 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fully Attention-Based Information Retriever
Oct 22, 2018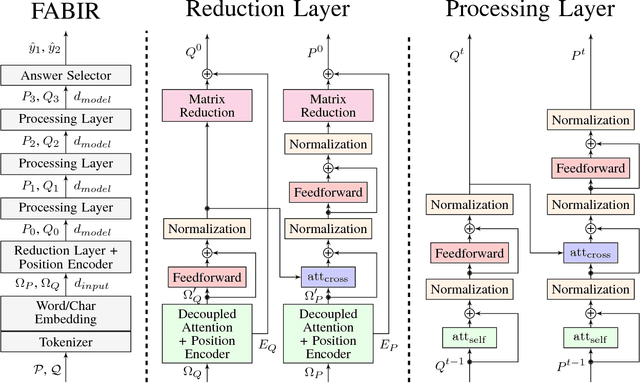
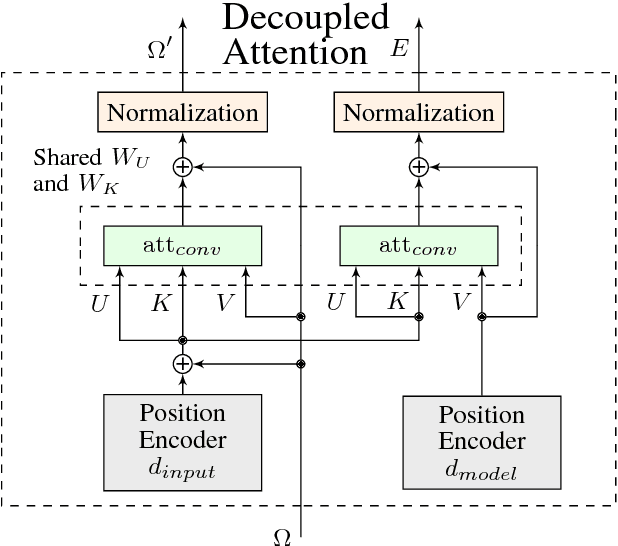
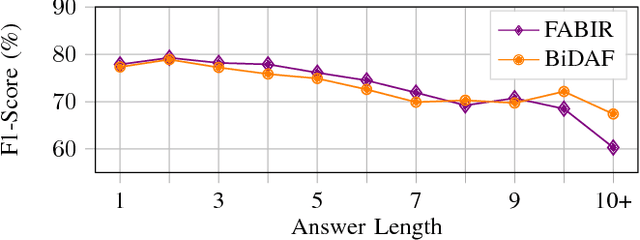
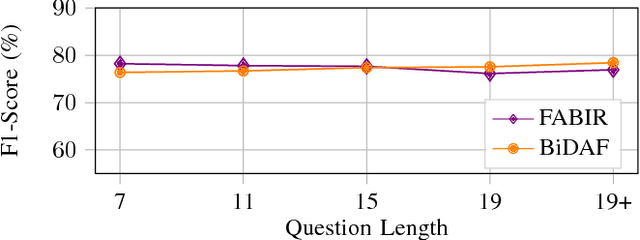
Recurrent neural networks are now the state-of-the-art in natural language processing because they can build rich contextual representations and process texts of arbitrary length. However, recent developments on attention mechanisms have equipped feedforward networks with similar capabilities, hence enabling faster computations due to the increase in the number of operations that can be parallelized. We explore this new type of architecture in the domain of question-answering and propose a novel approach that we call Fully Attention Based Information Retriever (FABIR). We show that FABIR achieves competitive results in the Stanford Question Answering Dataset (SQuAD) while having fewer parameters and being faster at both learning and inference than rival methods.
* Accepted for presentation at the International Joint Conference on Neural Networks (IJCNN) 2018
Interpreting Embedding Models of Knowledge Bases: A Pedagogical Approach
Jun 20, 2018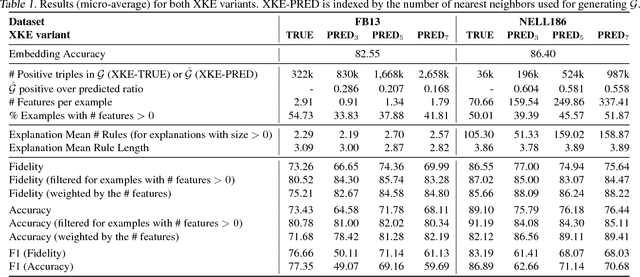
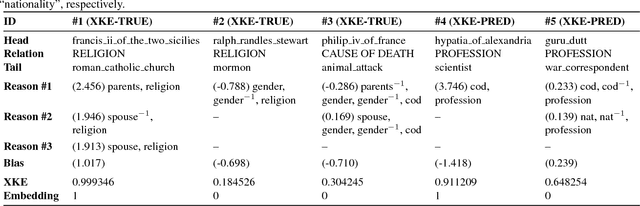

Knowledge bases are employed in a variety of applications from natural language processing to semantic web search; alas, in practice their usefulness is hurt by their incompleteness. Embedding models attain state-of-the-art accuracy in knowledge base completion, but their predictions are notoriously hard to interpret. In this paper, we adapt "pedagogical approaches" (from the literature on neural networks) so as to interpret embedding models by extracting weighted Horn rules from them. We show how pedagogical approaches have to be adapted to take upon the large-scale relational aspects of knowledge bases and show experimentally their strengths and weaknesses.