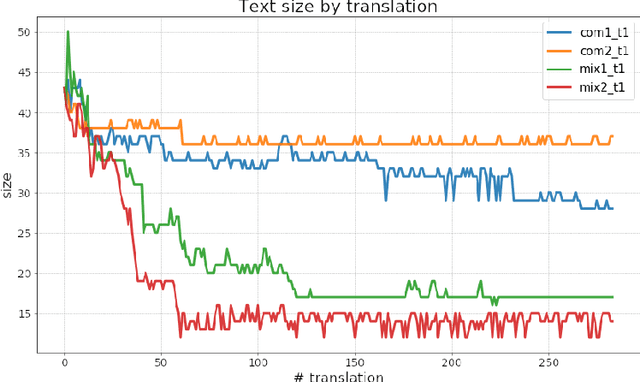
In this research, we have established, through empirical testing, a law that relates the number of translating hops to translation accuracy in sequential machine translation in Google Translate. Both accuracy and size decrease with the number of hops; the former displays a decrease closely following a power law. Such a law allows one to predict the behavior of translation chains that may be built as society increasingly depends on automated devices.
A Fully Attention-Based Information Retriever
Oct 22, 2018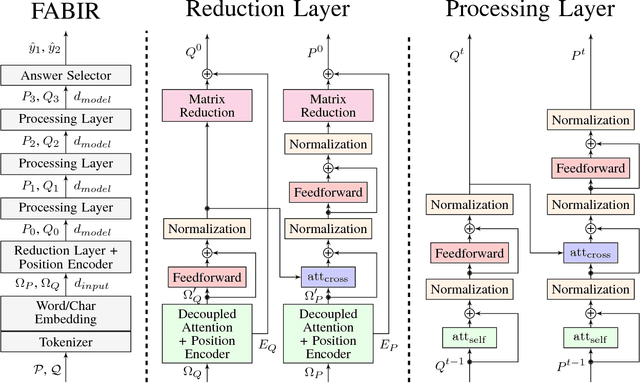
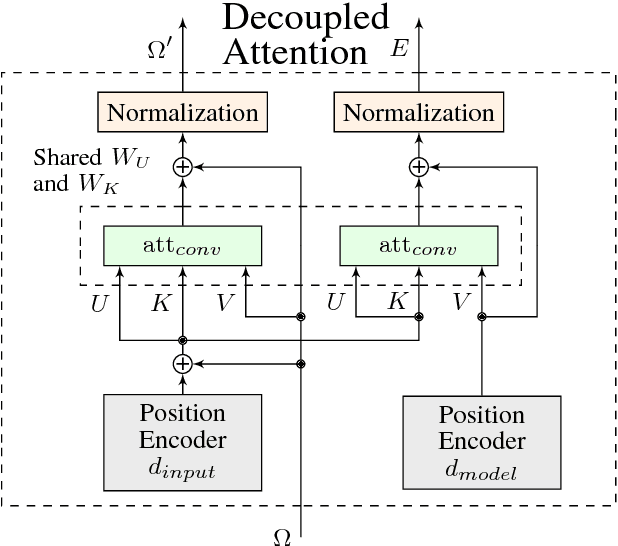
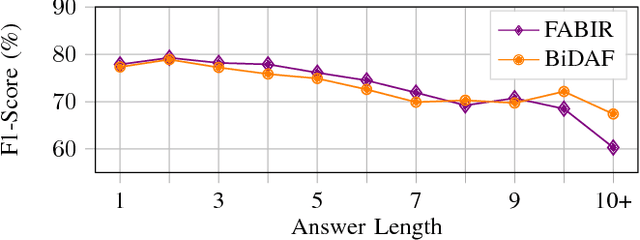
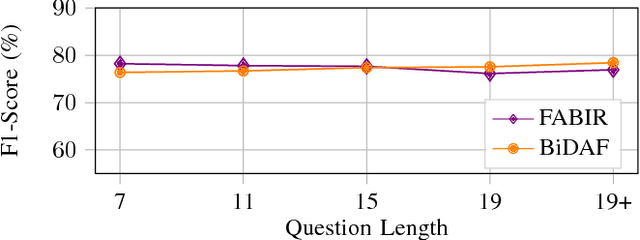
Recurrent neural networks are now the state-of-the-art in natural language processing because they can build rich contextual representations and process texts of arbitrary length. However, recent developments on attention mechanisms have equipped feedforward networks with similar capabilities, hence enabling faster computations due to the increase in the number of operations that can be parallelized. We explore this new type of architecture in the domain of question-answering and propose a novel approach that we call Fully Attention Based Information Retriever (FABIR). We show that FABIR achieves competitive results in the Stanford Question Answering Dataset (SQuAD) while having fewer parameters and being faster at both learning and inference than rival methods.
* Accepted for presentation at the International Joint Conference on Neural Networks (IJCNN) 2018
Interpreting Embedding Models of Knowledge Bases: A Pedagogical Approach
Jun 20, 2018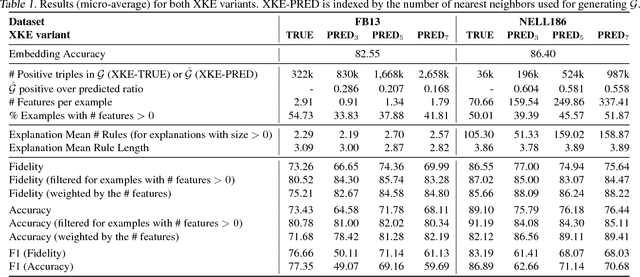
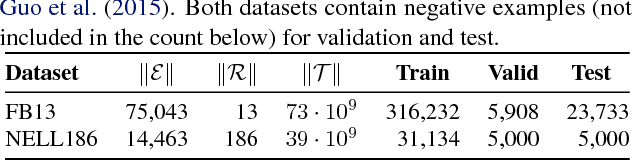
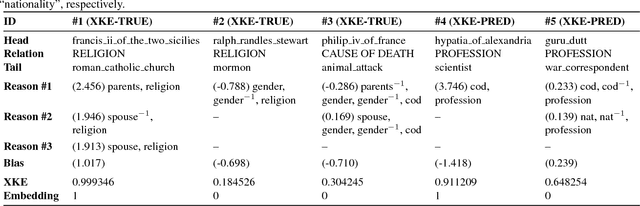

Knowledge bases are employed in a variety of applications from natural language processing to semantic web search; alas, in practice their usefulness is hurt by their incompleteness. Embedding models attain state-of-the-art accuracy in knowledge base completion, but their predictions are notoriously hard to interpret. In this paper, we adapt "pedagogical approaches" (from the literature on neural networks) so as to interpret embedding models by extracting weighted Horn rules from them. We show how pedagogical approaches have to be adapted to take upon the large-scale relational aspects of knowledge bases and show experimentally their strengths and weaknesses.