 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinctive Image Captioning: Leveraging Ground Truth Captions in CLIP Guided Reinforcement Learning
Feb 21, 2024
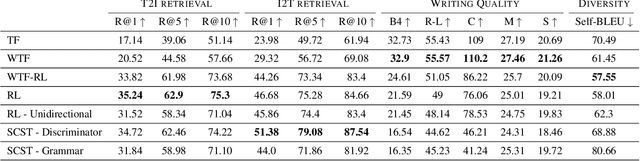
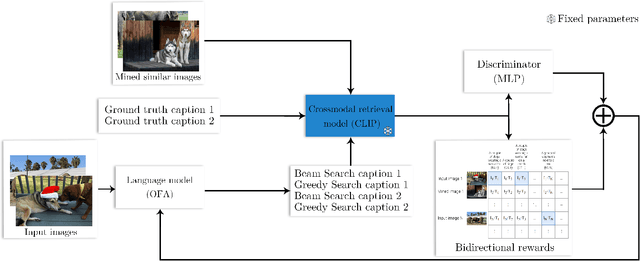
Training image captioning models using teacher forcing results in very generic samples, whereas more distinctive captions can be very useful in retrieval applications or to produce alternative texts describing images for accessibility. Reinforcement Learning (RL) allows to use cross-modal retrieval similarity score between the generated caption and the input image as reward to guide the training, leading to more distinctive captions. Recent studies show that pre-trained cross-modal retrieval models can be used to provide this reward, completely eliminating the need for reference captions. However, we argue in this paper that Ground Truth (GT) captions can still be useful in this RL framework. We propose a new image captioning model training strategy that makes use of GT captions in different ways. Firstly, they can be used to train a simple MLP discriminator that serves as a regularization to prevent reward hacking and ensures the fluency of generated captions, resulting in a textual GAN setup extended for multimodal inputs. Secondly, they can serve as additional trajectories in the RL strategy, resulting in a teacher forcing loss weighted by the similarity of the GT to the image. This objective acts as an additional learning signal grounded to the distribution of the GT captions. Thirdly, they can serve as strong baselines when added to the pool of captions used to compute the proposed contrastive reward to reduce the variance of gradient estimate. Experiments on MS-COCO demonstrate the interest of the proposed training strategy to produce highly distinctive captions while maintaining high writing quality.
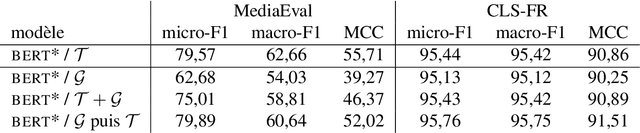
Measuring vagueness and subjectivity in texts: from symbolic to neural VAGO
Sep 12, 2023



We present a hybrid approach to the automated measurement of vagueness and subjectivity in texts. We first introduce the expert system VAGO, we illustrate it on a small benchmark of fact vs. opinion sentences, and then test it on the larger French press corpus FreSaDa to confirm the higher prevalence of subjective markers in satirical vs. regular texts. We then build a neural clone of VAGO, based on a BERT-like architecture, trained on the symbolic VAGO scores obtained on FreSaDa. Using explainability tools (LIME), we show the interest of this neural version for the enrichment of the lexicons of the symbolic version, and for the production of versions in other languages.
Which Discriminator for Cooperative Text Generation?
Apr 25, 2022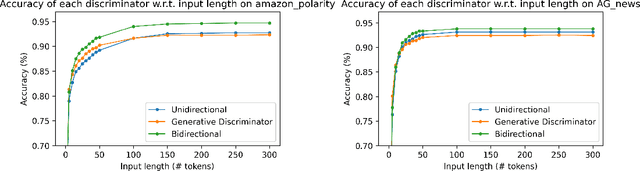

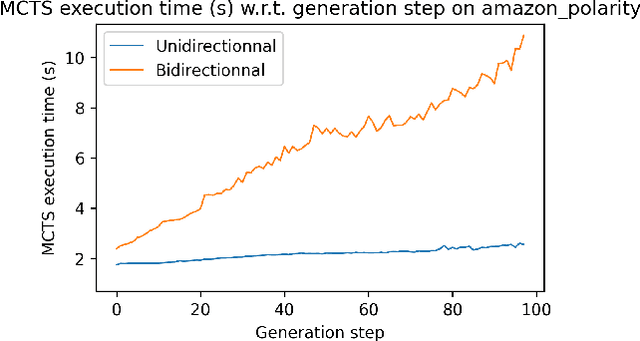
Language models generate texts by successively predicting probability distributions for next tokens given past ones. A growing field of interest tries to leverage external information in the decoding process so that the generated texts have desired properties, such as being more natural, non toxic, faithful, or having a specific writing style. A solution is to use a classifier at each generation step, resulting in a cooperative environment where the classifier guides the decoding of the language model distribution towards relevant texts for the task at hand. In this paper, we examine three families of (transformer-based) discriminators for this specific task of cooperative decoding: bidirectional, left-to-right and generative ones. We evaluate the pros and cons of these different types of discriminators for cooperative generation, exploring respective accuracy on classification tasks along with their impact on the resulting sample quality and computational performances. We also provide the code of a batched implementation of the powerful cooperative decoding strategy used for our experiments, the Monte Carlo Tree Search, working with each discriminator for Natural Language Generation.
Generative Cooperative Networks for Natural Language Generation
Jan 28, 2022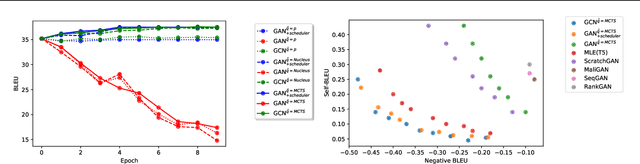
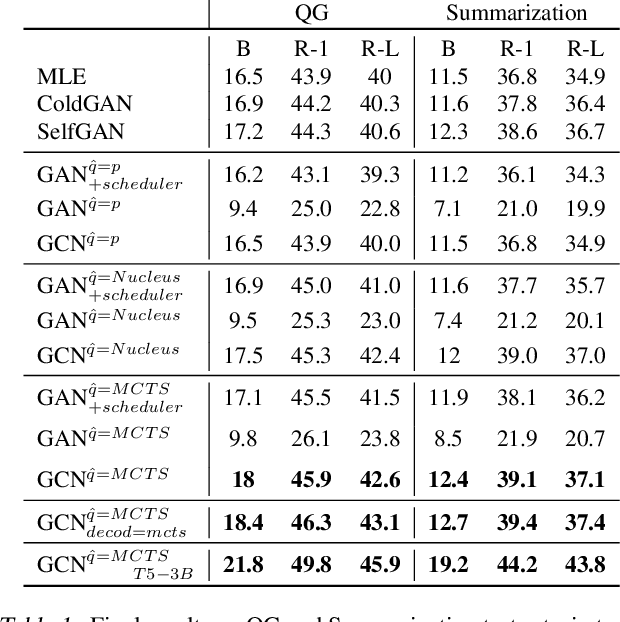
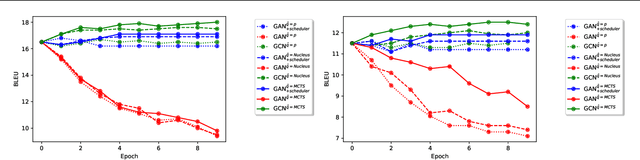
Generative Adversarial Networks (GANs) have known a tremendous success for many continuous generation tasks, especially in the field of image generation. However, for discrete outputs such as language, optimizing GANs remains an open problem with many instabilities, as no gradient can be properly back-propagated from the discriminator output to the generator parameters. An alternative is to learn the generator network via reinforcement learning, using the discriminator signal as a reward, but such a technique suffers from moving rewards and vanishing gradient problems. Finally, it often falls short compared to direct maximum-likelihood approaches. In this paper, we introduce Generative Cooperative Networks, in which the discriminator architecture is cooperatively used along with the generation policy to output samples of realistic texts for the task at hand. We give theoretical guarantees of convergence for our approach, and study various efficient decoding schemes to empirically achieve state-of-the-art results in two main NLG tasks.
Generating artificial texts as substitution or complement of training data
Oct 25, 2021

The quality of artificially generated texts has considerably improved with the advent of transformers. The question of using these models to generate learning data for supervised learning tasks naturally arises. In this article, this question is explored under 3 aspects: (i) are artificial data an efficient complement? (ii) can they replace the original data when those are not available or cannot be distributed for confidentiality reasons? (iii) can they improve the explainability of classifiers? Different experiments are carried out on Web-related classification tasks -- namely sentiment analysis on product reviews and Fake News detection -- using artificially generated data by fine-tuned GPT-2 models. The results show that such artificial data can be used in a certain extend but require pre-processing to significantly improve performance. We show that bag-of-word approaches benefit the most from such data augmentation.
Generating texts under constraint through discriminator-guided MCTS
Sep 28, 2021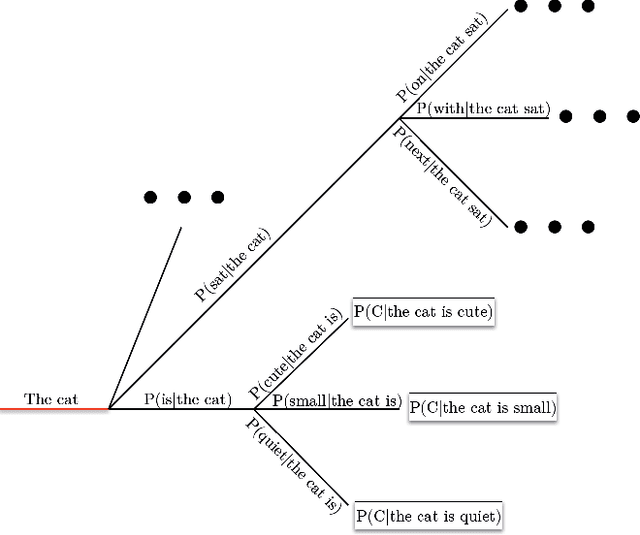
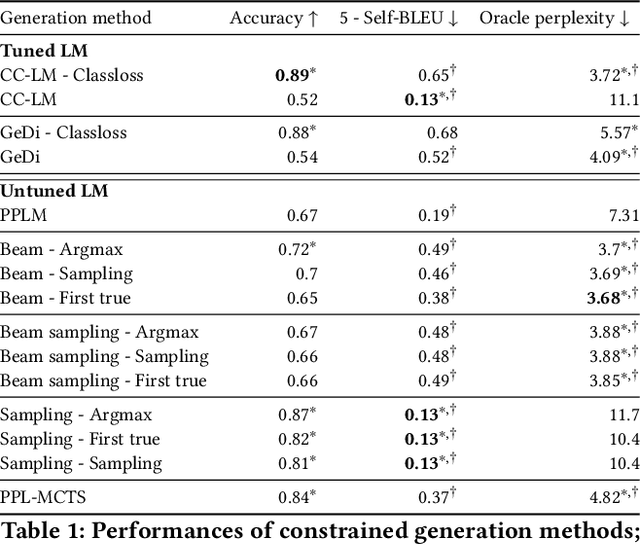
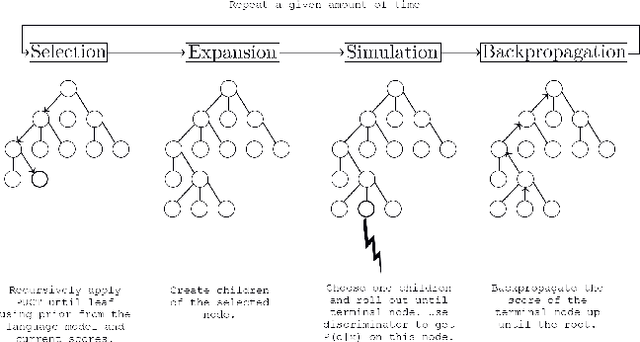
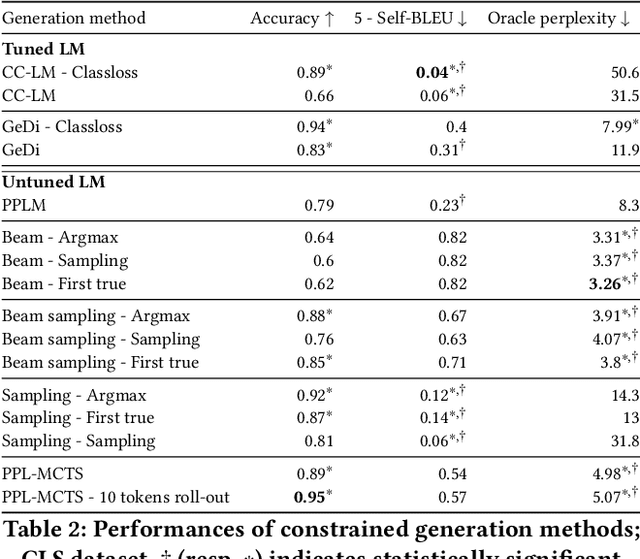
Large pre-trained language models (LM) based on Transformers allow to generate very plausible long texts. In this paper, we explore how this generation can be further controlled to satisfy certain constraints (eg. being non-toxic, positive or negative, convey certain emotions, etc.) without fine-tuning the LM. Precisely, we formalize constrained generation as a tree exploration process guided by a discriminator according to how well the associated sequence respects the constraint. Using a discriminator to guide this generation, rather than fine-tuning the LM, in addition to be easier and cheaper to train, allows to apply the constraint more finely and dynamically. We propose several original methods to search this generation tree, notably the Monte Carlo Tree Search (MCTS) which provides theoretical guarantees on the search efficiency, but also simpler methods based on re-ranking a pool of diverse sequences using the discriminator scores. We evaluate these methods on two types of constraints and languages: review polarity and emotion control in French and English. We show that MCTS achieves state-of-the-art results in constrained generation, without having to tune the language model, in both tasks and languages. We also demonstrate that our other proposed methods based on re-ranking can be really effective when diversity among the generated propositions is encouraged.